Semantic layer vs. semantic execution layer at a glance
| Capability | Semantic layer | Semantic execution layer (Colrows) |
|---|---|---|
| When SQL is resolved | At runtime, per query | At compile time, before any query runs |
| Governance enforcement | Post-query filter or advisory | RBAC, ABAC, RLS, CLS baked in at compile time |
| SQL dialect support | Single engine or best-effort translation | Dialect-perfect SQL across 16+ engines |
| Join path validation | Assumed, errors surface at runtime | Join path proofs at compile time, errors caught early |
| Audit and lineage | Manual or partial | Full lineage trail on every compiled artifact |
| Schema drift detection | Manual updates required | Autonomous drift detection built in |
If you are building AI-powered analytics on top of your data warehouse, this distinction is not academic. It determines whether your AI returns a correct, governed, auditable answer or a confident hallucination dressed up as business intelligence.
Let us break both concepts down clearly, with simple analogies, and then show you exactly where each one belongs.
What is a semantic layer?
A semantic layer is a translation tier that sits between your raw database tables and the tools that consume them. Its job is to map technical column names like ord_amnt_usd into human-readable concepts like “Revenue,” and to store the calculation logic for your key business metrics in one place rather than scattered across dozens of SQL scripts and dashboards.
The idea is about 35 years old. Business Objects invented it in 1990 with a concept called the “universe,” a business-friendly shell over relational databases. Cognos, Hyperion, and MicroStrategy followed with their own versions. Looker modernised the concept in 2012 with LookML, which put metric definitions into code. Today, dbt’s Semantic Layer (MetricFlow), Cube, AtScale, and Snowflake’s native Semantic Views all carry on the same tradition.
The core value proposition has not changed: one definition of “Revenue,” everywhere. No more arguments about whose number is right.
Think of a semantic layer as a recipe book. It tells you exactly what goes into every dish. The ingredients are defined. The measurements are written down. But when someone orders a meal, the kitchen still has to read the recipe, gather the ingredients, and cook it from scratch. Every single time.
That is the core characteristic of a semantic layer: it resolves at runtime. When a business user or an AI agent asks “What was our revenue last quarter?”, the semantic layer reads its metric definition, builds the SQL query on the fly, and sends it to the warehouse. This happens per query, for every query.
Where a semantic layer excels
A semantic layer is the right tool when your primary goal is consistent metric definitions across BI tools. If your problem is “Power BI shows 12 million and Tableau shows 14 million for the same revenue figure,” a semantic layer solves that. It gives both tools a single source of truth to draw from.
It is well suited for organisations with a relatively small number of BI platforms, a stable data schema, and human analysts as the primary consumers. It is a genuine improvement over having metric definitions scattered across dozens of dashboards with no central authority.
Where a semantic layer struggles
Runtime resolution creates a set of constraints that become painful at scale, and almost untenable the moment AI agents enter the picture.
First, governance is evaluated after the query is built. Access controls are typically applied as filters on the result, which means the query has already been formed and sent to the warehouse. An auditor reviewing a compliance breach cannot point to a static, pre-inspectable SQL artifact. The query was constructed dynamically and is gone.
Second, SQL dialect errors surface at execution time. If your semantic layer generates a query meant for Snowflake but you are running it on Redshift, syntax differences (QUALIFY clauses, TIMESTAMPDIFF signatures, LATERAL FLATTEN) can produce silent errors or wrong results. The problem is only discovered when someone notices the number is wrong.
Third, AI agents querying a runtime semantic layer still have to guess. The agent must figure out the right metric, the right join path, and the right filter at query time. This is exactly where hallucinations originate. The BEAVER benchmark (arXiv:2409.02038), which tested leading AI models against real enterprise data warehouses, found accuracy rates close to zero for off-the-shelf models working without governed semantic context. Even the strongest agentic method achieved just 11.4% accuracy on real enterprise schemas.
What is a semantic execution layer?
