The trap: "80% right, much faster" is a bad trade on the wrong 20%
Speed is seductive. A business user types a question, and three seconds later a clean chart appears. The pitch writes itself: democratized data, fewer analyst tickets, faster decisions.
Here is the problem. In analytics, the cost of an answer is not symmetric. A fast, correct answer saves an hour. A fast, wrong answer that nobody catches can drive a decision that costs millions. When the output looks polished and authoritative, the business user has no reason to suspect it, so the error travels straight into a forecast, a board deck, or a loan approval. The damage surfaces later, often during an audit.
The "1x10x100" rule in data management captures this: a data error costs roughly one unit to fix at the point of entry, ten units once it propagates through systems, and a hundred units once it reaches a decision-maker. Generative analytics is an efficient machine for moving errors straight to the hundred-unit stage, because it presents guesses with the same confidence as facts.
What "wrong" looks like in practice
Imagine a revenue dashboard. A business user asks Copilot, "What drove the spike in Q3 revenue in the Northeast?" Copilot returns a confident answer: revenue jumped 15%, driven by enterprise accounts. The CFO repeats it on an earnings call.
The truth: there was no spike. Three large transactions were double-counted because the question joined an orders table to a billing table on a key that fans out, and the model silently picked the join that produced the most plausible-looking result. The "15%" was an artifact. By the time finance reconciles the numbers, the guidance is already public.
This is not a hypothetical failure mode. A Power BI consultant who tested Copilot for 30 days on real client projects described the central hazard precisely: "This is Copilot's most dangerous behavior: it doesn't tell you when it can't answer your actual question. It answers a different, easier question and presents it as if that's what you asked." His tally on one task: "Copilot generated the DAX in 3 seconds. It took me 45 minutes to fix what it got wrong."
Three failure patterns recur in the field:
- Join ambiguity and grain mismatch. The model picks a relationship that looks right and aggregates over the wrong dimension. The number is plausible and wrong.
- The same question, two answers. The consultancy Thorogood, assessing Copilot, flagged that "repeatability is a key issue — the same query can produce different answers." A number that changes between Monday and Tuesday destroys trust in both readings.
- Answers from the wrong place. Microsoft's own community forums document Copilot pulling answers from existing report visuals "which can be incorrect," with Microsoft confirming there is no setting to disable the behavior, and AI instructions being "applied inconsistently."
None of this is a scandal. It is what the technology does. The mistake happens downstream, when an organization deploys a tool documented this way as if it were a calculator.
Take Microsoft at its word
The most credible critic of Copilot's accuracy is Microsoft. Its documentation is unusually honest, and economic buyers should read it as a risk disclosure:
- Copilot "can produce inaccurate or low-quality outputs, including incorrect answers to data questions."
- Its outputs are "nondeterministic, meaning that it's possible for a user to receive a different output from a Copilot experience, despite using the same prompt and grounding data."
- "Inaccurate responses to data questions can lead to incorrect decisions and actions by business users, which produces bad results."
- And the line every CFO should sit with: if testing does not produce "consistently correct and reliable results... you might want to consider advising users not to use Copilot to consume your semantic model."
Microsoft even tells you the guardrails are not guaranteed. Its "AI instructions" feature lets you write up to 10,000 characters of business rules in prose, but the docs warn: "There's no guarantee that the LLM will exactly follow instructions."
Why this happens, without a computer science degree
Three plain-English reasons.
