| Risk vector | Probabilistic text-to-SQL | Colrows semantic layer |
|---|---|---|
| Metric drift | Models redefine calculations at runtime | Metrics locked in versioned semantic graph |
| Confused deputy | End-users bypass database access controls | Compile-time authorization blocks unauthorized reads |
| Audit failures | Opaque LLM prompts cannot be verified | Pure SQL output with permanent audit trail |
| Reproducibility | Same question, different answer (GPU nondeterminism) | Same intent, same scope, same SQL, every time |
What "auditable SQL" actually means
Auditable SQL is a query that arrives with its own evidence. Five properties:
- The exact SQL executed, retained automatically and tamper-resistant.
- The versioned definitions it compiled from. What "NPA coverage" or "net revenue" meant, on the date it was asked.
- The proven join path. Evidence the tables were related correctly, not guessed.
- The policies applied, and for whom. Which row and column rules and which roles gated the data.
- Point-in-time reproducibility. Re-run the same question against the same definitions and get the identical answer.
A logged query on its own is evidence of what ran. It is not evidence of why the answer was right. In regulated analytics, that gap is the whole problem.
Before the regulators arrive: BFSI business terms are intrinsically ambiguous
The reproducibility problem starts before any SQL is generated. In BFSI, the same business term often carries different operational meanings across core banking, loan management, CRM, collections, insurance, risk, finance, and regulatory reporting. An auditor inspecting "exposure" or "overdue" or "recovery" is reading a number that was assembled from a definition - and the definition usually has not been written down anywhere a regulator can re-execute.
| Business term | Why it becomes ambiguous in BFSI |
|---|---|
| Customer | Individual, account holder, borrower, guarantor, entity, policyholder, nominee, cardholder, merchant, or relationship group. |
| Exposure | Principal only, principal plus accrued interest and penalty, off-book exposure, guarantee exposure, or group-level aggregated exposure. |
| Overdue | Depends on due date, grace period, product type, restructuring status, and payment allocation logic. |
| Recovery | Cash collected, settlement agreed, legal recovery, asset sale proceeds, or expected recovery value. |
| Risk | Credit risk, operational risk, fraud risk, market risk, concentration risk, or regulatory risk. |
| Compliance status | Depends on policy documents, KYC state, approvals, exceptions, consent, and jurisdiction. |
The same account can look safe or risky, recovered or written-off, compliant or non-compliant - depending on which definition, source, calendar, exposure logic, and policy rule was applied. This is the layer beneath the regulatory bar. A query may execute correctly, log correctly, and still be unreproducible because the definition behind it was never versioned. That is the gap that the next nine regulatory frameworks all converge on: they each require that the meaning behind a number be reconstructable, not just the number itself.
Why hiding the SQL is a compliance liability
The appeal of conversational analytics is that it hides complexity. The risk is that it hides the query. Regulators inspect the query.
There are two structural reasons generated SQL resists audit. First, large language model execution on GPUs is nondeterministic, even when configured for deterministic output, so re-running yesterday's question does not reliably reproduce yesterday's answer, which is the core operation of an audit. Second, a generated query has no versioned definition behind it; its logic lives in a prompt and a model snapshot, neither reviewable the way a metric definition is.
dbt Labs put the asymmetry precisely in its "Semantic Layer vs. Text-to-SQL: 2026 Benchmark Update": "With text-to-SQL, failure looks like a plausible but incorrect answer. With the Semantic Layer, failure looks like an error message. For anything going to a board deck, an auditor, or a company KPI dashboard, that difference is everything."
"The AI did it" is not an audit defense. Under the EU AI Act, deployer obligations cannot be contractually transferred to a vendor or a model; regulators examine your implementation independently of your vendor's compliance status.
The regulatory bar, framework by framework
SOX 404(b): chain of custody for every number
Section 404 of the Sarbanes-Oxley Act requires management to assess internal control over financial reporting, and under 404(b) a registered external auditor must attest to and report on that assessment. SOX 404 turns financial reporting from an outcome into a process: you must demonstrate the chain of custody for every number on the balance sheet, not merely produce a correct one. A conversational system that feeds a financial dashboard inherits that burden. If it cannot reproduce a figure and show the logic that built it, the control is deficient.
GDPR Article 22 and Article 15: the logic must be explainable
Article 22 gives individuals the right not to be subject to a decision based solely on automated processing that produces legal or similarly significant effects; the regulators' guidance treats automatic refusal of an online credit application as a paradigm case. Article 15(1)(h) gives the data subject the right to "meaningful information about the logic involved" in such processing, and Article 22(3) gives the right to obtain human intervention and to contest the decision. A bank cannot meet any of this if the decision rested on a probabilistic query it cannot reconstruct.