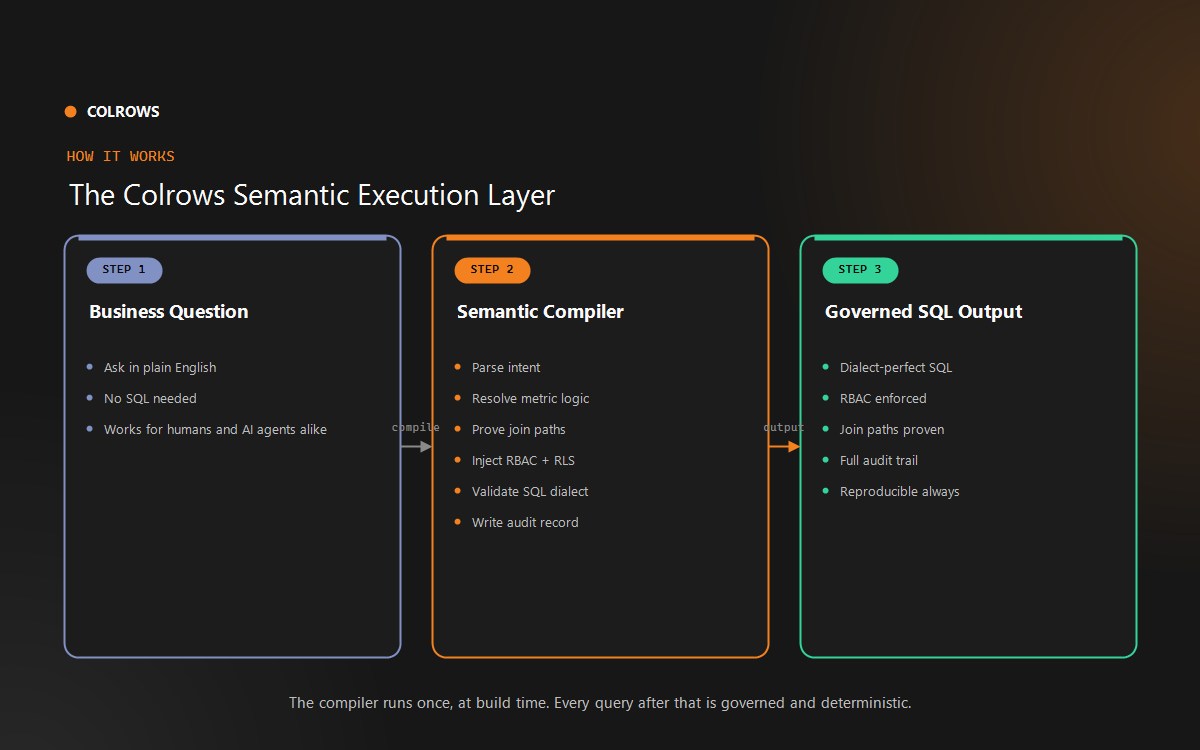
A semantic execution layer takes everything a semantic layer defines and resolves it before any query reaches the warehouse. It functions as a compiler for your business logic.
The architectural shift is from definition at rest to compiled execution. The system does not wait for a query to arrive and then figure out the SQL. It works through all the business logic, join paths, governance rules, and dialect requirements upfront, at compile time, and produces a validated, governed SQL artifact that is ready to execute.
If a semantic layer is a recipe book, a semantic execution layer is a professional kitchen that has already done all the prep. The vegetables are cut. The sauces are made. The portions are measured. When the order comes in, the dish is assembled and plated in seconds, and it comes out identical every single time. No improvisation. No runtime guesswork. No chance of a chef misreading the recipe under pressure.
For those who think in software engineering terms: this is the difference between a compiler and an interpreter. An interpreter (like Python) reads and executes code line by line at runtime. A compiler (like C++) converts the entire program into machine-ready output at build time, catching errors before execution and producing fast, deterministic results. A semantic execution layer is the compiler for your business metrics.
What happens at compile time
When Colrows compiles a business metric, six things happen before a single query touches your warehouse:
1. Business intent is parsed. The system reads the semantic graph and identifies which metric, dimensions, and filters apply.
2. Metric logic is resolved. “Revenue” becomes the precise calculation: SUM of order amounts where status equals completed, scoped to the correct time grain.
3. Join paths are proven. The compiler does not assume joins are valid. It mathematically proves that every join in the generated SQL is semantically correct. If no valid path exists, compilation fails and an explicit error is returned. Nothing ambiguous makes it through.
4. Governance predicates are injected. Row-level security, column-level security, RBAC, and ABAC rules are compiled directly into the SQL. Unauthorised intent causes compilation to fail. The restricted data is never read. This is not a post-query filter. It is pre-execution enforcement.
5. Dialect-perfect SQL is emitted. The system generates SQL validated against the grammar and type system of the specific target engine: Snowflake, BigQuery, Databricks, Redshift, and 13 more. No runtime dialect guessing.
6. An audit record is written. Every compiled artifact is traceable: which version of the semantic graph generated it, which identity triggered it, which entities were resolved, which joins were proven, and the exact SQL produced. Point-in-time reproducibility is built in.
Four use cases where the difference is decisive
Regulated industries: BFSI, pharma, healthcare
A compliance auditor cannot inspect a dynamically generated query. They need a static, reproducible artifact. Compile-time governance produces exactly that: a SQL artifact the auditor can read, trace to its business definition, and reproduce identically for any historical point in time. Runtime layers cannot make this guarantee.
Multi-engine data stacks
Most large enterprises run Snowflake alongside BigQuery or Databricks. SQL dialects differ in meaningful ways. A runtime layer generates best-effort SQL and hopes for compatibility. A compile-time execution layer pre-validates every SQL fragment against the target engine before the query ever runs.
