What each one is
Snowflake Cortex Analyst is, in Snowflake's words, "a fully-managed, LLM-powered Snowflake Cortex feature that helps you create applications capable of reliably answering business questions based on your structured data in Snowflake." It is API-first - a REST endpoint you integrate into Streamlit apps, Slack, Teams, or custom chat - and it is grounded in an authored artifact: a semantic view (the recommended path; legacy YAML semantic models remain supported) that declares logical tables, dimensions, facts, metrics, and crucially, relationships: "Join paths are predefined, ensuring correct multi-table queries." Since November 2025, the same semantic views also power agents in Snowflake Intelligence.
Databricks AI/BI Genie is a chat product rather than an API service: business users ask questions in a Genie space that a data analyst has configured. The setup documentation is explicit about the division of labour: data analysts configure each space with Unity Catalog tables, example SQL queries, instructions, and trusted assets; business users query it through the chat UI. Databricks' best-practices guide sets the mental model: "Think of Genie as a new data analyst joining your company. Like any new team member, Genie needs clear context to be effective."
Side by side, from the documentation
| Dimension | Snowflake Cortex Analyst | Databricks AI/BI Genie |
|---|---|---|
| Grounding artifact | Semantic view (schema-level object; YAML spec legacy-supported), with predefined join paths and a verified-query repository | Genie space: up to 30 Unity Catalog tables, instructions (100/space), knowledge-store snippets (200/space), trusted assets |
| Who curates | Data engineers / analytics engineers author and maintain semantic views | "Data analysts who are proficient in SQL" curate each space |
| Data boundary | "Your structured data in Snowflake"; SQL executes in your Snowflake virtual warehouse | "Must be registered to Unity Catalog"; queries run on a pro or serverless SQL warehouse |
| Determinism | "Different models produce different results"; "You cannot choose a model directly" | "Genie operates in a nondeterministic manner" (Databricks docs, verbatim) |
| Accuracy claim | "90%+ SQL accuracy" vs 51% single-shot GPT-4o - internal 150-question benchmark (Aug 2024) | "From 32% to over 90%" vs "a leading coding agent" - internal benchmark (May 2026) |
| Scale guidance & caps | Multi-turn supported with documented limits; 9 native regions, cross-region inference elsewhere | "Aim for five or fewer tables"; 20 questions/min per workspace via UI; 10,000 conversations per space |
| Pricing mechanics | Billed per message processed, plus warehouse costs to execute generated SQL | No per-question AI charge; you pay for the SQL warehouse (including idle time) |
| Surface | REST API; Snowflake Intelligence agents | Chat UI in workspace; Genie API (free tier limited to ~5 questions/min, best effort) |
All rows from the vendors' documentation linked throughout this page, as of 12 June 2026.
The curation tax: neither is "just ask your data"
Strip away the chat interface and both products are the same wager: an LLM is accurate when a human has first encoded the meaning of the data into a curated artifact. The vendors say so; the practitioners running them at scale say it louder.
On the Snowflake side, an architect who built 24 semantic models in production summarized: "Semantic Views look simple: define tables, dimensions, and metrics, then let Cortex Analyst turn questions into SQL. Reality: they're strict... Semantic Views work when you treat them like a strict interface, not flexible SQL." Another practitioner's production retrospective: "No amount of prompt engineering on the Analyst side compensates for a poorly described YAML... the magic is in the YAML. Always" - with verified queries functioning as "few-shot prompting but for SQL. I always start with 5-10 verified queries."
On the Databricks side, a community practitioner put it plainly: "Despite the name, it is not magic. There is still work to be done at the catalog and semantic level by people who understand the underlying data... If your metadata is messy, Genie fails." A consultancy's hands-on build log quantifies the journey: a fresh Genie space answered 8 of 15 test questions correctly (53%) "right out of the gate," and reached 15/15 only after systematic remodeling, Unity Catalog annotation, knowledge-store configuration, and iterative benchmarking. That end state is real - and so is the labour between the two numbers.
