What each one actually is
The dbt Semantic Layer (MetricFlow) is a metric layer co-located with your dbt project: you define entities, dimensions, and measures in YAML beside the models that build the tables, and MetricFlow generates the SQL when a BI tool or API asks for a metric. Its gravitational pull is consistency - one definition of revenue served identically to a specific list of integrations (Power BI, Tableau, Google Sheets, Excel, Hex, Mode, and others), with everything else reaching metrics via JDBC/ADBC/GraphQL. It requires a paid dbt platform plan; dbt Core users can author the YAML but cannot query it through the APIs.
Cube grew from a different job: embedded analytics and data products. Engineers author YAML or JavaScript data models, and Cube exposes them as REST, GraphQL, and SQL APIs backed by a serious caching and pre-aggregation engine. If you are building a customer-facing analytics product and need sub-second responses at concurrency, that engine is the draw - and an operational discipline of its own.
AtScale is the enterprise OLAP heir: multi-dimensional models (now expressible in SML, open-sourced under Apache in September 2024) virtualized over the warehouse, with aggregate awareness rewriting queries against pre-computed rollups. Its consumers are BI tools - Tableau, Power BI, Excel - at organizations where "unlimited users, queries, and data sizes" is the selling line and the modeling is done by specialists.
Side by side
| Dimension | dbt Semantic Layer | Cube | AtScale |
|---|---|---|---|
| Artifact & author | MetricFlow YAML, by analytics engineers, inside the dbt project | YAML/JS data models, by developers, deployed like software | OLAP-style models / SML, by BI modeling specialists |
| Primary consumer | BI tools needing consistent metrics | Embedded apps and APIs | Enterprise BI tools at scale |
| Pricing model (Jun 2026) | $100/user/mo Starter + queried-metrics meter (5,000/mo included); Enterprise custom | $40-80/developer/mo + hourly infrastructure; Vendr median $37,200/yr | $10-28 per deployed semantic object/mo; floors $2,500-7,000/mo |
| What the meter taxes | Query volume | Team size + uptime | Model richness |
| Documented constraints | Mandatory time-spine model; single global namespace; platform-plan requirement | Pre-aggregation build costs and tuning; three pricing-model changes | "Complex to set up and configure" (Gartner reviewers); specialist skills |
| AI story | MCP/AI integrations on the metric layer | D3 agentic analytics (June 2025) | Agentic AI via semantic models + MCP |
| Data model shape | Metrics + entities (for joins) | Cubes: measures, dimensions, joins | Multi-dimensional cubes |
All pricing from the vendors' published pages and Vendr marketplace data as of 12 June 2026, linked above and in the cluster pages below.
Read the meters, not the list prices
The most useful comparison is what each pricing model taxes, because that is what your organization will unconsciously optimize against. dbt SL meters queried metrics - per dbt's billing docs, "every successful request you make to render or run SQL to the Semantic Layer API counts as at least one queried metric" - which is benign for dashboard refreshes and hostile to AI-agent workloads that query continuously. Cube meters developers and infrastructure hours, which is benign for query volume and means your costs scale with the team maintaining the models (Cube has also cycled through three pricing models - pass-through, consumption units, now per-developer - itself a data point about how hard this is to meter predictably). AtScale meters deployed semantic objects - unlimited users and queries, but every dimension and measure you model is a line on the bill, and AtScale's own explainer notes an average model runs roughly 250 objects.
None of these is wrong. Each is a bet about where your growth will come from - and each becomes a perverse incentive if the bet misses: teams rationing metric queries, understaffing model maintenance, or modeling less richly than the business needs.
The constraints to plan for
- dbt SL: the mandatory time spine ("to use MetricFlow with time-based metrics and dimensions, you must provide a time spine") and the single global namespace - two domains cannot both define
total_saleswithout prefixing conventions. dbt's own product manager for the spec wrote in January 2026 that "defining metrics was just plain hard" - deep YAML nesting, fragmentation, duplication. - Cube: pre-aggregations are how it delivers performance, and they are an ongoing discipline - builds consume warehouse compute, indexes need configuring, and verified reviewers cite "occasional difficulty getting queries to use pre aggregations" and limited control over build timing.
- AtScale: the small Gartner Peer Insights review base praises query optimization and reports the product "complex to set up and configure," with integration restrictions adding cost. Budget a real implementation phase.
Full evidence for each - quotes, sources, pricing detail - is detailed in the sections below, organised by tool.
The assumption all three share
Strip the differences away and the three products agree on something foundational: a human team authors the semantic model, and a human team keeps it true. The YAML dialects differ; the labour does not. That assumption sets the ceiling in three ways your evaluation should test directly.