1. The model cannot fit your business in its head
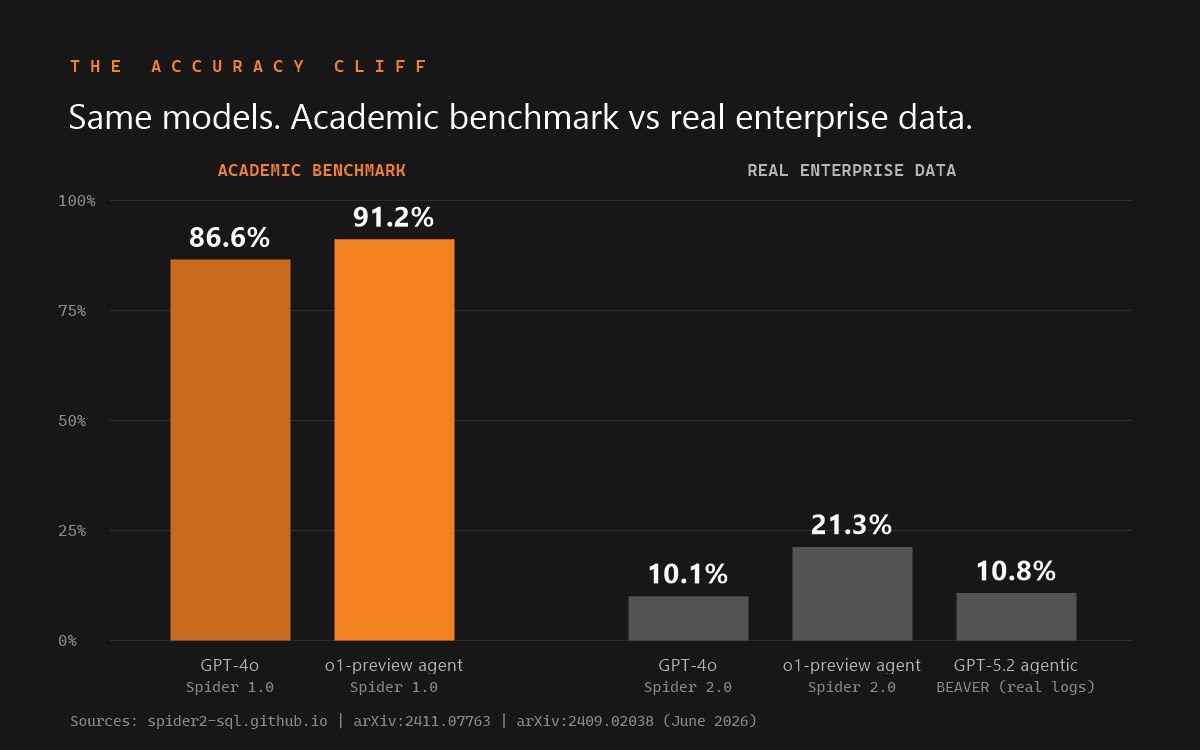
A large language model reads a limited amount of text at once, called a context window. Your enterprise data is enormous: a typical warehouse has hundreds of tables and thousands of columns. The enterprise benchmark Spider 2.0 notes its test databases "often contain over 1,000 columns," with some test schemas exceeding 3,000; real systems are often larger. The model never sees the whole picture. It sees a retrieved slice and guesses about the rest. Miss one column or pick the wrong join, and the answer is wrong. This is why accuracy collapses on enterprise schemas: on Spider 2.0, GPT-4o's success rate is "only 10.1%... compared to 86.6% on Spider 1.0," and an o1-preview multi-agent system "solves only 21.3% of the tasks, compared with 91.2% on Spider 1.0."
2. It is not a calculator; it does not give the same answer twice
Engineers can turn the model's "randomness" dial to zero (temperature 0), and most people assume that makes it deterministic. It does not. Because of how the math runs across many processors at once, identical questions can still produce different results. In one published test, asking the same question 1,000 times at temperature zero produced the most common answer only 78 times. A peer-reviewed study found accuracy swings of up to 15% across repeated runs of supposedly deterministic settings. For a regulated metric, "usually the same" is not good enough.
3. It is trained to sound confident, even when wrong
OpenAI's own September 2025 research, "Why Language Models Hallucinate," explains that the way these models are trained and scored rewards confident guessing over admitting uncertainty: like a student on an exam that penalizes blank answers, the model learns to always answer, never abstain. The result is what researchers call "confidently wrong" — fluent, authoritative language attached to an incorrect answer. A human analyst who is unsure says so. A language model, by design, usually does not.
This is the "fluent failure" problem in one sentence: the tool is optimized to sound right, not to be right, and your business user cannot tell the difference.
The RAG gap: better retrieval is not the fix
Microsoft's prescription, sensibly, is to prepare your data: clean star schemas, human-readable names, field descriptions, synonyms, and curated "verified answers" for known questions. This is a retrieval-augmented approach — give the model better context and it guesses better.
It helps. It does not close the RAG gap, for two reasons. First, "verified answers" are capped (250 per model, with documented limits) and only cover questions someone anticipated; every other question still goes through generation. Second, and more fundamentally, the prep work is a semantic layer hand-built in prose, and the enforcement mechanism is a model that is documented as not guaranteed to follow it. Better retrieval reduces the odds of a wrong join; it cannot prove the join is right. For a question that feeds a regulator, "less likely to be wrong" is not the standard.
What a wrong answer actually costs
This is the part that belongs in front of a CFO.
