Probabilistic vs. Deterministic Text-to-SQL at a Glance
| Capability | Probabilistic (LLM / RAG) | Deterministic (Colrows) |
|---|---|---|
| Logic Foundation | Heuristic / Prompt-based | Formal Semantic Definitions |
| SQL Output | Non-deterministic / Guessing | Verified / Auditable SQL |
| Error Rate | High (Hallucination risk) | Near-Zero (Compile-time) |
| Governance | Runtime / Patchwork | Pre-query / Integrated |
| Enterprise Fit | Experimental / Prototyping | Production / Mission-critical |
The architecture gap: prompt-based generation vs. compile-time validation
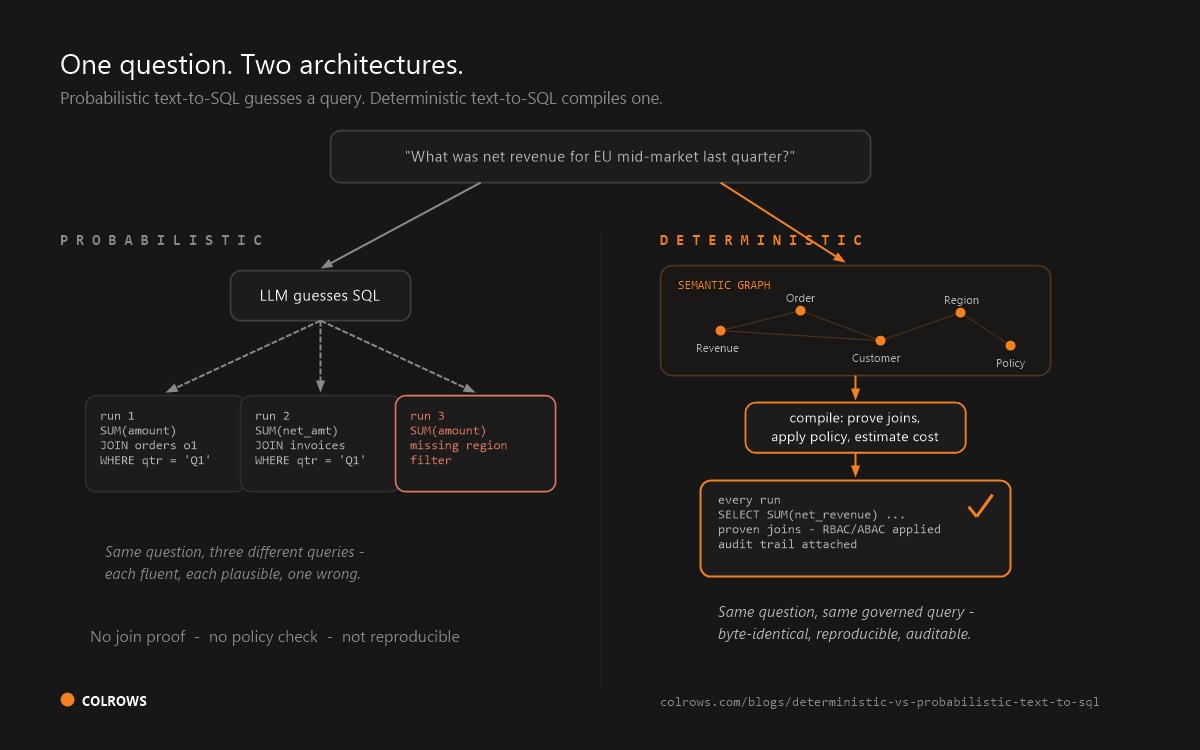
Probabilistic and deterministic text-to-SQL are not two flavors of the same approach. They are two different architectures that fail in opposite ways. For enterprise data, only one is production-ready.
The probabilistic failure
Prompt-based approaches treat SQL generation as a sequence-prediction problem. They sample tokens against learned distributions, conditioned on a schema dump and an instruction. That works when the schema is small, clean, and stable. It breaks the moment a column gets renamed, a join condition changes, or a metric definition gets refined. The prompt does not know. The model writes a query that still parses, still runs, and still returns a number, and the number is silently wrong. Every change to the data schema is a new opportunity for drift.