PCI DSS Requirement 10: tamper-proof, traceable access logs
Requirement 10 of PCI DSS v4.0.1 mandates tracking and monitoring of all access to system components and cardholder data, with audit logs protected from modification, retained for at least 12 months and with 3 months immediately available. Logs must tie access to individual users. Conversational access to any schema containing cardholder data falls squarely in scope, and a query interface that does not capture who asked what, and what ran, is a finding waiting to happen.
BCBS 239: lineage and traceability for risk data
The Basel Committee's principles for effective risk data aggregation and risk reporting require accuracy, completeness, timeliness, and end-to-end data lineage. The Committee's November 2023 progress report stated that "Nearly a decade after the initial publication of the Principles... banks are at different stages in terms of alignment. Additional work is required at all banks to attain or sustain full compliance." Any risk metric a conversational system produces for a board pack or a capital calculation lives inside that lineage requirement.
MiFID II Article 17 / RTS 6: algorithm versioning and reconstruction
RTS 6, adopted under Article 17 of MiFID II, requires firms engaged in algorithmic trading to keep a detailed inventory of algorithms, describing types, owners, sign-off, and risk controls, and to perform an annual self-assessment that regulators can request at short notice. The substance of that self-assessment is versioned, reproducible logic. A model whose decisions cannot be reconstructed cannot be validated.
EU AI Act: credit scoring is high-risk and must log automatically
Annex III classifies as high-risk "AI systems intended to be used to evaluate the creditworthiness of natural persons or establish their credit score," and risk assessment and pricing in life and health insurance. Article 12 requires that high-risk systems "technically allow for the automatic recording of events (logs) over the lifetime of the system" to ensure traceability. The Annex III compliance date has been the subject of a proposed Digital Omnibus delay, but what moved is the date, not the classification. Credit AI in Europe is high-risk AI.
SR 26-2, SEC, OCC, and the FSB
In the United States, the Fed, OCC, and FDIC issued SR 26-2 in 2026, superseding the fifteen-year-old SR 11-7 on model risk management. It retains independent validation and "effective challenge," but it excludes generative and agentic AI from scope as "novel and rapidly evolving." US banks now have a refreshed framework for everything except the systems this article is about, which pushes the burden of proof onto the architecture you deploy.
The SEC has made AI a stated examination priority and has begun enforcing against misrepresentation. The OCC, in supervisory reviews summarized by the GAO, found that some banks classified AI and machine learning models as low risk, subjecting them to less frequent evaluation and "less stringent governance requirements," and that banks "provided limited information on their efforts to evaluate bias and fair lending issues." The Financial Stability Board's November 2024 report, "The Financial Stability Implications of Artificial Intelligence," names "model risk, data quality and governance" among the vulnerabilities that could increase systemic risk and calls on authorities to assess whether existing frameworks are adequate.
Three jurisdictions, one assumption: that you can document, validate, and reproduce what your models do.
What a failed audit or compliance finding costs
This exposure is not theoretical, and it has names and numbers.
- On July 10, 2024, the Federal Reserve and OCC fined Citigroup a combined $135.6 million ($60.6 million Fed civil money penalty plus $75 million from the OCC) for insufficient progress on data-quality management. The Fed stated that "Citigroup has made insufficient progress remediating its problems with data-quality management and failed to implement compensating controls to manage its ongoing risk."
- On March 14, 2024, the OCC ($250 million) and the Federal Reserve ($98.2 million) fined JPMorgan $348.2 million after the bank "failed to surveil billions of instances of trading activity on at least 30 global trading venues" between 2014 and 2023, conduct the OCC characterized as unsafe or unsound banking practices.
- On October 10, 2024, TD Bank agreed to pay approximately $3.09 billion (roughly $1.85 billion to the DOJ, $1.3 billion to FinCEN, $450 million to the OCC, and $123.5 million to the Fed), plus an asset cap, the largest Bank Secrecy Act penalty in US history, after allowing trillions of dollars in transactions to go unmonitored.
- Across the industry, global AML enforcement fines totaled $4.6 billion in 2024, per Fenergo's "AML Enforcement Action in 2024" report (published January 2025); transaction-monitoring failures accounted for $3.3 billion, and North America represented 95% of global penalties.