- The baseline. Gartner's 2020 research on data quality (its Magic Quadrant for Data Quality Solutions, based on 154 reference customers) found that "poor data quality costs organizations on average $12.9 million" per year. MIT Sloan Management Review puts the revenue drag higher still, estimating organizations lose 15–25% of revenue annually to poor data quality.
- A bad number fed into a model. On its Q1 2022 earnings call, Unity Software told investors: "we lost the value of a portion of our data, training data due in part to us ingesting bad data from a large customer. We estimate the impact to our business of approximately $110 million in 2022." The stock fell nearly 40% the day after the announcement. One flawed data input; nine figures gone.
- A bad number in a financial statement. When companies restate earnings, the market punishes them. Peer-reviewed research (Palmrose, Richardson and Scholz, 2004) documented "a negative mean (median) market reaction to restatement announcements of −9.2 percent (−4.6 percent) over a 2-day event window," and a US Government Accountability Office study found a comparable ~10% average decline. In the first ten months of 2024, 140 public companies disclosed the most severe class of restatement.
- A bad number in a credit decision. In 2022, a coding error caused Equifax to send inaccurate credit scores to lenders. Per the company's statement, "the differential was at least 25 points for around 300,000 consumers," large enough that "some would-be borrowers may have been wrongfully denied credit." Regulatory settlements followed.
Now overlay the regulatory regimes economic buyers answer to. BCBS 239 requires banks to aggregate risk data "on a largely automated basis so as to minimise the probability of errors," with end-to-end lineage that traces every number back to source. SOX requires auditable, reproducible financial reporting. A system that cannot produce the same answer twice, and cannot hand an auditor the exact query behind a number, is structurally difficult to defend under either. Gartner predicts that by 2028, half of organizations will adopt a zero-trust posture toward AI-generated data precisely because so much of it is unverified.
The math for an economic buyer is simple. The cost of a governance layer is a line item. The cost of one wrong answer in front of a board or a regulator is a different order of magnitude.
The fix: don't replace Copilot. Ground it.
Here is the part that is easy to get wrong. The answer is not "rip out Power BI." Power BI is an excellent reporting tool, Copilot is a genuinely fast way to explore and draft, and most enterprises will keep both. The answer is to change where the answer comes from when the question is critical.
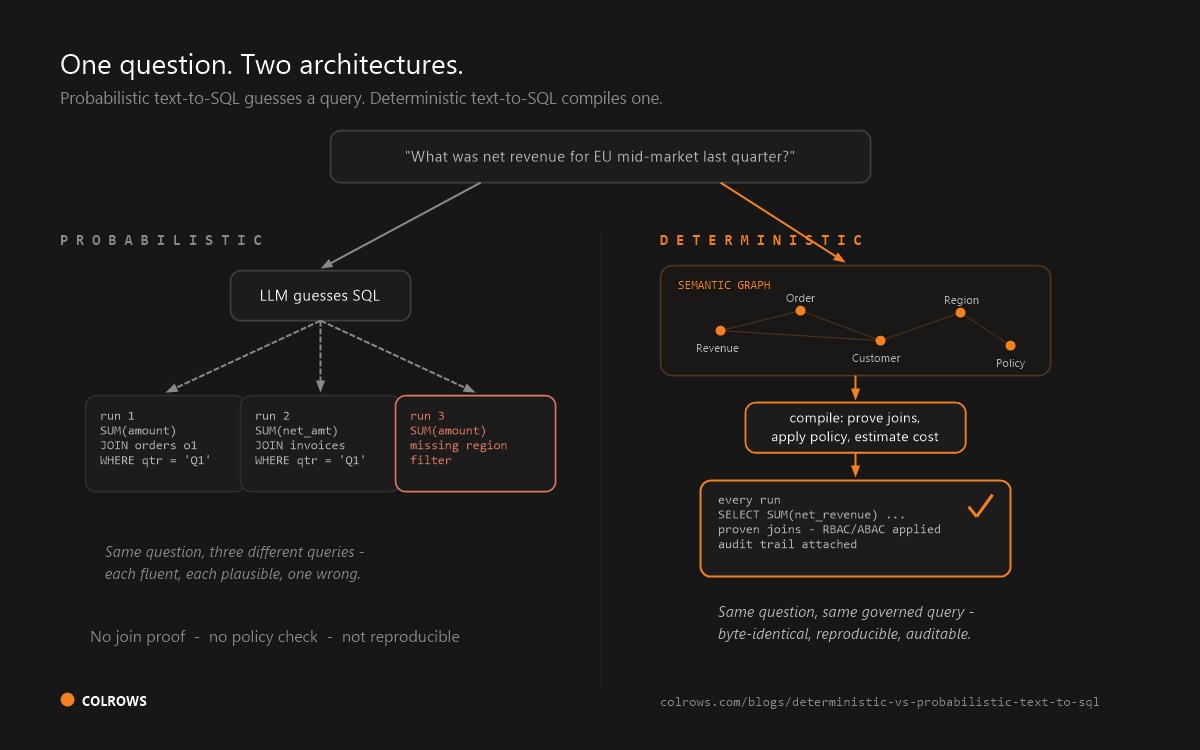
Instead of asking a generative model to produce the number, you compile rather than generate the question against an explicit, governed semantic layer: the question resolves to versioned definitions ("revenue" means the one approved formula), the joins are proven before the query runs, access rules are enforced before any row is read, and every answer ships with the exact SQL and an audit trail you can hand to a regulator. The model still handles the language; the semantic layer guarantees the meaning. Where a generative tool's failure mode is a fluent wrong answer, a compiler's failure mode is a loud, inspectable refusal — and in regulated analytics, a loud failure is far cheaper than a confident guess.