Both products also ship the same safety valve under different names: Snowflake's verified queries and Databricks' trusted assets are human-approved SQL for anticipated questions, returned in place of fresh generation. They demonstrably improve accuracy - by replacing generation with curation for the questions someone predicted in advance. Honest budgeting treats them as ongoing editorial work, not a one-time setup task.
What the accuracy claims actually measure
Both vendors grade their own homework, and the two report cards are not comparable.
- Snowflake's number comes from its August 2024 engineering blog: on "an internal benchmark suite of 150 questions that mirror the real-world tasks business users encounter," single-shot GPT-4o "plummeted to 51%," while Cortex Analyst achieved "90%+ SQL accuracy." The lift is real and instructive - it is the semantic model doing the work - but the evaluation set is internal and the comparison baseline is a deliberately naive single prompt.
- Databricks' number comes from its May 2026 AI research post: the new Genie architecture improved accuracy "from 32% to over 90%" - against "a leading coding agent," on a different internal benchmark of real-world data analysis tasks. Note what that is not: it is not a Genie-then vs Genie-now number, and not comparable to Snowflake's 51%.
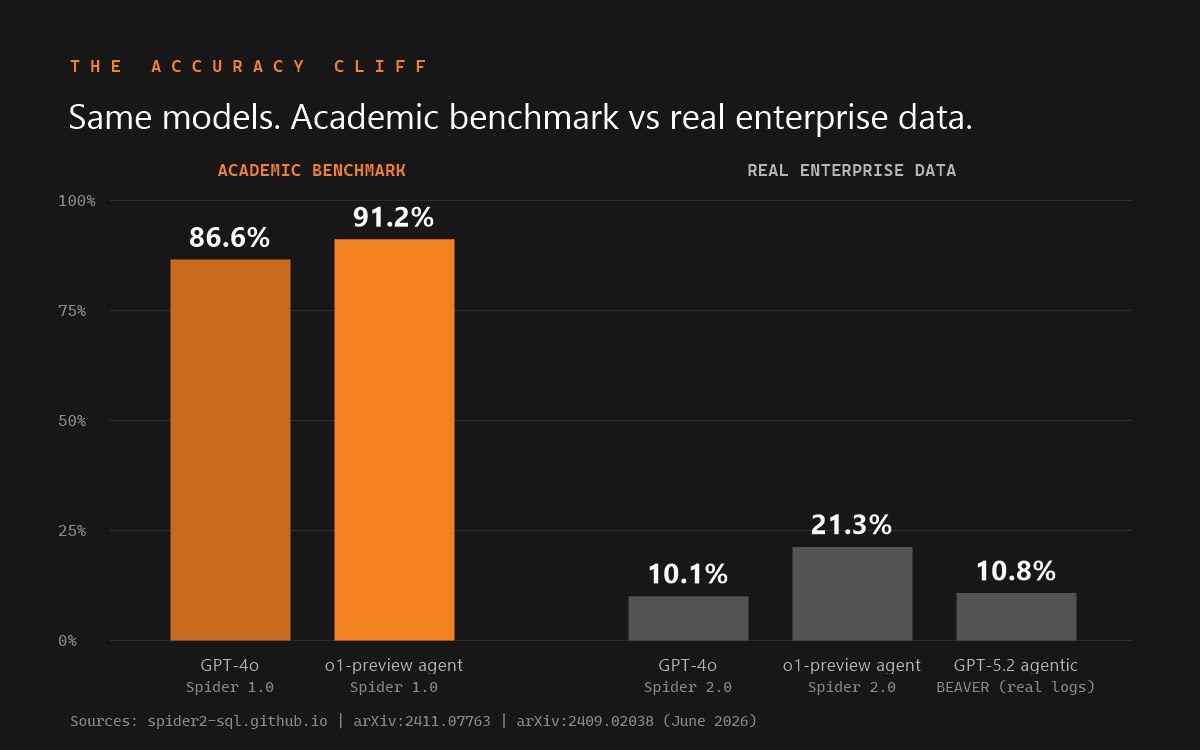
- Independent signals are sparser and humbler. One consultancy estimates that teams skipping the semantic model "get the 90% accuracy claim in benchmarks and 60 to 70% in the real world" (an estimate, not a study). And the broader benchmark literature - Spider 2.0, BEAVER - shows raw frontier models solving 10-21% of real enterprise text-to-SQL tasks, which is the cliff both products' curation layers exist to climb. We dissect that evidence in The Text-to-SQL Accuracy Cliff.