The SEC has also begun charging firms for misrepresenting AI. On March 18, 2024, in its first such actions, the SEC settled charges against two investment advisers for "AI washing": Delphia (USA) Inc. paid a $225,000 civil penalty and Global Predictions Inc. paid $175,000, for a total of $400,000. SEC Chair Gary Gensler said: "Investment advisers should not mislead the public by saying they are using an AI model when they are not. Such AI washing hurts investors."
The common thread across these cases is governance and data controls that could not be evidenced. The same logic generalizes uncomfortably well to AI analytics.
What banks themselves say is blocking adoption
The adoption surveys agree on where the blocker sits. McKinsey's "Embracing generative AI in credit risk," based on a survey of senior credit-risk executives at 24 financial institutions including nine of the top ten US banks, found that "the most significant barriers, highlighted by 75 percent of our respondents, concern risk and governance," with model-risk issues such as transparency, auditability, fairness, and explainability prominent among them. The industry did not stall on ambition or model quality. It stalled on the gap between what generative systems do and what regulated institutions must be able to prove.
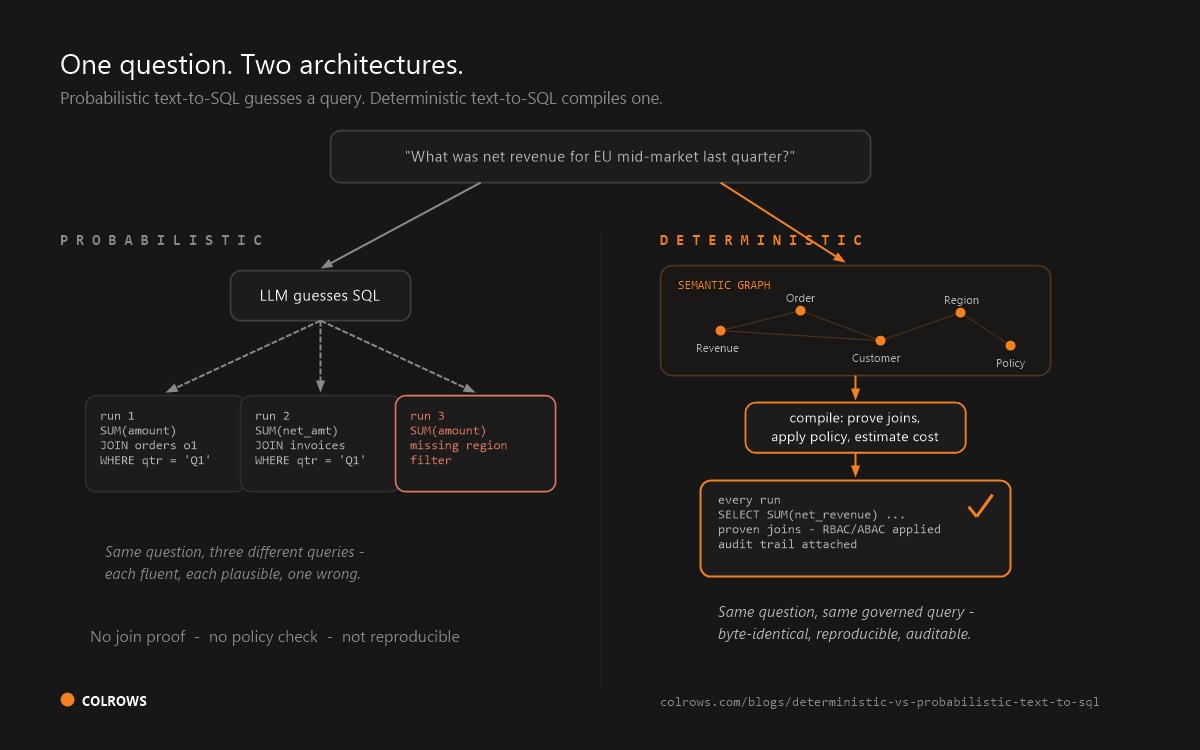
The architecture: deterministic compilation through a semantic layer
The conversational pipeline has a common shape: intent parsing, entity resolution, query planning, SQL generation, execution, result interpretation. The architecture question is where governance and meaning live.
In a generation-first design, an LLM writes SQL and governance is bolted on afterward, often as warehouse-side row-level security that the model cannot anticipate. The agent generates a query, the warehouse silently filters rows, and an incomplete result can be presented as complete. There is no proof of join validity and no record of which definition of which metric was used.
