The accuracy cliff, at a glance
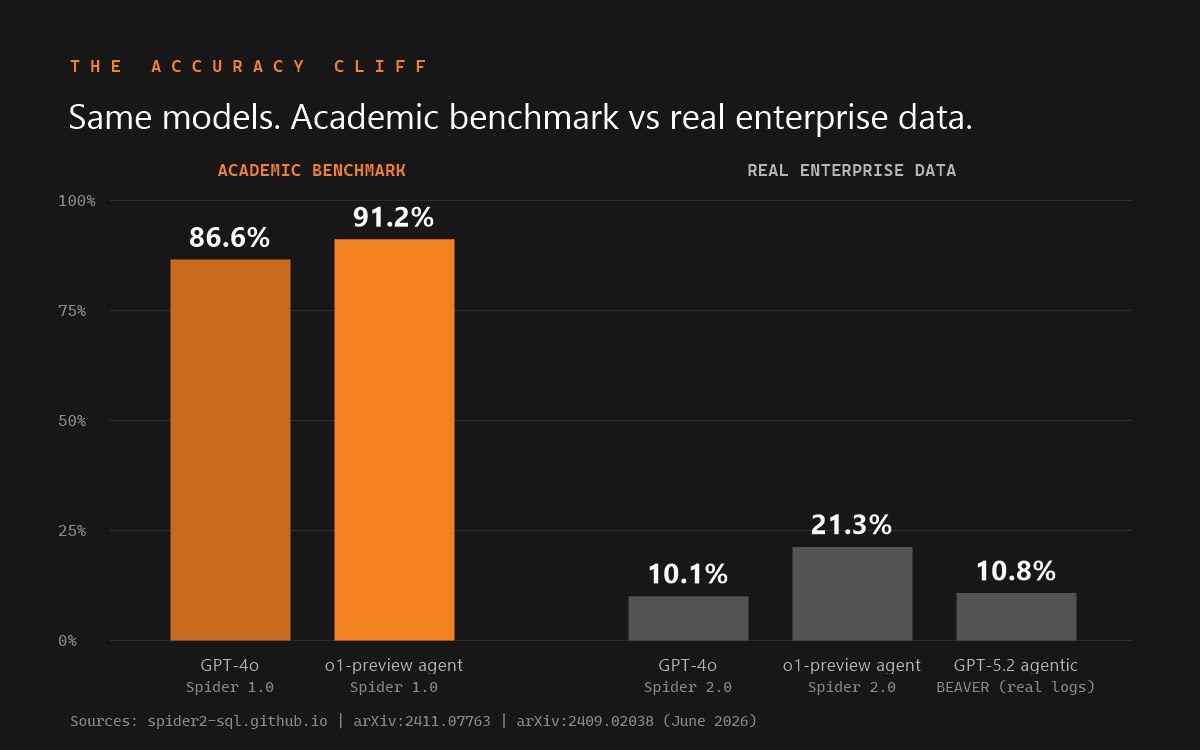
Best-published-result accuracy on each benchmark, using strong code-agent frameworks or off-the-shelf LLMs as noted. Higher is better.
The benchmark table
| Benchmark | Best result | System / model | What it tests | Source |
|---|---|---|---|---|
| Spider 1.0 | 91.2% | o1-preview code-agent framework | Cross-domain academic schemas, small and clean | Lei et al., Spider 2.0 paper (arXiv:2411.07763) |
| BIRD | 73.0% | o1-preview code-agent framework | Larger, dirtier databases with values and evidence | Reported in Spider 2.0 paper; BIRD, NeurIPS 2023 |
| Spider 2.0 | 21.3% | o1-preview code-agent framework | 632 real enterprise workflows; schemas averaging ~800 columns | Lei et al., ICLR 2025 (arXiv:2411.07763) |
| BEAVER | ~0% (end-to-end) | Off-the-shelf GPT-4o, Llama3-70B-Instruct | Real private enterprise data-warehouse queries | BEAVER enterprise benchmark |
| Vendor internal (context) | 90%+ | Cortex Analyst on a curated semantic model | Snowflake internal 150-question set (not independent) | Snowflake engineering blog |
The bottom row matters for reading the rest: a curated semantic model lifts a Snowflake-internal set to 90%+, while the same class of single-shot LLM sat at 51% on that set. That is the whole thesis in one line: the semantic model does the work, not the raw model.
How to read these numbers
- Academic benchmarks flatter models. Spider 1.0's schemas are small and clean. Real warehouses are not. The 91.2%-to-21.3% drop from Spider 1.0 to Spider 2.0 is the same class of system on realistic data.
- Enterprise schemas are the hard part. Spider 2.0 databases average roughly 800 columns. Ambiguous names, undocumented joins, and governance rules are the real difficulty, not SQL syntax.
- Off-the-shelf LLMs collapse on private data. BEAVER found near-0% end-to-end accuracy for GPT-4o and Llama3-70B on real warehouse data.