AI agents and copilots
An AI agent querying a runtime layer must still resolve the right metric, the right join, and the right filter in the moment. This is where hallucinations are born. An agent calling a compiled execution layer receives a pre-validated, governance-enforced SQL fragment. There is no guessing.
Cost-sensitive deployments
Every runtime LLM call adds latency and token cost. Google Cloud engineering research put LLM-mediated SQL resolution at roughly 1000x the cost of direct query execution. Compile-once, run-many eliminates this. The expensive reasoning is done once at compile time and amortised across every subsequent query.
A concrete example to make it real
Say a finance team needs to know: “What is our net revenue by product category for Q2, excluding returns, for users in my region only?”
With a semantic layer: the tool receives this question, identifies the relevant metrics and dimensions, builds the SQL dynamically, applies a post-query row filter for the user’s region, and sends it to the warehouse. If the schema changed last week, if the join path is now ambiguous, or if the dialect is slightly off for this engine, the error surfaces at execution time. If the row filter is mis-applied, the user may see data they should not.
With a semantic execution layer: the moment the business metric “Net Revenue” was last modified in the semantic graph, the compiler ran. It resolved the calculation (gross revenue minus returns, at the correct grain), proved the join path from transactions to product categories, injected the row-level predicate for regional access into the SQL itself, validated the syntax against the target dialect, and wrote the compiled artifact to the audit log. When the query arrives at runtime, the warehouse executes a pre-validated, governance-enforced SQL statement. The user cannot receive data outside their region. The auditor can inspect the compiled artifact and reproduce it identically tomorrow.
Same business question. Fundamentally different architecture.
Why this matters more as AI enters the stack
The difference between a semantic layer and a semantic execution layer was manageable when human analysts were the primary consumers. Analysts can catch a wrong number. They know the context. They will escalate if something looks off.
AI agents do not work that way. An agent generating SQL from natural language against raw tables or a runtime semantic layer has to figure out business logic, join paths, and governance rules on the fly. The academic benchmarks are clear about what happens next.
These are not models failing because they are unintelligent. They fail because the business context is not compiled into the system they are querying. The research from dbt Labs (April 2026) confirmed this directly: when the same AI models were given access to a governed semantic layer rather than raw schema, GPT accuracy jumped from 84% to 100%. Claude Sonnet went from 90% to 98%.
The problem was never the model. It was the context around it.
The biggest gains in AI analytics accuracy do not come from a better model. They come from giving the model governed, compiled, unambiguous business context before it ever generates a query. That is the job of a semantic execution layer.
The emerging standard for enterprise AI data architecture
The data industry has spent three decades refining the semantic layer. dbt, Cube, AtScale, and Looker have all made it better, more accessible, and more connected to the modern data stack.
But the arrival of AI agents, stricter data governance mandates, and multi-engine enterprise stacks has exposed a structural ceiling in runtime resolution. The industry’s response has been to move the point of resolution earlier, closer to the business definition, and make it deterministic rather than probabilistic.
Gartner’s 2026 analysis projects that organisations that prioritise governed semantic layers for AI will increase agentic AI accuracy by up to 80% and reduce total AI costs by up to 60% by 2027. The Open Semantic Interchange initiative, launched by Snowflake with dbt Labs, Salesforce, Cube, and others in September 2025, underlines how seriously the industry is moving toward standardised, governed semantic specifications at the infrastructure level.
Compile-time resolution is where enterprise AI data architecture is heading. The semantic execution layer is that architecture, available today. See how Colrows implements this across the full semantic execution layer architecture, including compile-time RBAC, autonomous graph maintenance, and MCP integration for AI agents. For a deeper look at where semantic layers fall short specifically for AI agents, see Why Current Tools Fall Short; for how this layer relates to knowledge graphs, see Semantic Layer vs. Knowledge Graph.
Frequently asked questions
What is the difference between a semantic layer and a semantic execution layer?
A semantic layer resolves business logic into SQL at runtime, per query. A semantic execution layer compiles business logic, join paths, governance rules, and dialect requirements upfront, at compile time, producing a validated, governed SQL artifact before any query touches the warehouse.
Why does compile-time governance matter for AI agents?
AI agents querying a runtime semantic layer must still guess the right metric, join path, and filter at query time - exactly where hallucinations originate. The BEAVER benchmark found the strongest agentic method achieved just 11.4% accuracy on real enterprise schemas. dbt Labs’ April 2026 research found that giving the same models governed semantic context lifted GPT accuracy from 84% to 100% and Claude Sonnet from 90% to 98%.
Does a semantic execution layer replace my existing semantic layer?
Not necessarily. Many enterprises keep a semantic layer (dbt, Cube, AtScale, Looker) for consistent metric definitions across BI tools, and add a compile-time execution layer in front of AI agents and governed, multi-engine, audit-sensitive workloads where runtime resolution is not sufficient.
Colrows builds the Autonomous Semantic Layer for enterprise AI.
Fix the Context. Not the Model.
Start the conversation: engage@colrows.com · colrows.com


