How we scored
Two axes, five points each, with the reasoning shown so you can re-score with your own weights.
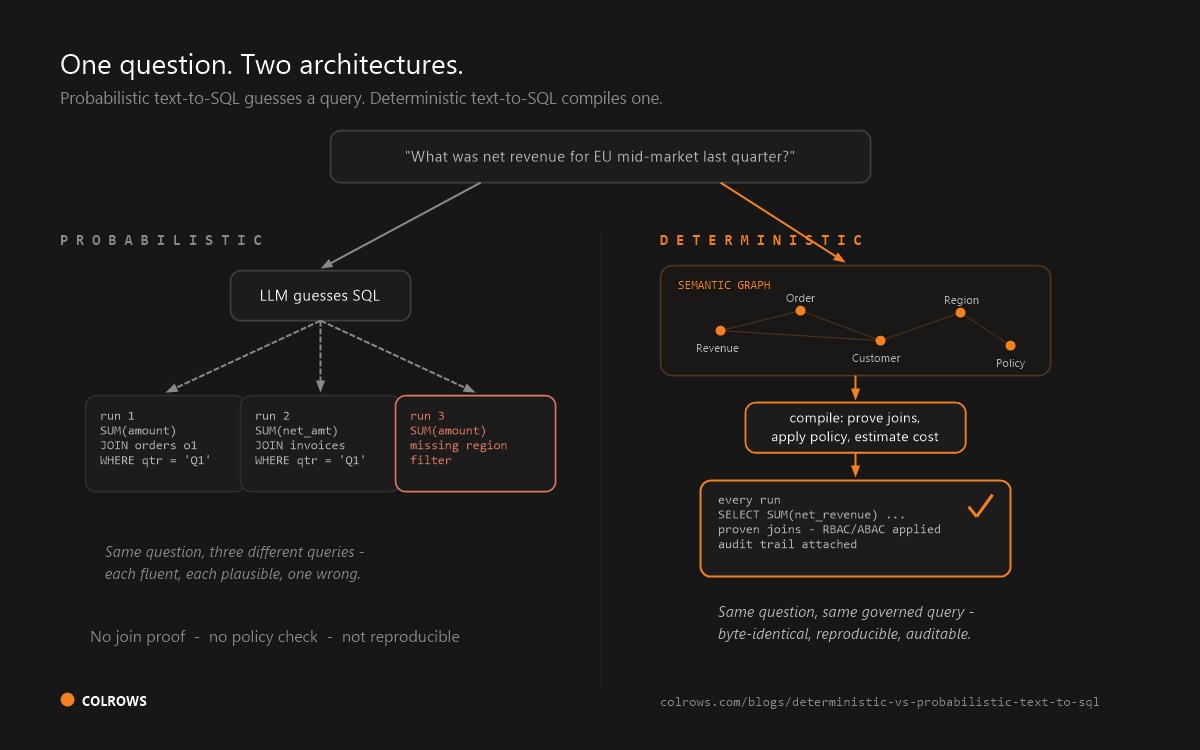
Accuracy (out of 5). Not "does it feel smart" - what does the published record say? The baseline matters here: the Spider 2.0 benchmark reports frontier models solving 10-21% of real enterprise SQL tasks, versus 86-91% on the academic Spider 1.0 - a cliff we dissected in The Text-to-SQL Accuracy Cliff. Tools earn points for grounding generation in explicit semantic structure, for showing their SQL so errors are catchable, for determinism, and lose them for documented warnings about wrong answers.
Governance (out of 5). Where is access policy enforced - before the query runs or after the dashboard renders? Does the tool produce an audit trail an examiner would accept? Can it answer "what did the system know when it gave this answer?" Regulated buyers should read this column first; the regulatory case is laid out in Auditable SQL for Regulated Industries.
One disclosure before the list: Colrows is our product. It is scored by the same rubric, and every claim about the other eight tools cites the vendor's own documentation or attributed third-party data, so the list stays useful even if you discount our entry.
1. Colrows (our product) - Accuracy 5, Governance 5
Best for: regulated enterprises (BFSI, healthcare, retail) that need conversational analytics and AI agents to be provably correct, not plausibly correct.