The honest reading: both vendors have independently confirmed the central thesis of this space - accuracy lives in the curated context, not the model - and both publish numbers that say more about their evaluation sets than about each other.
The boundary both share
Here is the structural fact that outlasts every release cycle: each product reads only its own platform's metadata and executes only on its own platform's compute. Snowflake scopes Cortex Analyst to "your structured data in Snowflake," with generated SQL "executed in your Snowflake virtual warehouse" and governance defined as full integration with Snowflake RBAC. Databricks requires that Genie data "be registered to Unity Catalog," with Unity Catalog permissions - "not the Genie Space itself" - controlling access, and the space author's "compute credentials... embedded into the Genie Space and used to process all queries for all users."
Inside one platform, this is a feature: governance inheritance is clean and nothing leaves the boundary. Across an enterprise, it is the limitation. The questions executives actually ask - margin by customer where billing lives in Snowflake, product telemetry in Databricks, and reference data in Postgres - have no home in either tool. You either ingest everything into one platform (the strategic outcome both vendors would prefer), or you accept two AI analysts with two semantic dialects and two partial answers. Snowflake itself acknowledged the fragmentation problem by co-launching the Open Semantic Interchange initiative in September 2025 - a vendor-neutral semantic model spec, which is also an admission that semantics locked inside one warehouse are a dead end. The full argument is in Why Snowflake and Databricks Can't Be Your Enterprise Semantic Layer.
Choosing - including the option above both
Choose Cortex Analyst when your governed analytical estate genuinely lives in Snowflake, you want an API to embed in your own applications, and you have the engineering discipline to own semantic views as versioned interfaces.
Choose Genie when your estate is Databricks-centric, your consumers want a curated chat experience per domain, and a data analyst team can own the spaces - small, purposeful ones, per Databricks' own "five or fewer tables" guidance.
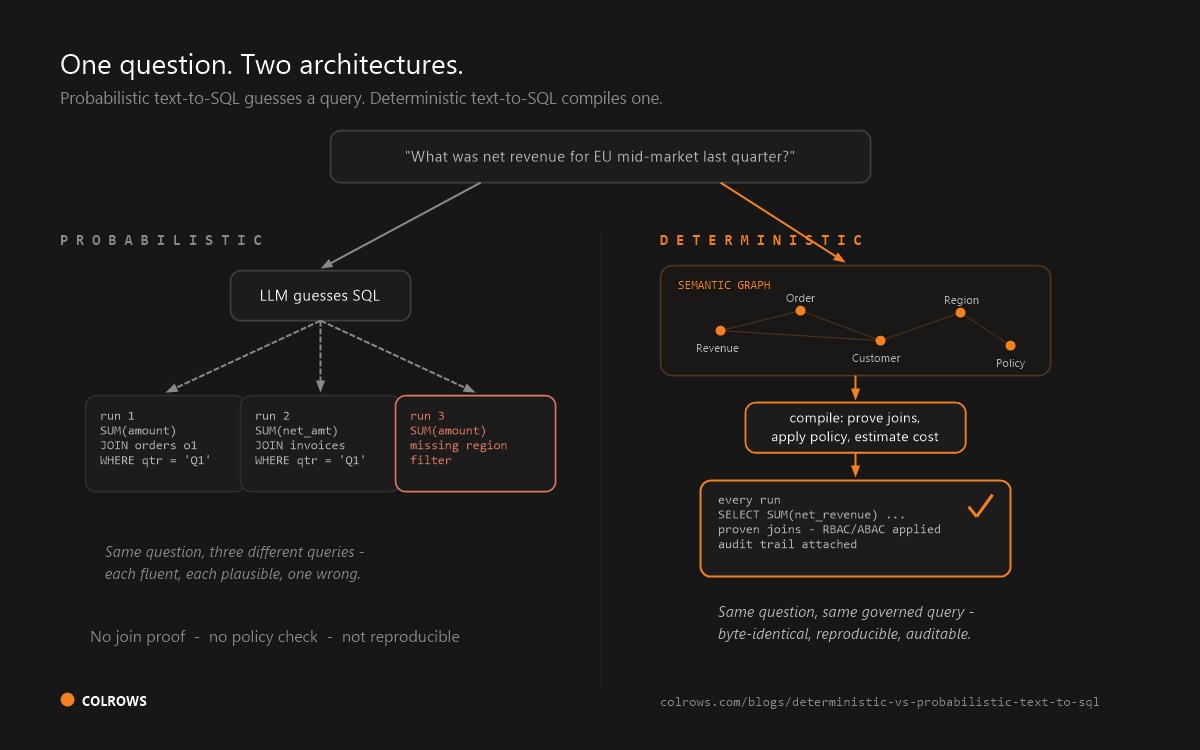
Look above the warehouse when the questions cross platforms, when regulated workloads need provable rather than probable governance, or when AI agents - not humans in a chat window - are the consumers. For comparison with other single-platform analytics tools, see dbt Semantic Layer vs Cube vs AtScale. That is the altitude Colrows occupies: a semantic execution layer that builds and maintains one semantic graph - versioned, typed, multi-scope - across Snowflake, Databricks, and the rest of the estate, and compiles every question through it: intent → context resolution → constrained planning → governed execution. Join path proof replaces predefined-joins-per-view; compile-time governance (RBAC + ABAC + row/column-level predicates) replaces per-platform inheritance; and the output is dialect-perfect SQL for whichever engine holds the data, with an audit trail per query. The warehouse-native tools curate context inside one wall. The execution layer compiles against context across all of them.
Frequently asked questions
Which is better, Cortex Analyst or Genie?
Inside their own platforms, both are credible defaults: Cortex Analyst for Snowflake estates (API-first, semantic-view-grounded), Genie for Databricks estates (curated chat spaces over Unity Catalog). Both need sustained curation, both are documented as nondeterministic or model-variable, and neither crosses its platform boundary - so for multi-platform estates the real choice is what sits above them.
Does either work on data outside its own platform?
No. Snowflake scopes Cortex Analyst to "your structured data in Snowflake"; Databricks requires Genie data to "be registered to Unity Catalog." Cross-platform questions require ingestion or a semantic layer above both.
How accurate is Cortex Analyst?
Snowflake reports 90%+ on its internal 150-question benchmark, versus 51% for single-shot GPT-4o - an internal evaluation whose lesson is that the semantic model, not the LLM, carries the accuracy. Practitioner reports tie real-world results directly to semantic-view quality and verified-query coverage. For the broader accuracy comparison between deterministic and probabilistic architectures, see Deterministic vs Probabilistic Text-to-SQL.
What are Genie's documented limitations?
Unity Catalog registration required; up to 30 tables per space ("aim for five or fewer"); pro or serverless SQL warehouse with the author's embedded credentials; 20 questions/minute per workspace via the UI; curation budgets of 100 instructions and 200 knowledge-store snippets per space; and, verbatim, "Genie operates in a nondeterministic manner."
How are they priced?
Cortex Analyst bills per message processed (reported at roughly 6.7 credits per 100 messages, per Snowflake's consumption table) plus warehouse costs for executing the generated SQL. Genie has no per-question AI charge - you pay for the SQL warehouse runtime, including idle time between sessions. In both, the dominant unbudgeted cost is curation labour.
A note on the claims
Every vendor statement above was verified on docs.snowflake.com, docs.databricks.com, or the vendors' blogs as of 12 June 2026, and accuracy figures are the vendors' own claims about their own internal benchmarks - cite them as claims, as we do. Both products ship changes monthly (Genie's table limit rose from 25 to 30 this year; Cortex Analyst's model lineup changes regularly). This page is reviewed quarterly.