The deterministic advantage
Colrows treats SQL as a compile target, not a generated string. The Colrows semantic compiler validates schema relationships, proves join paths, and resolves metric definitions against a typed graph before any SQL is emitted. The compilation either succeeds with a verified, dialect-perfect query or fails with an explainable error. There is no path to a confidently wrong number, because the system refuses to produce one. For the empirical evidence on how badly raw generation collapses on real enterprise schemas, see The Text-to-SQL Accuracy Cliff.
Do not gamble with your enterprise data. A deterministic semantic layer ensures your SQL is always accurate, auditable, and aligned with your business logic. Fix the context, not the model.
The stakes: a wrong number that looks right
Picture a revenue bot. On Monday it reports $12 million. On Tuesday, with no change to the underlying data, it reports $9.5 million. Nobody touched the warehouse. The model simply generated a slightly different query: it joined one extra table, or filtered a status code differently, or summed a different revenue column. Both answers were syntactically perfect SQL. Both ran without error. One of them is wrong, and nothing in the system flagged which.
This is the defining failure mode of probabilistic text-to-SQL. It does not fail like software, with a stack trace. It fails like a confident junior analyst, with a plausible number. In a self-service tool used by non-technical staff, nobody can catch it because the wrongness is in the logic, not the syntax. In an autonomous agent loop, the error propagates into the next step before any human sees it.
The fix is not a better model. It is a different architecture.
Two ways to turn a question into SQL
Every chat-with-your-data product converts a question into a database query. There are exactly two ways to do it.
Probabilistic text-to-SQL hands the question, plus whatever schema fits in the prompt, to a large language model and asks it to write SQL. The model emits the most likely query, token by token. Its defining property is that the output is a sample from a probability distribution. The same question can produce different SQL on different runs, and nothing in the architecture distinguishes a correct query from a merely fluent one.
Deterministic compilation puts a compile step between intent and execution. The question is resolved against an explicit semantic model (entities, metrics, relationships, join paths, policies), and the SQL is constructed from that model rather than guessed. The same question, in the same scope, against the same model version, always produces the same SQL. When the question cannot be resolved, the system returns an error instead of a plausible wrong answer.
The split is not academic. It mirrors the oldest principle in compiler engineering: same input, same output, every time. For a deeper comparison of architectures, see semantic layer vs text-to-SQL.
| Probabilistic text-to-SQL | Deterministic compilation | |
|---|---|---|
| How SQL is produced | Sampled token by token by an LLM | Constructed by rules from a semantic model |
| Same question twice | May differ | Byte-identical |
| Failure mode | Plausible wrong number (silent) | Error message (loud) |
| Out-of-scope question | Guesses | Refuses |
| Cost per query | One or more LLM calls | Near-zero marginal compute |
| Auditability | Logs tokens and temperatures | Replays exact logic |
| Best at | Flexibility, coverage, prototyping | Reproducibility, governance, agents |
Why "temperature 0" is not deterministic
Here is the part most teams get wrong. Setting an LLM to temperature 0 (greedy decoding, always pick the highest-probability token) does NOT make it deterministic in production. It only removes intentional randomness from sampling. Several other sources of variance remain.
In September 2025, Thinking Machines Lab (the lab founded by former OpenAI CTO Mira Murati) published "Defeating Nondeterminism in LLM Inference," authored by Horace He and collaborators. They sampled 1,000 completions at temperature 0 from Qwen3-235B-A22B-Instruct-2507 with the single prompt "Tell me about Richard Feynman." They got 80 unique completions, the most common occurring 78 times. The runs were identical for the first 102 tokens and first diverged at the 103rd: all of them generated "Feynman was born on May 11, 1918, in," but 992 continued with "Queens, New York" while 8 produced "New York City."
The cause: a lack of batch invariance. Modern inference servers batch many users' requests together, and the batch size fluctuates with load. Because key GPU kernels (RMSNorm, matrix multiplication, attention) reduce floating-point numbers in an order that depends on batch shape, and floating-point addition is non-associative ((a+b)+c does not equal a+(b+c)), your output depends on how many other requests happened to be in flight when yours ran.
Other production sources compound this: mixture-of-experts (MoE) routing sends tokens to different experts based on batch context, datacenter load balancing can land your call on a different GPU type, and speculative decoding adds its own variance. The practical upshot for SQL is severe. In natural-language prose, "Queens, New York" versus "New York City" is harmless. In code, a single flipped token changes a JOIN, a filter, or an aggregation, and the query silently returns a different number.