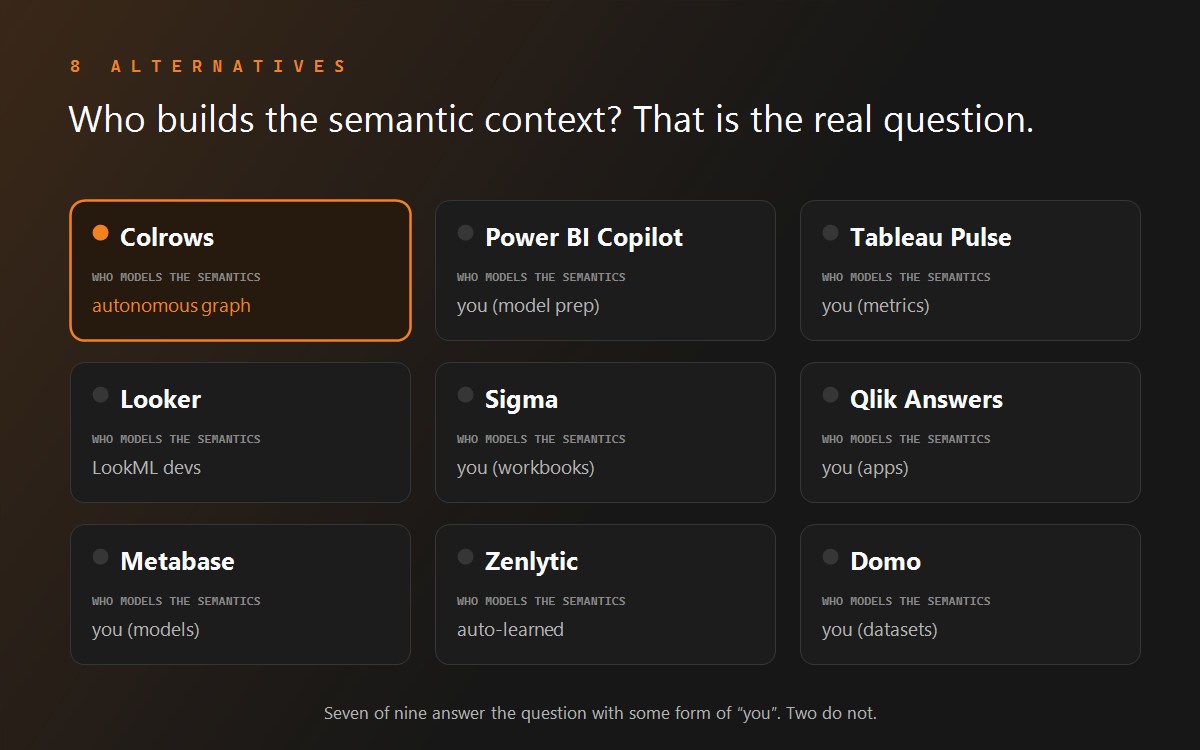
Colrows takes the position that the accuracy problem is architectural: a probabilistic model guessing SQL will always have a failure rate, so don't let it guess. It is a semantic execution layer that autonomously builds a semantic graph - versioned, typed, multi-scope - across the data estate, then runs every question through a compile-then-execute pipeline: intent → context resolution → constrained planning → governed execution. Every join carries a join path proof, the SQL is deterministic and dialect-perfect across 16+ engines, and a question that cannot be resolved fails loudly at compile time instead of returning a fluent wrong answer. Governance is compile-time - RBAC + ABAC + row/column-level predicates enforced before a byte is fetched - and every answer is point-in-time reproducible from the audit trail. Autonomous drift detection maintains the graph as schemas change, which is the line item that quietly dominates every other tool's TCO. In production at Cipla (8× data adoption, >90% decision-latency reduction) and a confidential ARC (>95% reduction in evaluation cycle time, 100% regulatory coverage across RBI SARFAESI + DRT workflows). Pricing: free tier plus custom Enterprise. Honest trade-off: a young vendor versus the platforms below - which is why the scoring rationale is shown, not asserted.
2. Snowflake Cortex Analyst - Accuracy 4, Governance 4
Best for: Snowflake-committed estates that want governed natural-language answers over curated subject areas.
Cortex Analyst is the strongest evidence in the market that semantic structure - not model size - drives accuracy. Snowflake's own engineering account reports text-to-SQL accuracy improving from roughly 51% to 90%+ on an internal 150-question benchmark once questions were grounded in hand-authored semantic models (now semantic views). It returns the generated SQL with each answer, runs inside Snowflake's perimeter, and inherits warehouse RBAC and masking policies - a genuinely good governance story. The costs are the mirror image: someone must author and maintain those semantic views per subject area (the modeling tax, itemized in our Cortex Analyst vs Genie comparison), the generation step is still probabilistic underneath the grounding, and it only speaks Snowflake. Billing is consumption-based against Snowflake compute.
