How to use this
Three rules make the checklist work. First, demand demonstrations, not assertions. "Yes, we have audit logs" is an assertion; "here is the audit record for this answer, now reproduce the answer from it" is a demonstration. Second, run every accuracy question against your schemas, not the vendor's demo dataset. The published record is unambiguous on why: frontier models score 86-91% on the clean academic Spider 1.0 benchmark and 10-21% on Spider 2.0's real enterprise tasks - the demo dataset is the easy half of the exam (the full cliff, with sources). Third, weight the dimensions for your risk profile before the first call, so a charismatic demo can't re-weight them for you. A regulated BFSI buyer might weight governance and audit at half the total; a startup analytics team might weight cost shape and time-to-value.
Disclosure, because it shapes the document: Colrows is our product, and we sell against this checklist. We have kept every question vendor-neutral - they are the questions we believe any serious buyer should ask everyone, including us.
Dimension 1: Who builds the semantic model? (Questions 1-6)
The semantic model is where natural-language accuracy comes from - and in most products, it is hand-built. This is the largest cost in the deployment and the least likely to appear in the quote.
- Who authors the initial semantic model - your software or my team? Follow-up: in your three most recent reference deployments, how many person-weeks did initial modeling take?
- What does the model ingest automatically? Warehouse schemas only, or also catalogs (Alation, Atlan, Collibra), BI metric stores (Power BI, dbt), and documentation (Confluence, wikis, PDFs)?
- How does the model represent relationships - joins, hierarchies, synonyms, business definitions? A flat list of metrics is not a semantic model; multi-hop questions need a graph.
- Can the model hold different meanings for different scopes? "Revenue" can legitimately differ between global finance and a regional sales team - ask how the product scopes definitions (Colrows's graph, for reference, is multi-scope: global → datastore → persona → user).
- Is the model versioned? Follow-up: show me a diff between two versions, and roll one back.
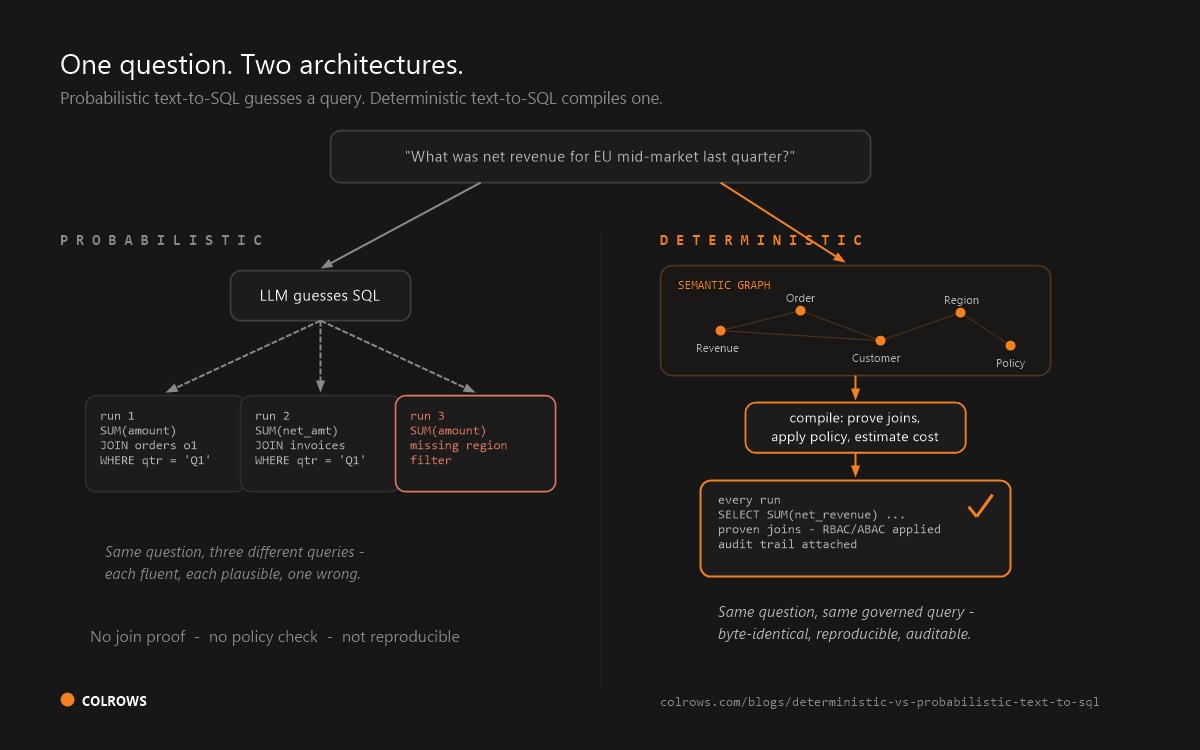
- What happens to questions the model cannot resolve? The two honest answers are "loud failure" or "best-effort guess, flagged." The dangerous answer is a confident guess, unflagged - the failure mode documented across probabilistic text-to-SQL.
