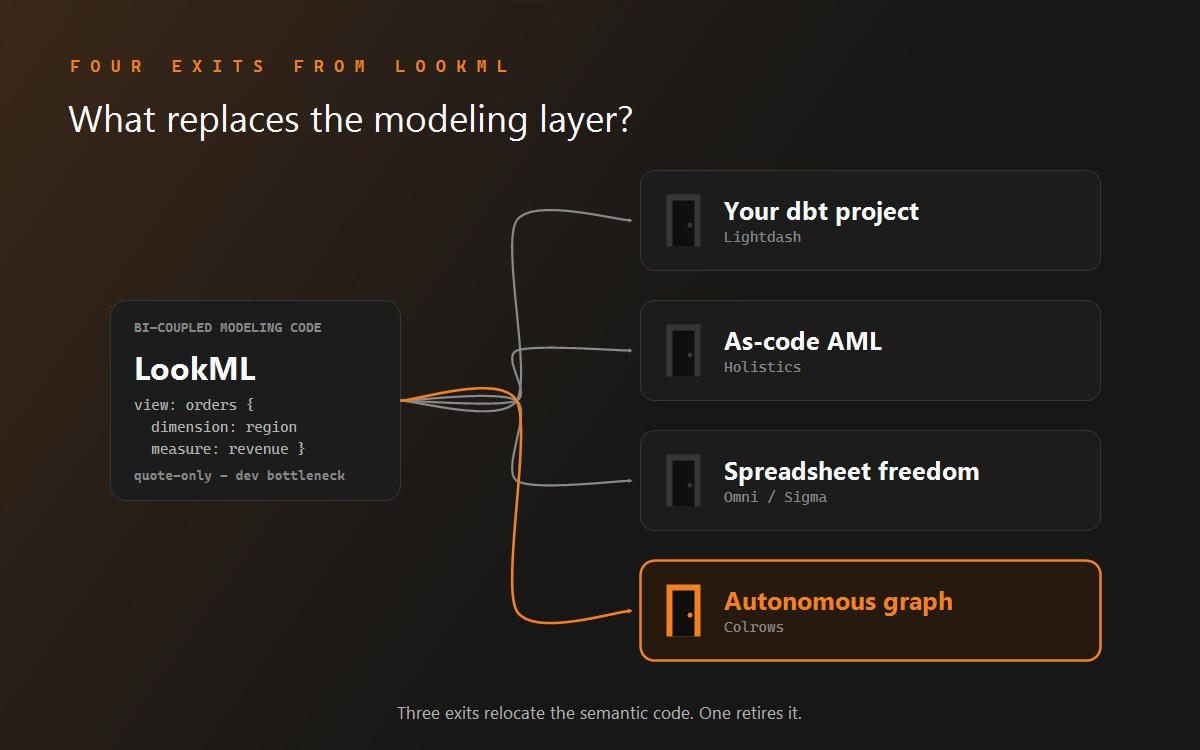
Three generations of the same idea
All three architectures agree on the founding insight - business meaning should be defined once, explicitly, instead of re-implemented in every query. They disagree about where that definition lives and who keeps it alive.
Generation one: LookML (2012). Views, explores, measures, and access grants written in Looker's modeling language, resolved at presentation time inside Looker's runtime. Its genuine achievement: it made "governed self-service" real for a decade - analysts explore freely, definitions stay consistent, and access_filter scopes what each user sees. Its structural property: the semantics are inside one BI product. Every other consumer - another BI tool, a notebook, an API, an AI agent - either goes through Looker or goes without.
Generation two: the dbt Semantic Layer / MetricFlow (2022+). Entities, dimensions, and measures in YAML beside your dbt models, resolved by MetricFlow and served tool-agnostically to a list of integrations and APIs. Its achievement: metrics escaped the BI tool. Its structural properties: it requires the dbt platform (Core users can author but not query), it is metric-shaped rather than entity-graph-shaped, and the YAML is still entirely hand-authored - with documented constraints like the mandatory time spine and a single global namespace across the project.
Generation three: the compiled semantic layer. A typed semantic graph - entities, relationships, metrics, policies, multi-scope - that questions compile against deterministically, with governance enforced at compile time and join paths proven before SQL emits. In Colrows' implementation the graph is also built autonomously from the estate and maintained with drift detection. The defining shift: semantic code stops being a thing your team writes and starts being a thing your infrastructure generates, versions, and verifies.