Thinking Machines showed the problem is solvable with batch-invariant kernels (all 1,000 completions then matched bitwise), but at a cost: on Qwen-3-8B, generating 1,000 completions took 26 seconds with default vLLM, 55 seconds in the unoptimized deterministic mode, and 42 seconds with an improved attention kernel, roughly a 1.6 to 2x slowdown. Determinism at the model layer is achievable but expensive, and it is not the default in any commercial API today. That is precisely why determinism is better engineered outside the model, in the compilation step.
The theoretical foundation: determinism is what makes systems auditable
Determinism is not a nice-to-have. It is the property that makes a system testable, replayable, and provable. It is the bedrock of compiler design. The C# compiler (Roslyn) has shipped a /deterministic flag since Visual Studio 2015 that produces byte-for-byte identical binaries from identical inputs, which in turn enables content-based build and test caching (one team reported 72% savings on test time from caching deterministic output). The broader reproducible-builds movement exists for the same reason: a deterministic build "can act as part of a chain of trust," proving a binary was compiled from trusted source.
A deterministic compiler can be tested the normal way: feed it an input, assert on the output, and the test means something because the output never changes. A probabilistic system can only pass a statistical test (it is right 90% of the time), and any individual run is unreproducible. You can prove a deterministic system correct. You can only characterize a probabilistic one.
The accuracy and reliability trade-off
The benchmark record is consistent and comes from the vendors' and authors' own numbers.
On in-scope queries, deterministic compilation eliminates the silent-wrong-answer problem. dbt Labs' April 2026 benchmark ran 11 insurance-domain questions, 20 times each, comparing frontier models (Sonnet 4.6, GPT-5.3 Codex, and others) on raw text-to-SQL against their MetricFlow-powered deterministic Semantic Layer. With minimal modeling added, text-to-SQL landed at 84.1% (GPT-5.3 Codex) to 90.0% (Sonnet 4.6) while the Semantic Layer hit 98.2% (Sonnet 4.6) to 100.0% (GPT-5.3 Codex). dbt's own explanation: "the Semantic Layer's deterministic query generation means the LLM can't produce subtly wrong results." Their summary is the whole argument: "With text-to-SQL, failure looks like a plausible but incorrect answer. With the Semantic Layer, failure looks like an error message."
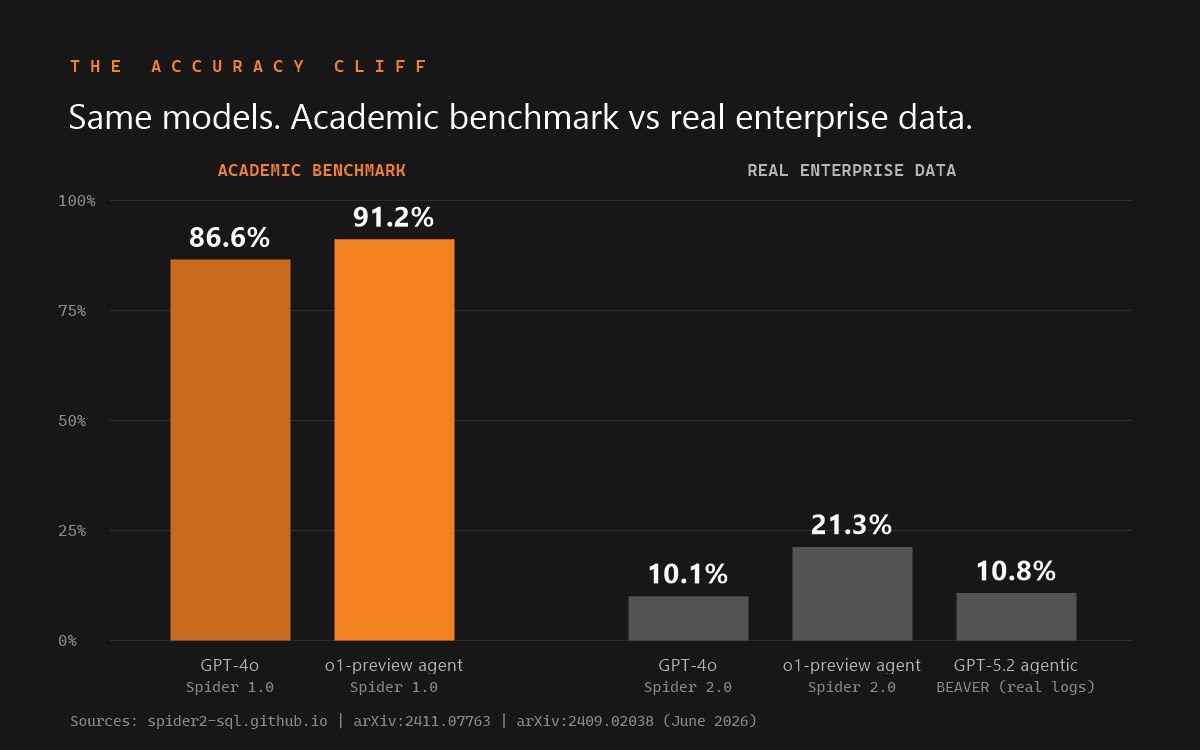
On real enterprise data, raw generation collapses. On the text-to-SQL accuracy cliff, Spider 2.0 (Lei et al., ICLR 2025) an o1-preview agent framework solved 21.3% of tasks versus 91.2% on the older, clean Spider 1.0; GPT-4o managed 10.1% versus 86.6%. Snowflake reported, in its August 2024 engineering blog, that single-shot GPT-4o accuracy "plummeted to 51%" on its internal 150-question set, rising to "90%+" once wrapped in a hand-authored semantic model (see Cortex Analyst vs Genie for comparison with Databricks). On BIRD, the human expert baseline is 92.96%, and as of June 12, 2026 the top named single model, Google's Gemini-SQL2 (built on Gemini 3.1 Pro), scored 80.04% execution accuracy, leaving a 12.92-point gap to humans.