3. Databricks AI/BI Genie - Accuracy 3.5, Governance 4
Best for: Databricks shops that want curated chat experiences over Unity Catalog data.
Genie organizes conversational analytics into "spaces" - curated bundles of tables (Databricks recommends keeping spaces focused; its docs use guidance on the order of dozens of tables, not thousands), instructions, and example queries. It shows the SQL behind each answer and inherits Unity Catalog permissions, which earns its governance score; the documented caveats are that Genie operates nondeterministically and that shared spaces can embed the author's credentials - both worth reading in Databricks's own docs before a regulated deployment. Databricks has published a case of agentic improvement on an internal benchmark (32% to ~90% with iterative curation), which is impressive and also a measure of how much curation the architecture asks of you. Per-space curation is the recurring cost; cross-estate questions hit the space boundary. We compared the two warehouse-native analysts head-to-head in Cortex Analyst vs Genie.
4. Microsoft Power BI + Copilot - Accuracy 2, Governance 3
Best for: Microsoft-stack organizations extending BI they already own - with the capacity bill and accuracy caveats budgeted.
The reach is unmatched: Power BI Pro is $14/user/month and Copilot drops into the tool your analysts already use. The two caveats come from Microsoft itself. Accuracy: the documentation states Copilot outputs are nondeterministic and warns that without serious preparation it "can struggle to interpret data correctly - leading to generic, inaccurate, or even misleading outputs" - the full diagnosis is in Why Power BI Copilot Gives Confidently Wrong Answers. Cost shape: Copilot requires paid Fabric capacity (F2 from $262.80/month; Pro or PPU licenses alone are not sufficient) and meters token consumption against that capacity - at field-reported burn rates, an F2 is functionally a demo. The arithmetic is worked through in Power BI Copilot Pricing. Governance leans on model-level security (RLS) configured per dataset - real, but enforced at the model, not compiled into the query plan.
5. Looker Conversational Analytics - Accuracy 3.5, Governance 4
Best for: Google Cloud estates with an existing LookML practice and the team to maintain it.
Looker's Gemini-powered Conversational Analytics is grounded in LookML - every metric defined once, centrally, and reused - which is the right architecture for consistency and earns its scores. The grounding is also the bottleneck: someone hand-authors and maintains that LookML, and reviewer complaints about engineering-team bottlenecks are a decade old. Two commercial facts to price in: Google publishes no platform list prices (editions are quote-only), but it does publish Gemini Data Token allowances per edition, with overage billing of $3/1M input and $20/1M output tokens effective 1 October 2026 - the AI feature is metered even though the platform price is a secret. For detailed pricing analysis, see Looker Pricing in 2026.
6. ThoughtSpot Spotter - Accuracy 3, Governance 3
Best for: organizations that want the most mature search-driven analytics UX and have a data team to feed it.
ThoughtSpot invented this category's UX, and Spotter is its agentic evolution. The two structural costs are well documented. Modeling: a Gartner Peer Insights reviewer called natural-language search "impossible without the data team doing a huge amount of up-front data modelling work" - the worksheets and curation are the product's foundation, not an option. Cost: published Essentials at $25/user/month (capped at 50 users and 25M rows), with enterprise contracts at a $92,521 Vendr median across 30 recorded purchases - the gap is dissected in ThoughtSpot Pricing Explained. Governance is solid enterprise BI (RLS, object permissions); auditability of the AI layer is weaker than the warehouse-native options because the reasoning is in-platform. Wider alternatives: 8 ThoughtSpot Alternatives.
7. Sigma Computing (Ask Sigma) - Accuracy 3, Governance 3.5
Best for: Excel-fluent teams on a cloud warehouse who want AI exploration with visible reasoning.
Sigma computes live against the warehouse - no extracts - so answers are at least always about current data, and Ask Sigma earns specific credit for transparency: it shows every step of its reasoning for users to inspect and edit, which is more than most assistants in this list offer. Governance inherits warehouse permissions plus workspace controls. The limits: semantics live in workbook logic and warehouse schemas (you build and maintain them), accuracy claims are not benchmarked publicly, and pricing is quote-only - Vendr reports a ~$62,000/year median. A strong choice for exploration; a partial answer for governed, repeatable reporting.