In a compilation-first design, meaning resolves against a versioned semantic graph, join paths are proven before any SQL is emitted, and access policies, RBAC, ABAC, and row and column predicates, inject at compile time so an unauthorized question fails to compile and never touches data. Every answer ships with dialect-perfect SQL, full lineage, and a point-in-time reproducible trail. This is deterministic compilation through a semantic graph, where governance belongs at compile time, before a single row is read.
The five planks of auditable SQL are properties of a compiler, not of a model. A deterministic compiler gives you the trail, the versioned definitions, and the reproducibility as a byproduct of how compilation works, where a generative system must approximate each one with bolted-on machinery the regulator then asks you to validate too. See how compile-time data access control works in practice.
Fix the context, not the model. A better LLM does not fix metric drift, the confused-deputy problem, or GPU nondeterminism. A versioned semantic graph that locks definitions, proves joins, and injects access policies at compile time does. The audit trail is a byproduct of correct architecture, not an afterthought bolted onto a probabilistic generator.
How the platforms compare
| Platform | SQL generation | Auditable (lineage, versioning, reproducibility) | Machine-readable trail | Regulator can reproduce? |
|---|---|---|---|---|
| Power BI Copilot | Probabilistic; LLM + RAG on Fabric semantic model | Purview logs prompt, DAX, rows; known RLS-bypass risk noted by integrators | Yes (Purview) | Partial; generation nondeterministic |
| Databricks AI/BI Genie | Probabilistic compound AI; "certified answers" pin trusted logic | Unity Catalog lineage, governance, query history | Yes (Unity Catalog) | Partial; certified > free-form |
| Looker Conversational Analytics | Maps to LookML; Fast mode near-deterministic | LookML version-controlled; permissions via JDBC | Yes | Stronger in Fast mode / governed LookML |
| Snowflake Cortex Analyst | Probabilistic; grounded by Semantic Views | Semantic Views (metadata); request logs + OpenTelemetry event tables; RBAC | Yes | Partial; SQL logged, regeneration not guaranteed |
| Cube | Agents query semantic layer; policies applied deterministically pre-warehouse | Model + policies as code; version control, CI | Yes (MCP + APIs) | Stronger; governed surface |
| Tableau Pulse / Einstein | Narrative insights + calc generation; not conversational SQL per se | Einstein/Agentforce Trust Layer | Partial | Weak for SQL-decision reproduction |
| Qlik Answers | NL over associative engine; governed data products | Explainability with source citations; MCP | Yes | Partial; depends on governed model |
| Colrows | Deterministic compilation of intent through versioned semantic graph | Versioned definitions, proven joins, compile-time policy, point-in-time reproducibility | Yes (graph version, definitions, executed SQL, identity) | Yes, by design |
The honest summary: every serious platform now grounds conversational analytics in a semantic model, and grounding improves both accuracy and governance. The differentiator is whether the SQL is produced deterministically from versioned definitions, or generated probabilistically and logged after the fact. Looker's Fast mode and Cube sit closest to the deterministic end among incumbents; the head-to-head detail behind every row of this table is in the platform comparison hub, including the full Power BI Copilot analysis.
Where Colrows fits
Colrows is a semantic execution layer for enterprise AI. Governance is a compilation pass: RBAC, ABAC, and row and column predicates are evaluated before SQL is emitted, so unauthorized intent fails compilation and data is never read. Policies apply before the SQL exists, not after. This is why conversational analytics for regulated data works the same way across BFSI, healthcare, and other compliance-heavy domains.
Every conversation, from a credit officer's chatbot, an LLM, or an autonomous agent, leaves an auditable SQL trail carrying the semantic graph version, the definitions used, the proven join path, the policies applied, the identity context, and the executed SQL, with point-in-time reproducibility. Conversational clients consume that deterministic layer through an MCP server and HTTP/JDBC APIs, so the same governed surface answers the same question the same way regardless of who, or what, asks. The next agent asking the same question in the same scope gets the same answer, because the compiler is deterministic. Read the ARC case study to see how a Confidential ARC deployment cut evaluation cycle time by more than 95% with 100% regulatory coverage across RBI SARFAESI and DRT requirements.
Beyond audit: the same architecture covers risk and recovery
The case made in this article is framed around audit because that is where the regulatory teeth are. But the underlying architecture, deterministic compilation through a versioned semantic graph, is not a single-purpose audit feature. It is the same operational substrate that risk and recovery teams need, for the same definitional reasons.