Dimension 2: Who maintains it? (Questions 7-11)
Schemas change, metrics get redefined, sources get added. A semantic model that was right in March and unmaintained since is a liability that looks like an asset - we wrote up the decay mechanics in Knowledge Drift and Semantic Decay.
- How does the product detect that the warehouse has drifted from the model? Statistical drift detection and structural diffing, or a human noticing wrong numbers?
- When drift is detected, who fixes it? Autonomous maintenance with review, or a ticket to my data team?
- What is the vendor-recommended ongoing staffing for the semantic model? Get it in writing; this is the recurring line item that procurement data never captures.
- How are conflicting definitions resolved when two sources disagree?
- When a schema change breaks a definition, what do users see? An error naming the broken concept, or silently wrong numbers until someone audits?
Dimension 3: Accuracy and determinism (Questions 12-17)
This is the dimension to test, not discuss. Bring 30-50 questions with known correct answers against your own data.
- If I ask the same question twice, do I get the same SQL? The single highest-signal question in the document. Microsoft, for example, documents Power BI Copilot's outputs as nondeterministic; vendors whose architecture compiles rather than generates can answer yes flatly.
- Show me the exact query behind this answer. If the answer is a narrative without an inspectable query, see our list of tools that show their SQL for why this is disqualifying for audit-bound deployments.
- How are joins chosen - proven against known paths, or inferred per query? A join path proof is checkable; an inference is a probability.
- What is your measured accuracy, on what benchmark, and who ran it? Vendor-internal numbers (Snowflake's 90%+ on 150 internal questions, Databricks's 32→90% curation arc) are informative but not comparable; your POC is the benchmark that matters.
- In the POC, count loud failures separately from wrong answers. "I cannot resolve this" is a safety feature; a fluent wrong answer is the most expensive output the system can produce.
- Test ambiguity deliberately. Ask "what was revenue last quarter?" where two definitions of revenue exist, and watch whether the system asks, picks silently, or fails loudly.
Dimension 4: Governance (Questions 18-23)
The architectural question underneath all six: is policy enforced before the query runs (compile time) or after the data is fetched (render time)? The difference is whether a policy bug is an incident or a near-miss - argued in full in Governance as Code → Governance as Semantics.
- Where is access policy enforced - in the generated query plan, in the warehouse, or in the presentation layer?
- Does the product support RBAC, ABAC, and row/column-level predicates - and can one answer combine all three?
- Show me the same question asked by two users with different entitlements. The SQL itself should differ, not just the rendered rows.
- Can a policy change be applied without rebuilding semantic definitions?
- How do AI-agent queries inherit governance? If agents use a service account with broad read access, every agent answer is a potential exfiltration path.
- Whose credentials execute a shared query? Ask specifically - at least one major platform documents that shared AI spaces can run on the authoring user's credentials.
Dimension 5: Audit and reproducibility (Questions 24-28)
For regulated buyers this dimension is pass/fail. The bar - drawn from RBI, Federal Reserve, and EU AI Act expectations - is documented in Auditable SQL for Regulated Industries.
- For any historical answer, can you produce: the question, the resolved meaning, the exact SQL, the policies applied, and the data version?
- Is the answer point-in-time reproducible? Follow-up, the demonstration version: reproduce this answer from last month's audit record, now.
- Are the semantic definitions themselves versioned in the audit trail? "Revenue" may have been redefined since the answer was given; the trail must capture which definition applied.
- Can audit records be exported to my SIEM/GRC tooling?
- What does the auditor see for an AI-agent query versus a human query? The honest target is: no difference.
Dimension 6: AI-agent readiness (Questions 29-34)
If the roadmap includes agents - and every 2026 roadmap does - the semantic layer is the context they will stand on. A layer built only for dashboards will need replacing; the criteria are expanded in Best Semantic Layer for AI Agents.
- Is there a programmatic interface - API, MCP - that gives agents the same governed access humans get?
- Can an agent's query be constrained by the agent's own entitlements, distinct from its operator's?
- What context does the layer return besides data - definitions, lineage, confidence, provenance? Agents compose answers; they need the metadata, not just the rows.
- How does the layer handle multi-hop agent questions that no dashboard anticipated? Static metric stores stop here; graphs with proven join paths do not.
- What stops an agent from issuing a runaway query? Cost guards at compile time, or the warehouse bill three weeks later?
- Does agent traffic share the audit trail (see Q28) and the governance model (see Q22)? Circle back deliberately - vendors who answered those well for humans sometimes carve agents out.