8. Tableau Pulse - Accuracy 2.5, Governance 3
Best for: Tableau Cloud estates that want proactive metric monitoring more than open-ended Q&A.
Pulse is honest about what it is: a metrics feed. You define metrics; Pulse watches them, surfaces changes, and answers questions about those metrics. Within that boundary it is useful and the failure surface is small - which is a defensible design. The boundaries are the score: each Pulse metric is bound to a single published data source, Q&A cannot leave the metric's scope, it is Tableau Cloud-only (not available on Tableau Server), and deeper agentic features sit in the sales-negotiated Tableau+ bundle. Cross-metric "why" questions - the ones diagnosis actually requires - are out of scope, as we showed in Power BI Copilot vs Tableau Pulse and Colrows vs Tableau Pulse.
9. Metabase + Metabot - Accuracy 2.5, Governance 2.5
Best for: teams that want transparent pricing and pragmatic dashboards with AI assistance, and can accept lighter governance.
Metabase publishes what enterprise vendors hide: open source self-hosted for $0, cloud from $100/month, and AI usage at a flat $3.75 per million tokens. Metabot generates SQL you can see and edit, and its documentation lists its limits plainly - a small thing that builds more trust than most marketing. The honest ceiling: governance depth is lighter than anything above it on this list, semantics live in your models and metadata (unbudgeted modeling tax again), and third-party testing notes Metabot degrades sharply on messy models. As a price-performance baseline for non-regulated teams, hard to argue with.
The scorecard
| Tool | Accuracy /5 | Governance /5 | Who builds the semantics | Entry price (published?) |
|---|---|---|---|---|
| Colrows | 5 - compiled, deterministic, fails loudly | 5 - compile-time policy + reproducible audit | Autonomous graph + drift detection | Free tier; Enterprise custom |
| Cortex Analyst | 4 - 51→90%+ with semantic views (vendor, internal) | 4 - warehouse RBAC, SQL shown | You (semantic views) | Snowflake consumption |
| Databricks Genie | 3.5 - good in curated spaces; nondeterministic | 4 - Unity Catalog, SQL shown | You (per-space curation) | Databricks consumption |
| Power BI Copilot | 2 - documented nondeterminism + accuracy warnings | 3 - model-level RLS | You ("Prepare your data for AI") | $14/user/mo + Fabric F2 from $262.80/mo |
| Looker Conv. Analytics | 3.5 - LookML-grounded | 4 - central definitions, access filters | LookML developers | Quote-only + metered Gemini tokens |
| ThoughtSpot Spotter | 3 - mature, worksheet-dependent | 3 - enterprise BI controls | You (worksheets + curation) | $25/user/mo; $92,521 Vendr median |
| Sigma (Ask Sigma) | 3 - visible reasoning steps | 3.5 - warehouse + workspace controls | You (workbooks + warehouse) | Quote-only (~$62K/yr median, Vendr) |
| Tableau Pulse | 2.5 - reliable inside metric scope only | 3 - platform permissions | You (metric definitions) | ~$75/Creator/mo (reported); Tableau+ for more |