Risk: standardizing exposure, delinquency, and risk signals
A risk dashboard asks for "high-exposure borrowers with increasing delinquency this quarter." Without a governed semantic layer, one team uses principal outstanding, another includes interest and penalty, a third reports customer-level exposure while risk expects group-level exposure. DPD buckets, SMA classification, collateral coverage ratios, and watchlist rules drift the same way. With a compilation-first layer, "exposure," "borrower group," "delinquency movement," and "risk band" resolve against versioned definitions before any SQL is emitted, so a risk number that lands in a board pack carries the same audit trail as a number that lands in a regulatory filing. The five planks of auditable SQL apply identically.
Recovery: connecting actions, promises, settlements, and outcomes
A collections head asks "which accounts should we prioritize this week?" A raw dashboard sorts only by overdue amount. A defensible answer requires exposure, aging, customer response history, collateral value, legal stage, prior promises, agency performance, and expected recovery, each with a governed definition. Recovery rate alone has at least five legitimate interpretations: cash collected, settlement agreed, legal recovery, asset sale proceeds, or expected recovery value. Compile-time governance gives each interpretation a name, a version, and a reproducible trail. The same architecture that lets you defend a board number also lets you defend a prioritization decision a regulator might later ask about.
For asset reconstruction companies operating under RBI SARFAESI and Debts Recovery Tribunal regimes, this is not a nice-to-have. The deployment outlined in our Confidential ARC case study cut evaluation cycle time by more than 95% precisely because recovery decisions, like audit answers, compiled through a single governed semantic surface.
High-value BFSI use cases for governed conversational analytics
If you are scoping where to deploy auditable, semantic-layer-backed conversational analytics first, the highest-value starting points are the surfaces where definitions are most disputed, regulatory exposure is highest, or audit evidence is most expensive to produce manually.
| Use case | What the semantic layer standardizes | Why it is high-value |
|---|---|---|
| Portfolio risk review | Exposure, delinquency, DPD bucket, risk band, borrower group, collateral coverage, watchlist logic. | BCBS 239 lineage; board-pack defensibility. |
| Recovery prioritization | Overdue amount, recovery probability, settlement status, legal stage, agency assignment, recovery rate. | RBI SARFAESI / DRT defensibility; operational ROI. |
| Compliance reporting | Approved definitions, reporting filters, sensitive-data controls, lineage, evidence trails. | SOX 404(b), BCBS 239, MiFID II RTS 6 obligations. |
| Audit evidence generation | Definition version, source lineage, query path, access policy, historical reproducibility. | Cost of manual audit pack production; PCI DSS Req. 10. |
| Claims analytics | Policy, claim, loss ratio, reserve, settlement, fraud signal, product definitions. | EU AI Act high-risk insurance pricing; loss reserving accuracy. |
| Customer 360 for regulated workflows | Customer identity, relationship graph, consent, access scope, product holdings, sensitive fields. | GDPR Article 22 explainability; KYC audit trails. |
| AI agents for BFSI analytics | Natural-language questions resolved through governed metrics, relationships, and access rules. | SR 26-2 model risk; the burden of proof the regulators put on architecture. |
The pattern across all seven: the value is not the conversational interface itself. The value is that the interface produces answers a CCO, an internal auditor, or a regulator can reproduce on demand. Use case prioritization should follow regulatory exposure first, manual-audit cost second, and definitional dispute third.
Recommendations
Stage 1: Inventory and map (weeks 1 to 4). List every conversational or AI analytics surface that touches regulated data. Map each against the frameworks that apply to it: SOX 404(b) for anything feeding financial statements, GDPR Art. 22/15 for anything influencing a customer decision, PCI DSS Req. 10 for cardholder-data schemas, BCBS 239 for risk metrics, MiFID II RTS 6 for trading models, and the EU AI Act for credit scoring and insurance pricing. Any surface with no Article 12-style automatic log is a remediation item.
Stage 2: Test reproducibility (weeks 4 to 8). For each surface, ask the same question twice, separated in time, and confirm you get identical SQL and identical results. If you cannot reproduce the answer, you cannot defend it. Treat non-reproducibility as a blocker to production scaling, not a footnote.
Stage 3: Decide the architecture (weeks 8 to 12). For decisions that are reported, regulated, or customer-affecting, prefer deterministic compilation from versioned definitions over probabilistic generation with after-the-fact logging. For low-stakes internal exploration, generation-first tools are fine. The threshold that should change your decision: if an answer can land in a board pack, a regulatory filing, a credit decision, or a capital calculation, it needs a reproducible, versioned, policy-gated trail.