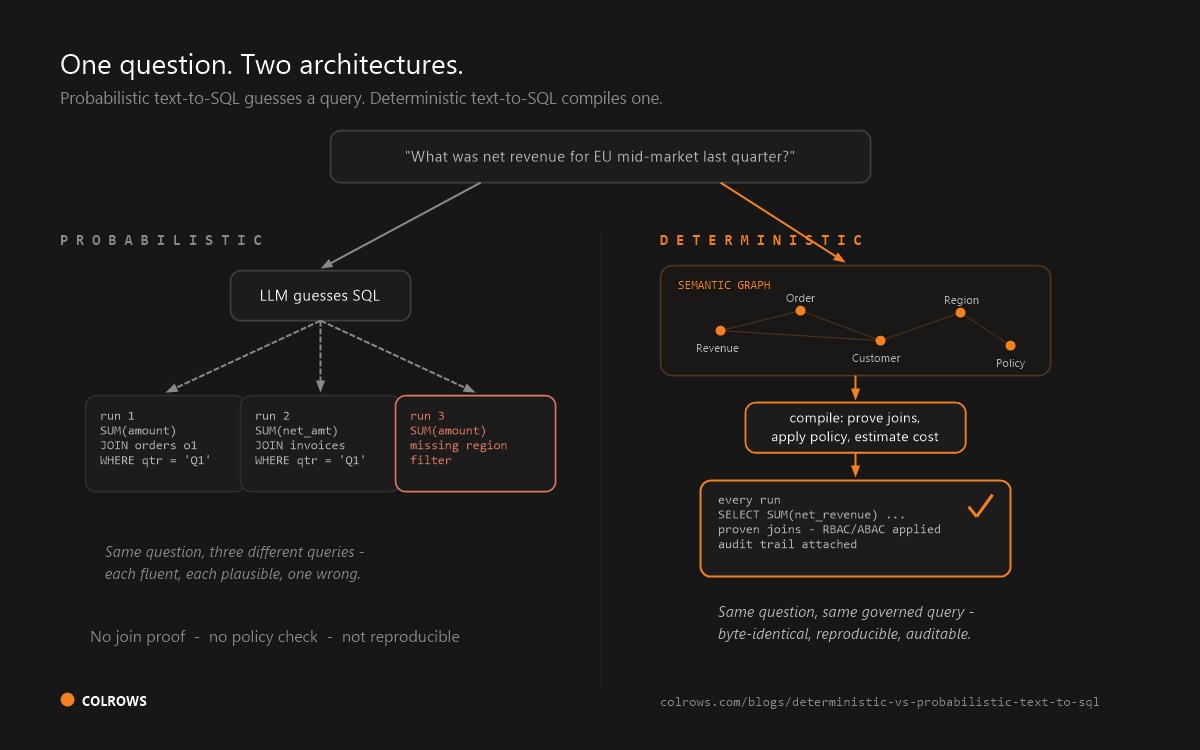
Coverage: concepts get modeled in priority order, so the long tail of questions - the ones self-service was supposed to answer - waits on a backlog. Freshness: schemas drift, and a definition that was right in January silently misdescribes the table in June; none of the three detects this for you. Shape: metrics and cubes answer "how much" questions; AI agents traverse entities and relationships - Customer to Subscription to UsageEvent under policy - and dbt's own 2026 benchmark showed the metric-layer ceiling precisely: on questions requiring too many entity hops, the Semantic Layer scored 0%, erroring rather than answering. Deterministic, but bounded by what a metric spec can model.
This is the axis where Colrows - our product, judge accordingly - takes a different position: the semantic graph is built autonomously from the estate and maintained with drift detection (removing the labour assumption), it is graph-shaped with typed entities and relationships and join path proof (removing the shape ceiling), and it compiles across warehouses with compile-time governance (removing the single-platform resolution boundary). The honest trade-off: all three incumbents have longer track records and deeper BI-tool integration ecosystems. If your consumers are BI tools and your team is happy authoring YAML, any of the three can serve you well. If your consumers increasingly include AI agents and your estate spans platforms, the assumption they share is the line item to price.
Choosing in one paragraph
dbt SL if your transformations live in dbt, your consumers are the supported BI integrations, and query volume is dashboard-shaped - compare with LookML vs dbt Semantic Layer if you use Looker. Cube if you are shipping embedded analytics or data products and have developers to own models and pre-aggregations. AtScale if you are serving large BI populations from governed multi-dimensional models and can staff the implementation. A semantic execution layer above the warehouses if the workload is conversational analytics and AI agents across a multi-platform estate, and you want the modeling built and maintained autonomously rather than by backlog. Use the Semantic Layer Evaluation Checklist to systematize the comparison.
Frequently asked questions
What is the difference between the dbt Semantic Layer and Cube?
Different jobs: dbt SL standardises metrics beside your dbt transformations for BI consistency (per-seat + queried-metrics meter); Cube serves authored data models as APIs for embedded analytics with a caching/pre-aggregation engine (per-developer + infrastructure). dbt-centric BI estates lean dbt SL; product teams building data apps lean Cube.
Which is cheapest?
Depends which meter your usage hits: dbt SL taxes query volume, Cube taxes team size and uptime ($37,200/yr Vendr median), AtScale taxes model richness ($30K-84K/yr floors, unlimited users/queries). High-headcount BI favors AtScale's model; small dev teams favor Cube; modest query volume favors dbt SL. AI agents querying continuously stress all three meters.
Do any of them work across multiple warehouses?
Each connects to many warehouses, but a model resolves against one platform at a time - none compiles a single question across entities in different warehouses. Cross-estate questions need a layer designed for multi-warehouse compilation.
Which is best for AI agents?
All three now ship AI features on the same foundation: a hand-authored artifact. For agent workloads, test who maintains the model under drift, whether governance is compile-time, and whether the layer models entities and relationships or just metrics. Those three tests are where graph-shaped, autonomously maintained layers differ. For deeper comparison of deterministic approaches in enterprise deployments, see Deterministic vs Probabilistic Text-to-SQL.
Can they be combined?
Commonly - dbt transformations under Cube or AtScale is a standard stack. Watch for semantic drift between layers; SML's open-sourcing, the OSI initiative, and ingestion-based seeding (Colrows ingests dbt, Cube, and SML definitions) are the current portability answers.
A note on the claims
Pricing, plan names, constraints, and quotes reflect the vendors' published pages, documentation, and attributed marketplace/review sources as of 12 June 2026 - they are the sources' claims, reported with attribution, and all three vendors ship changes frequently. Colrows is our product; the incumbents' strengths are stated above and the sources let you check our characterizations. This page is reviewed quarterly.