Dimension 7: Cost shape (Questions 35-40)
Not "what does it cost" - "what shape does the cost take as we scale?" The published-price layer of this market is thin and the meters are creative; our teardowns of ThoughtSpot, Power BI Copilot, and Looker pricing supply the worked examples.
- What is metered - seats, queries, capacity, tokens, rows? Each meter taxes a different behaviour; know which behaviour of yours grows fastest.
- Is the AI feature gated behind a platform tier? Power BI Copilot requires paid Fabric capacity (F2 from $262.80/month) regardless of per-user licenses; Looker meters Gemini Data Tokens with overage billing from 1 October 2026.
- What happens when the meter runs out mid-month? Throttling, overage billing, or - as Fabric documents it - operations shutting down until the capacity recovers?
- What did implementation cost in your last three reference deployments? Enterprise BI procurement data puts implementation at 15-40% of first-year subscription value.
- What is the all-in modeling labour - initial build plus annual maintenance - at my schema scale? This is Dimension 1 and 2 priced in headcount; for most hand-modeled products it exceeds the license.
- What does the renewal look like? Ask for the median uplift across the current customer base, in writing.
The one-page scorecard
| Dimension | Questions | Pass looks like | Walk away if |
|---|---|---|---|
| 1. Model construction | 1-6 | Autonomous build from warehouse + catalogs + docs; versioned, scoped graph | "Your team authors the model" with no person-week estimate |
| 2. Maintenance & drift | 7-11 | Drift detection + autonomous maintenance; loud breakage | Maintenance is a ticket queue; breakage is silent |
| 3. Accuracy & determinism | 12-17 | Same question → same SQL; inspectable queries; loud failure | Nondeterminism is documented and unmitigated |
| 4. Governance | 18-23 | Compile-time RBAC + ABAC + row/column predicates; agents inherit policy | Policy lives in the presentation layer |
| 5. Audit & reproducibility | 24-28 | Point-in-time reproducible answers; versioned definitions in the trail | "We have logs" without a reproduction demo |
| 6. AI-agent readiness | 29-34 | Programmatic governed access; multi-hop resolution; cost guards | Agents ride a broad-access service account |
| 7. Cost shape | 35-40 | Meters you can forecast; modeling labour quoted in writing | The biggest line item (modeling) is "not our scope" |
Weight before the first call. A suggested split for regulated buyers: dimensions 3-5 at 50%, 1-2 at 30%, 6-7 at 20%. For a growth-stage analytics team: 1-3 and 7 at 70%.
Where Colrows sits, in one paragraph
Since we wrote the checklist, here is our own entry, stated so you can test it rather than trust it. Colrows is a semantic execution layer: the semantic graph is built and maintained autonomously (dimensions 1-2 - drift detection, structural diffing, conflict resolution, no curation team), every question is compiled - intent → context resolution → constrained planning → governed execution - so the same question yields the same dialect-perfect SQL with a join path proof (dimension 3), governance is compile-time RBAC + ABAC + row/column-level predicates (dimension 4), every answer is point-in-time reproducible from the audit trail (dimension 5), and agents consume the same governed pipeline humans do (dimension 6). Cost shape: a free tier to run the POC on, Enterprise custom (dimension 7 - ask us questions 38-40; we expect them). The 40 questions above are how we would want to be evaluated.
Frequently asked questions
What are the most important evaluation criteria?
Seven dimensions: who builds the model, who maintains it, accuracy and determinism, governance, audit and reproducibility, AI-agent readiness, and cost shape. The weighting is yours; the questions are above.
What should go in the RFP?
The falsifiable subset: same-question-twice determinism (Q12), the reproduce-an-answer demonstration (Q25), reference-deployment modeling headcount (Q1, Q9, Q39), and the meter-exhaustion behaviour (Q37). Demand demonstrations over assertions throughout.
How do you test accuracy claims?
A POC on your schemas with 30-50 known-answer questions, each asked twice; count loud failures separately from wrong answers. The Spider 1.0 vs 2.0 gap (86-91% vs 10-21%) is the published proof that demo-dataset performance does not transfer.
What hidden costs recur across the market?
Modeling labour (build + maintain, rarely quoted), platform gates and meters (Fabric capacity, Gemini Data Tokens), and implementation services at 15-40% of first-year subscription value. Questions 35-40 surface all three.
A note on the claims
Benchmark figures (Spider 1.0/2.0), vendor caveats (Microsoft's nondeterminism documentation, Databricks's credential note, Fabric's exhaustion behaviour), and pricing facts (Fabric F2, Gemini Data Token overage dates, implementation percentages) are sourced in the linked deep-dives, all checked 11-12 June 2026. Colrows is our product, and the disclosure above applies to the whole document: these are the questions we ask buyers to ask everyone.