Conclusion
Regulators differ in vocabulary and timeline, but they ask one question in unison: can you prove it? Generation answers with confidence. Compilation answers with a trail. If you are evaluating conversational analytics for a regulated workload, the question to put to your tech team, and to every vendor, is simple: prove the query, then run it. See how a semantic execution layer makes that the default rather than an afterthought.
Frequently asked questions
What is auditable SQL?
Auditable SQL is a query that carries its own evidence: the exact SQL executed, the versioned definitions it compiled from, the proven join path, the policies applied and for whom, and point-in-time reproducibility. It is the difference between an answer and a defensible one.
Why is LLM-generated SQL hard to audit?
Two reasons. Architecturally, a generated query has no versioned definition behind it, only a prompt and a model snapshot. Physically, LLM execution on GPUs is nondeterministic even when configured for deterministic output, so re-running yesterday's question does not reliably reproduce yesterday's answer, which is the core operation of an audit.
Does conversational analytics comply with GDPR's right to explanation?
It can, but only if the logic is reconstructable. GDPR Article 15(1)(h) requires meaningful information about the logic involved in automated decisions covered by Article 22, and Article 22(3) gives the right to contest them. A decision built on a query you cannot reproduce cannot be explained or contested.
What does SOX 404(b) require of analytics systems?
SOX 404(b) requires an external auditor to attest to the effectiveness of internal control over financial reporting. In practice, any system that produces numbers feeding financial statements must demonstrate the chain of custody for each figure and reproduce it on demand.
Can a regulator reproduce a decision made via conversational analytics?
Only if the system retains the executed SQL, the versioned definitions behind it, and can re-execute at a point in time to yield the identical result. Deterministic compilation provides this by design; probabilistic generation provides a log of what ran but not a guarantee of identical regeneration.
How do Power BI Copilot, Databricks, Snowflake, and Looker handle audit?
All ground conversational analytics in a semantic model and provide machine-readable logs (Microsoft Purview, Databricks Unity Catalog, Snowflake's Cortex Analyst request logs, Looker's LookML and permissions). They differ in determinism: Looker's Fast mode maps directly to governed LookML, while Power BI Copilot, Cortex Analyst, and free-form Databricks Genie generate probabilistically and log after the fact.
What does a failed data-governance audit cost a bank?
Recent examples: Citigroup paid $135.6 million in July 2024 for data-quality management deficiencies, JPMorgan paid $348.2 million in March 2024 for trade-surveillance data gaps, and TD Bank paid roughly $3.09 billion in October 2024 for monitoring failures. Global AML fines reached $4.6 billion in 2024, with $3.3 billion tied to monitoring failures.
How does Colrows make conversational analytics auditable?
Colrows compiles natural-language intent deterministically through a versioned semantic graph. It proves join paths before emitting SQL, applies RBAC, ABAC, and row and column policies at compile time, and attaches a structured audit trail (graph version, definitions used, executed SQL, identity context) to every answer. The same intent in the same scope produces the same SQL and the same result, every time.
How does a semantic layer ensure compliance in financial conversational analytics?
It acts as a deterministic translation plane. The AI agent interacts with predefined, versioned business definitions rather than writing raw database queries. Every metric (exposure, recovery rate, delinquency) resolves against the semantic graph before any SQL is emitted. The result is governed, reproducible, and carries its own audit trail. No definition drift. No hallucinated joins. No runtime redefinition of what a number means.
Can conversational BI tools prevent data leaks at the schema level?
Standard BI tools apply security too late. They filter results after retrieval, meaning the warehouse already read unauthorized data. True prevention requires security injection at compile time, before the query hits the data warehouse. In a compilation-first architecture, RBAC, ABAC, and row/column-level predicates evaluate during query planning. An unauthorized question fails compilation and never touches data. The confused-deputy problem disappears because the compiler knows who is asking and what they are allowed to see.
Sources and fact verification
Benchmark figures, vendor documentation, and the competitive landscape reference primary sources (arXiv papers, vendor docs, Gartner, SEC, OCC, Federal Reserve, BIS, ECB, EU AI Act) current as of 12 June 2026. Regulatory quotes are verified against official texts linked inline. Enforcement figures (Citigroup $135.6M, JPMorgan $348.2M, TD Bank $3.09B, SEC AI-washing cases, global AML fines $4.6B) are from official agency releases and industry reports. McKinsey and EY-Parthenon survey figures are the publishers' claims about their own samples. The EU AI Act Annex III compliance timeline reflects a provisional political agreement (May 2026 Digital Omnibus) not yet in the Official Journal. This page is reviewed quarterly.