This is not a fringe view. Every serious vendor has converged on it. Looker grounds its Conversational Analytics in the LookML semantic layer so the AI "does not guess how tables connect." Snowflake's Cortex Analyst maps questions to modeled metrics in a Semantic View to avoid hallucinated joins. dbt's Semantic Layer and Cube compile governed metric definitions into SQL. Colrows implements this as a deterministic semantic compiler: a versioned semantic graph, compile-time governance (RBAC, ABAC, and row- and column-level rules enforced before SQL exists), and dialect-perfect SQL with a join-path proof and reproducible audit trail for every answer.
Crucially, Colrows can sit in front of your existing estate. It connects to the same warehouses with no data replication, and because it speaks open protocols including the Model Context Protocol (MCP), Copilot and any other AI agent can talk to it via MCP without a rewrite. Copilot stays fast; it just stops being wrong on the questions that matter, because it is now asking a layer that compiles and proves the query rather than generating and hoping.
When fast is fine, and when it is dangerous
Use Copilot where it shines: drafting report pages, summarizing visuals, writing DAX, and exploratory questions where a knowledgeable person will sanity-check the result before anything happens. Treat its output, as Microsoft itself advises, as a draft for expert review.
Do not let it feed a board decision, drive a credit approval, inform capital allocation, or answer a regulator unless the answer was compiled, governed, and proven. The dividing line is not the tool's quality. It is the cost of being wrong.
A practical next step
If you are an analytics leader, identify the three questions in your organization where a wrong answer is most expensive — the ones that touch revenue recognition, risk, or a regulator. Ask how those answers are produced today, whether they are reproducible, and whether you could show an auditor the exact query. If the honest answer involves a generative tool, that is your governance gap.
You do not have to choose between speed and safety. Keep the fast, accessible front end. Put a deterministic semantic layer underneath the answers that carry fiduciary weight. Start where wrong answers cost the most — and let Colrows ground your Power BI and AI-agent workloads in a deterministic, governed semantic layer with same warehouses, no data replication, and MCP-ready integration.
Frequently asked questions
Does Power BI Copilot give wrong answers?
Yes; Microsoft's documentation states it "can produce inaccurate or low-quality outputs, including incorrect answers to data questions," and that outputs are nondeterministic.
Can Power BI Copilot be made deterministic?
No; nondeterminism is architectural, not a setting. "Verified answers" pin a capped set of known questions; everything else is generated.
Is it safe to use Power BI Copilot for board or financial decisions?
Not without a governance layer. Microsoft advises treating output as a draft for expert review.
What does a wrong analytics answer cost?
Gartner's 2020 research found poor data quality costs an average of $12.9M/year; specific incidents have cost nine figures (Unity, ~$110M) and ~9–10% stock declines on restatement.
How do I make Power BI Copilot more accurate?
Prepare the semantic model (naming, descriptions, verified answers) and, for critical questions, ground answers in a deterministic semantic layer.
What are the alternatives to Power BI Copilot for governed analytics?
Looker Conversational Analytics, Snowflake Cortex Analyst, dbt Semantic Layer, Cube, and Colrows all ground AI in a semantic layer.
Does a semantic layer replace Power BI?
No; it grounds the answering layer. Power BI keeps reporting; critical questions route through compiled, governed execution.
How does Colrows make Copilot safe?
Copilot talks to Colrows via MCP; Colrows compiles questions into governed, auditable SQL with enforced access rules, so answers are deterministic and provable.