- Curated context is the lever. Every result above the raw baseline comes from better grounding, a semantic model, not a bigger LLM.
Fix the Context, Not the Model. The benchmarks say it plainly: accuracy tracks the quality of the semantic layer grounding the query, not the size of the model writing it. That is where enterprise text-to-SQL is won or lost.
Closing the gap: the semantic layer
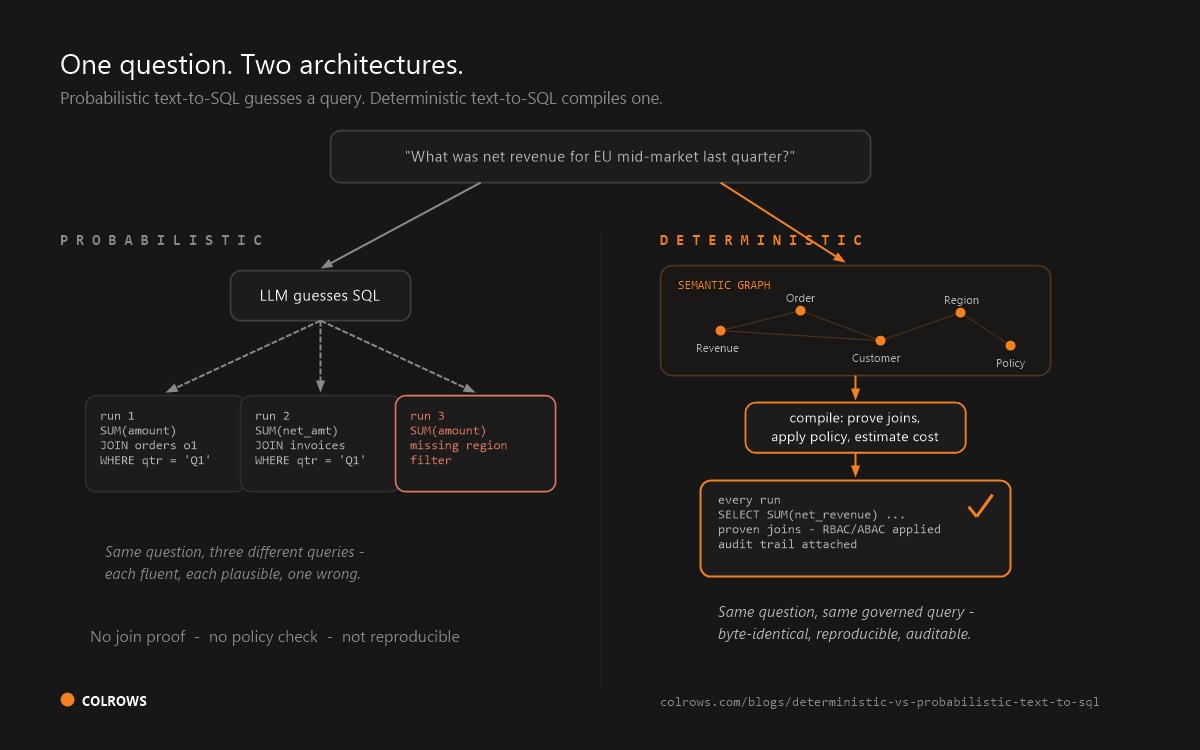
The numbers explain why deterministic, semantic-layer approaches exist. A typed semantic graph resolves meaning, proves the join path, and refuses on ambiguity instead of guessing. Colrows is built on this compile-then-execute model: it emits deterministic, dialect-perfect SQL across 16+ engines with governance enforced before execution. For the narrative version of this data, see the text-to-SQL accuracy cliff; for the tool landscape, see the best text-to-SQL tools; for the architecture, see deterministic vs probabilistic text-to-SQL.
Cite this benchmark
You are welcome to reference this compilation. Suggested citation:
Primary sources: the Spider 2.0 paper (Lei et al., arXiv:2411.07763) reports the Spider 1.0, BIRD, and Spider 2.0 figures for a common o1-preview code-agent framework; the BEAVER benchmark reports the near-0% off-the-shelf result on real warehouse data. Always verify against the primary papers before publishing.
Frequently asked questions
What is the best text-to-SQL benchmark for enterprise use?
Spider 2.0, for its realism: 632 real workflows over schemas averaging ~800 columns. Best published result is about 21.3%. BEAVER tests real warehouse data, where off-the-shelf LLMs score near 0% end-to-end.
Why is enterprise text-to-SQL so much harder than benchmarks suggest?
Academic sets use small, clean schemas; real enterprises have hundreds of columns, ambiguous names, and governance rules. The grounding semantic model, not the LLM, is the bottleneck.
How do you improve accuracy on real data?
Ground generation in a governed semantic layer that resolves meaning, proves joins, and refuses on ambiguity. Fix the context, not the model.