On reliability, the difference is binary. Deterministic compilation returns the same answer run to run. Probabilistic generation returns an answer that depends on model version, batch order, and inference state. A capable LLM can score 90%+ on individual runs and still produce correct SQL one run and wrong SQL the next on the same question. That variance does not go away with better prompting; it is a property of using a probabilistic process for a deterministic task.
The honest counterpoint: on OUT-of-scope queries, the two architectures fail differently, and neither is universally better. A probabilistic system attempts any question and guesses. A deterministic system refuses anything outside its model. If you would rather get a flagged refusal than a confident guess, determinism wins. If you would rather get a draft you can inspect, probabilistic wins. The deciding factor is whether a human reviews every query before the number is trusted.
Cost and performance
Probabilistic generation runs an LLM on every query, often several times per query in agentic loops that draft, execute, and self-correct. Deterministic compilation runs the LLM at most once to resolve intent, then constructs SQL with classical code.
The published cost spread is large. SEA-SQL (arXiv:2408.04919, Table 5) measured per-query generation costs on the BIRD development set using GPT-4: DIN-SQL at $0.7867 per query, MAC-SQL at $0.2151, and DAIL-SQL at $0.1232. The same paper recorded agentic pipelines taking 12 to 16 seconds of API time per query. By contrast, a compiled semantic layer offers near-zero marginal cost per query: dbt states that the latency of its Semantic Layer query runtimes is "in the order of milliseconds," with MetricFlow adding "near-zero compute overhead" because the bottleneck is the warehouse, not the layer.
Caching widens the gap. A deterministic plan caches cleanly because it is identical every time. Probabilistic output cannot be cached as a correctness guarantee, because the next run may differ. At scale, probabilistic cost grows with volume times refinement steps, while deterministic plan generation is effectively constant per question pattern.
The regulatory case: determinism is the engineering base for audit
This is where the technical property becomes a business requirement. Four regimes converge on the same demand: a documented, reproducible chain from input to output.
- SOX Section 404 requires management to document, test, and attest to internal controls over financial reporting, backed by audit trails and retained records (seven years under Section 802), not verbal explanation. A compiled query against a versioned semantic model IS a documentable control. "We sampled tokens at temperature 0" is not.
- HIPAA 45 CFR 164.312(b) requires audit controls: hardware, software, or procedural mechanisms that record and examine activity in systems holding electronic protected health information. The Office for Civil Rights uses audit-control findings as evidence in breach investigations because logs "are the only way to prove what did or did not happen." Deterministic compilation makes field-level, query-level, and version-level traceability possible because the logic is explicit and replayable.