Side by side
| Dimension | LookML | dbt Semantic Layer | Compiled semantic layer (Colrows) |
|---|---|---|---|
| Coupled to | Looker (Google Cloud) | dbt platform + transformations | The warehouses themselves |
| Authored by | LookML developers | Analytics engineers (YAML) | Built autonomously; humans review and override |
| Resolution point | Presentation time, in Looker's runtime | Query time, in MetricFlow | Compile time, before SQL exists |
| Shape | Views + explores (BI-exploration-shaped) | Metrics + entities (metric-shaped) | Typed graph: entities, relationships, policies |
| Governance | access_filter / access_grant in the BI layer | Warehouse policies + platform permissions | Compile-time RBAC + ABAC + row/column predicates |
| Maintenance under drift | Manual - validator slows as projects grow (consultant reports) | Manual - "defining metrics was just plain hard" (dbt's own PM) | Drift detection proposes updates autonomously |
| AI surface | Gemini / Conversational Analytics, grounded in LookML | MCP and AI integrations over MetricFlow | Agent-native: HTTP, JDBC, MCP through one compile pipeline |
| Pricing shape (Jun 2026) | Quote-only platform + per-user (no published list) | $100/user/mo Starter + queried-metrics meter | Free tier; Enterprise custom |
The axis that decides it: who maintains the code
Feature tables hide the real cost line, so name it directly: semantic code is a living codebase, and its maintenance scales with your business, not with your tooling.
The public record on generation one is consistent: G2 reviewers describe Looker's "steep learning curve, especially when working with LookML," and Gartner Peer Insights reviewers report that data requests "still bottleneck with the engineering team" - the governed-self-service promise, rationed by a developer queue. Generation two moved the queue rather than removing it: dbt Labs' own product manager for the spec wrote in January 2026 that "we've heard from numerous community members over the years that defining metrics was just plain hard" - deep YAML nesting, fragmentation across files, redundant duplication. Both generations also share the quieter failure mode: when schemas drift, nothing in either system notices that a definition has gone stale. The code review that protects software does not run against reality.
This is the specific problem generation three exists to remove. If the graph is constructed from the estate - schemas, usage, documentation, ingested LookML and MetricFlow definitions - and drift detection keeps it current, the maintenance line stops scaling with concept count. The honest counterweight: autonomous construction is newer and less battle-tested than a decade of LookML projects, and teams with strong existing LookML or MetricFlow practices have working assets worth keeping - which is why ingestion, not rewriting, is the sane migration path.
Migration paths, practically
- LookML → dbt SL is a real motion (it is what "looker to dbt semantic layer" searches are about): metric and dimension definitions translate into MetricFlow YAML and escape the single-BI boundary. What does not come along: explores, drill configurations, Liquid templating, and Looker's exploration UX - dbt SL is an API, not a BI tool, so the visualization question reopens.
- Either → compiled layer: both artifacts are excellent seeds. Colrows ingests LookML views/explores/access grants and MetricFlow
semantic_modelsYAML to bootstrap its graph, then extends autonomously into the entities, relationships, and policies neither spec models. Investment carries forward; the backlog does not. - Coexistence is the common end state: Looker keeps serving dashboards it is genuinely good at; the compiled layer serves conversational analytics and AI agents above the same warehouses.
The AI consumer changes the grading
For human analysts, all three generations work - pick by ecosystem and budget. AI agents grade differently, on exactly the properties the generations diverge on: agents traverse entities and relationships (metric-shaped layers hit their ceiling - dbt's own benchmark scored 0% on questions with too many entity hops, erroring honestly); agents stress governance at machine volume (compile-time enforcement beats per-session BI filters); and agents ask long-tail questions on day one (coverage backlogs that humans tolerate, agents expose immediately). Both Google and dbt see this - Gemini grounds in LookML, dbt ships MCP - and both are bounded by the same hand-authored coverage underneath. The framework for evaluating that boundary is in Deterministic vs Probabilistic Text-to-SQL; the three-way platform comparison with pricing detail is in dbt Semantic Layer vs Cube vs AtScale; and the resolution-point distinction in the table above (presentation time vs. query time vs. compile time) is unpacked fully in semantic layer vs. semantic execution layer.
Generation one put semantics in the BI tool. Generation two put them next to the transformations. Generation three stops asking your team to write them at all. Above the warehouse. Below the prompt.
Frequently asked questions
What is the difference between LookML and the dbt Semantic Layer?
Both are hand-authored semantic code with different homes: LookML lives inside Looker and resolves at presentation time for Looker consumers; MetricFlow YAML lives beside dbt transformations and serves metrics tool-agnostically through APIs and a list of BI integrations. LookML is deeper but single-platform; dbt SL is portable but metric-shaped and platform-plan-gated.
Can I replace LookML with the dbt Semantic Layer?
The metric layer, largely yes - definitions translate to MetricFlow YAML. The exploration UX, no - dbt SL is an API, so the BI-tool question reopens. Plan it as two decisions, not one.
What is a compiled semantic layer?
One where questions compile deterministically against a typed semantic graph - entities, relationships, metrics, policies - with compile-time governance and join path proof, and (in Colrows' case) where the graph builds and maintains itself with drift detection instead of living on a developer backlog.
Which is best for AI agents?
Agents need graph traversal, compile-time governance, and coverage that does not wait on a backlog - the three properties that separate generation three from the first two. LookML-grounded Gemini and MetricFlow-over-MCP are real but inherit hand-authored coverage.
A note on the claims
Quotes and constraints reflect the cited dbt documentation and blog, Google Cloud pages, and attributed G2/Gartner reviewer summaries as of 12 June 2026 - the sources' claims, reported with attribution. Colrows is our product; the first two generations' real strengths are stated above. This page is reviewed quarterly.