| Metabase + Metabot | 2.5 - SQL visible; degrades on messy models | 2.5 - lighter controls | You (models + metadata) | $0 OSS; $100/mo cloud; $3.75/M AI tokens |
The pattern in the scores
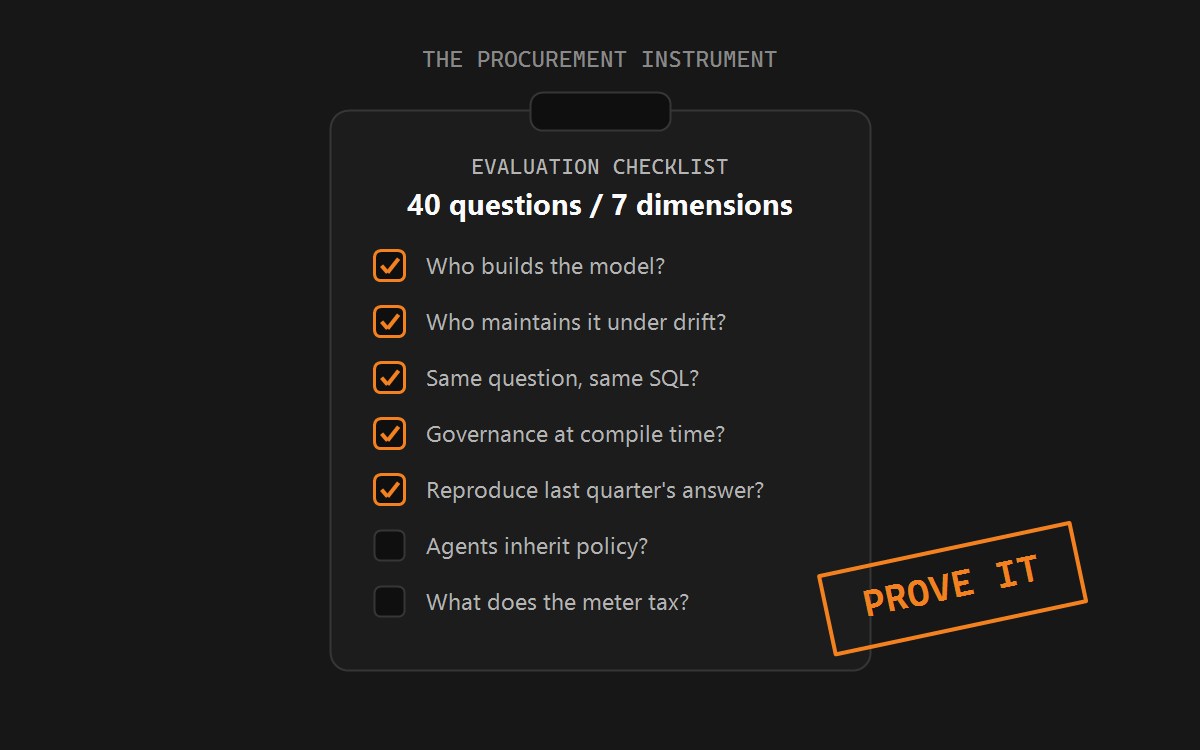
Sort the table by the accuracy column and a rule falls out: scores track how much explicit semantic structure stands between the model and your schema - and who maintains it. Raw generation scores lowest (the Spider 2.0 evidence predicts exactly this). Generation grounded in hand-authored semantics scores mid-to-high, at the price of a permanent modeling team. Compilation through an autonomously maintained semantic graph scores highest, because the probabilistic step is removed from the execution path entirely rather than merely supervised. The same sort works for the governance column: tools that enforce policy at compile time and emit reproducible audit trails beat tools that filter at render time. If you want the architecture argument with the receipts, it is in Deterministic vs Probabilistic Text-to-SQL; if you want it as a procurement instrument, use the Semantic Layer Evaluation Checklist.
Frequently asked questions
What is the best AI analytics tool in 2026?
The best architecture for your risk profile. Regulated or high-stakes: compiled, deterministic execution (Colrows), or at minimum semantically grounded generation that shows its SQL (Cortex Analyst, Genie). Assistant inside an existing BI estate: Copilot, Pulse, or Looker - with the documented caveats above priced in.
How accurate are these tools on real data?
Raw LLM text-to-SQL: 10-21% on real enterprise tasks (Spider 2.0), ~10% on MIT's BEAVER warehouse benchmark. With explicit semantic structure: Snowflake reports 90%+ internally; dbt's benchmark reached 98-100%. The variable is the semantic layer, not the model.
Which work for regulated industries?
Look for determinism, compile-time policy enforcement, and point-in-time reproducible audit trails. Colrows is built around all three; warehouse-native tools get partial credit via inherited controls and visible SQL; Copilot is documented nondeterministic by its vendor.
What do they cost?
Per-seat (Power BI $14, ThoughtSpot $25), consumption (Fabric capacity from $262.80/month, warehouse compute, Gemini tokens), and quote-only enterprise ($50K-$150K+ medians per marketplace data). Full teardowns: ThoughtSpot, Power BI Copilot, Looker.
A note on the claims
Scores are ours and the rubric is stated; re-weight as you see fit. Factual claims cite vendor documentation, vendor engineering posts, published benchmarks (Spider 2.0, BEAVER), and attributed marketplace data (Vendr), checked 12 June 2026. Vendor-reported accuracy figures (Snowflake's 90%+, Databricks's 32→90%) are internal benchmarks, labelled as such. Colrows is our product; we put it first on our own list and showed our work so you can check it.