- GDPR Article 22 restricts solely automated decisions with legal or similarly significant effects and, read with Articles 13 to 15 and Recital 71, gives data subjects a right to meaningful information about the logic involved. A compiled query against a versioned schema is that logic. Token-sampling metadata is not.
- EU AI Act Article 12 requires high-risk AI systems to "technically allow for the automatic recording of events (logs) over the lifetime of the system" sufficient for traceability. Full application for high-risk systems begins 2 August 2026, with logs retained at least six months under Article 26(6). Deterministic logging captures intent, compilation, SQL, and result. Probabilistic logging captures prompts, tokens, and temperatures, which do not reconstruct the decision. This is especially critical for semantic layer and AI agents operating in regulated domains.
The test under all four: can you replay a decision and prove it was correct according to the rules in force at the time? A versioned, deterministic system can. A probabilistic generator cannot, because the run is not reproducible.
Why probabilistic generation exists (the honest case)
Determinism is not free, and probabilistic systems earn their place. They are genuinely better at several things:
- Flexibility. A model can explore paraphrases and alternative interpretations of an ambiguous question without anyone pre-defining them. A semantic layer can only answer what has been modeled.
- Coverage. A probabilistic system will attempt any question, even against an incomplete schema. A semantic layer refuses anything out of scope.
- Adaptation. A model can pick up patterns from new examples without schema changes; a semantic layer needs explicit definition updates.
- Natural-language understanding. LLMs excel at fuzzy, underspecified intent. This is exactly why good deterministic systems still put an LLM at the front, to map "show me underperforming stores last quarter" to a structured intent.
- Speed to prototype. Point a model at a schema and ask questions. No modeling overhead. For an analyst exploring a new dataset who reads the SQL before trusting it, this is a fast, useful drafting accelerator.
The cost of these strengths is exactly the reproducibility and auditability you give up. That is the trade.
Who is which
Probabilistic by construction: GPT, Claude, and Gemini doing raw text-to-SQL, plus framework examples from LangChain and LlamaIndex, and self-hosted serving via vLLM and Ollama. These serve exploration and prototyping well.
Deterministic query generation: the dbt Semantic Layer (MetricFlow compiles a metric request into a dataflow plan, then renders engine-specific SQL), Cube, Snowflake Semantic Views, Databricks Metric Views, AtScale, Timbr, and Colrows. Apache Calcite belongs here too, as a rules-based optimizer rather than a sampler. The market trend is clear: every major warehouse shipped a deterministic semantic layer through 2025 and 2026 (Snowflake Semantic View Autopilot, Databricks Unity Catalog Business Semantics), and new entrants launch deterministic by default. The side-by-side capability matrix compares the deterministic platforms on the criteria that matter for AI workloads; use the semantic layer evaluation checklist to assess fit in your organization.
Where Colrows sits, honestly
Colrows is a semantic execution layer: deterministic compilation taken to its conclusion. The semantic graph is versioned, typed, and multi-scope (global to datastore to persona to user), built and maintained autonomously with drift detection rather than hand-authored YAML. Every question, from a human in chat or an agent over HTTP, JDBC, or MCP, runs the same compile-then-execute pipeline: intent resolved via multi-vector embeddings, joins proven against the graph, RBAC and ABAC and row/column predicates injected at compile time, dialect-perfect SQL emitted for the target engine, and a point-in-time reproducible audit trail attached to the answer. Ask it the same question twice, get the same SQL. Ask it something it cannot prove, and it tells you before reading a single byte.
The honest trade-off: this requires upfront modeling, and it answers a scoped set of questions. If your schema does not cover a question, Colrows refuses rather than guesses. (dbt's benchmark closed its own coverage gap by adding just 3 dbt models, but the modeling effort is real and ongoing as schemas change.) For ad hoc exploration where a human inspects every query, a probabilistic tool may be faster. For numbers that reach boards, customers, filings, or autonomous agents, the refusal is the point. If you are evaluating warehouse-native semantic layers, understand their scope boundary before committing to them as your enterprise base.
The bottom line
Stop asking which model writes better SQL. Ask which architecture makes a wrong number impossible to ship silently. For exploration, probabilistic generation is a fine accelerator. For regulated work and agents operating at machine speed, determinism is no longer a preference. It is the control.
Frequently asked questions
What is deterministic text-to-SQL?
An architecture that compiles natural-language intent through an explicit semantic model (entities, metrics, join paths, policies) instead of generating SQL token by token. The same question, in the same scope, against the same model version, always produces the same SQL. Unresolvable questions fail with an error rather than a plausible wrong query.
Is an LLM at temperature 0 deterministic?
No. Temperature 0 removes intentional sampling randomness but not production non-determinism. Thinking Machines Lab generated 80 unique completions from 1,000 temperature-0 runs of one prompt, caused by batch-size variance in GPU kernels, plus MoE routing and datacenter routing. True bitwise reproducibility requires batch-invariant kernels and is not the default in commercial APIs.
Why does probabilistic text-to-SQL fail silently?
Because a generated query is usually valid SQL that runs and returns a result. The error is in the logic (wrong join, wrong filter, wrong aggregation), not the syntax, so there is no exception to catch. The number looks right and is wrong.
How much more accurate is a deterministic semantic layer?
On in-scope, well-modeled questions, dbt's 2026 benchmark measured 98.2% to 100% for the deterministic Semantic Layer versus 84.1% to 90% for raw text-to-SQL, with the layer eliminating subtly wrong results. Snowflake measured 90%+ with a semantic model versus single-shot GPT-4o that "plummeted to 51%."
What about cost?
Published agentic text-to-SQL pipelines cost roughly $0.12 to $0.79 per query (SEA-SQL, GPT-4) and take 12 to 16 seconds. A compiled semantic layer adds near-zero marginal compute, with latency "in the order of milliseconds" (dbt).
Does determinism help with compliance?
Yes. SOX 404, HIPAA 164.312(b), GDPR Article 22, and EU AI Act Article 12 all require documented, reproducible, traceable decision-making. A versioned deterministic compilation can be replayed and proven; a probabilistic run cannot.
When is probabilistic text-to-SQL the right choice?
For exploratory analysis where a human reads and validates the SQL before trusting the result, for rapid prototyping against a new schema, and for questions outside any modeled scope. Its flexibility and coverage are real advantages when reproducibility is not required.
What is the trade-off of a deterministic semantic layer?
It requires upfront modeling and only answers questions within its modeled scope. dbt's benchmark closed its coverage gap by adding just 3 dbt models, but the modeling effort is real and ongoing as schemas evolve.
Do agents need determinism?
In a multi-step agent loop, probabilistic errors compound silently across steps with no checkpoint between a probabilistic planner and deterministic execution. A deterministic foundation lets agents reason over stable definitions and produces a traceable record of each action. For how RAG vs semantic layer complements this strategy, see the dedicated comparison.
Why is text-to-SQL inaccurate on enterprise data?
Enterprise schemas are large, ambiguous, and full of institutional context that lives outside the database: which of three revenue columns is the governed one, which join path is approved, which rows a given user may see. Academic benchmarks with small clean schemas hide this. On benchmarks built from real enterprise warehouses - Spider 2.0 and BEAVER - raw frontier-model success rates fall to roughly 10-21%, versus 86-91% on the older single-database benchmarks.
How accurate is text-to-SQL in 2026?
It depends entirely on how much structure surrounds the model. Raw single-shot generation on real enterprise workloads measures around 10-51% in published evaluations (Spider 2.0, BEAVER, Snowflake's internal benchmark). Systems that add an explicit semantic model report 90%+ (Snowflake Cortex Analyst) and 98-100% on well-modeled questions (dbt's 2026 benchmark). The accuracy lives in the context layer, not the model.
Does a better LLM fix text-to-SQL accuracy?
The published evidence says no. BEAVER found a state-of-the-art agentic framework using GPT-5.2 achieved 10.8% on real enterprise warehouses. Snowflake measured GPT-4o at 51% on its internal real-world set and reached 90%+ only after adding a semantic model. In dbt's benchmark, the deterministic layer - not the model choice - accounted for the accuracy gain. Every published path to high accuracy adds structure around the model; none of them is just a bigger model.
What is the difference between a semantic layer and text-to-SQL?
Text-to-SQL is a capability: turn a natural-language question into a SQL query, usually by LLM generation. A semantic layer is infrastructure: an explicit, governed model of what the data means - entities, metrics, join paths, policies - that queries are resolved against. A semantic execution layer goes one step further: it compiles intent through that model into governed, dialect-perfect SQL, with join path proof and compile-time governance, so the generation step is constrained instead of free-form.