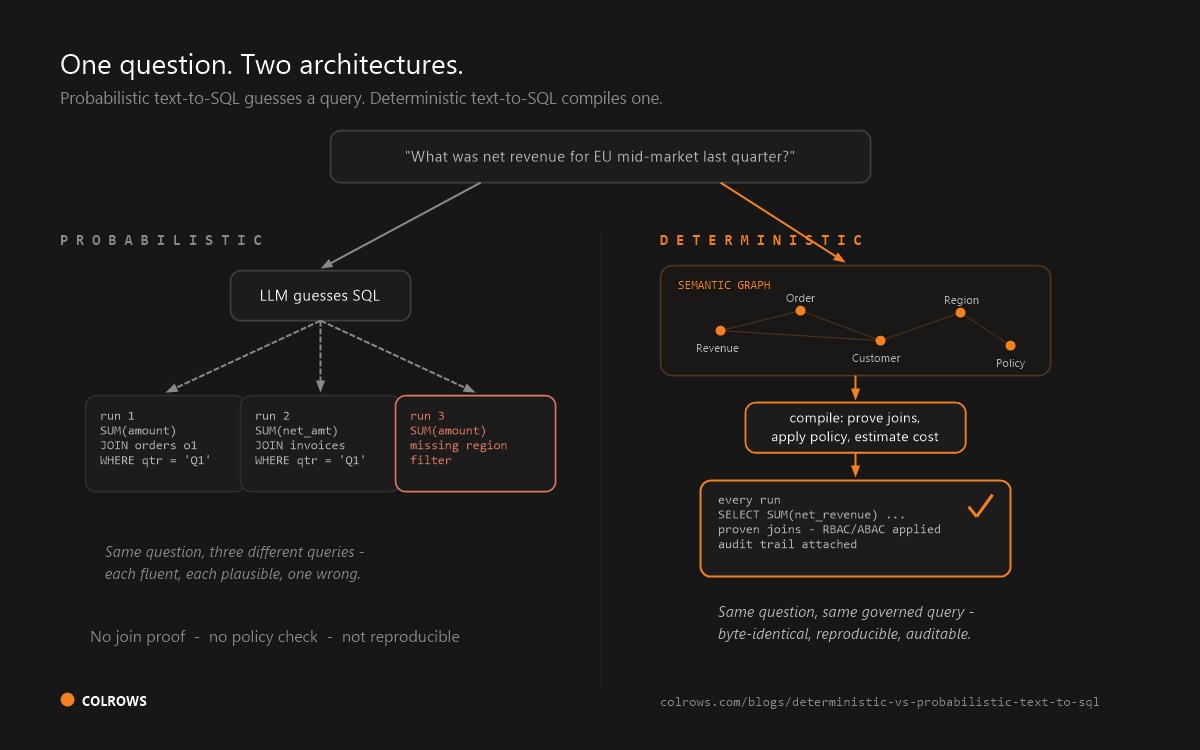
What the famous numbers actually measure
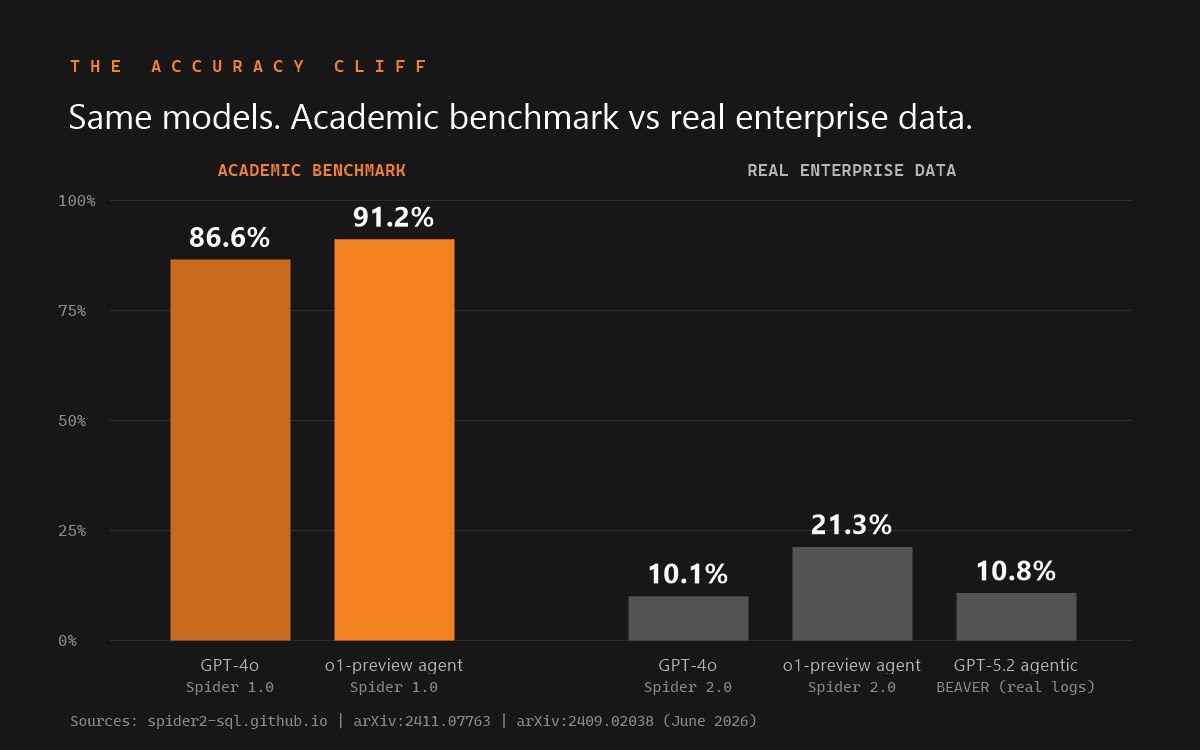
For years, the standard text-to-SQL benchmark was Spider 1.0: thousands of question-SQL pairs over small, clean, well-named databases - a college enrolment schema here, a concert-singer database there. A handful of tables. Obvious joins. Column names that mean what they say. On that terrain, modern LLMs are genuinely excellent: 86.6% for GPT-4o, 91.2% for o1-preview-based agents.
Those are the numbers that made "just ask your data" demos credible, and they are real. The problem is what they are numbers about. A Spider 1.0 task is a translation exercise: the question contains nearly everything needed to write the query, and the schema is small enough to read whole. Production enterprise data is not a translation exercise. It is an interpretation exercise against a thousand-column estate with twenty years of accumulated naming decisions.
Standard LLM vs. Colrows Semantic Compiler at a Glance
| Capability | Standard LLM / RAG | Colrows Semantic Compiler |
|---|---|---|
| Logic Source | Probabilistic Prompting | Deterministic Metric Definitions |
| SQL Generation | Black-box translation | Governed Semantic Mapping |
| Data Governance | Post-query (Runtime) | Pre-query (Compile-time) |
| Auditability | Difficult to verify | Full lineage / Auditable |
| Reliability | Hallucination-prone | Enterprise-grade accuracy |
The short answer: raw LLMs and RAG pipelines guess at SQL because they have to. A semantic compiler resolves your business metrics into governed SQL at compile time, with policies injected before the warehouse is touched. Same model, different infrastructure, different floor on accuracy.
What happens on real enterprise data
Three benchmark programs have now measured that second problem directly. They agree with each other to an uncomfortable degree.
- Spider 2.0 (Lei et al., ICLR 2025) rebuilt the benchmark from 632 real enterprise workflow tasks - BigQuery and Snowflake estates that often exceed 1,000 columns, solutions that can require multi-step SQL beyond 100 lines. The authors' o1-preview-based agent framework solved 21.3%, versus 91.2% on Spider 1.0. The project site puts GPT-4o at 10.1%, versus 86.6% on Spider 1.0. Same models, honest data, an 8.5× collapse.
- BEAVER (MIT, arXiv:2409.02038) is the first text-to-SQL benchmark built from real private enterprise warehouse query logs. Because that data was never on the public internet, models cannot lean on memorized patterns. Off-the-shelf GPT-4o scored 0.0% under the retrieval setting and 2.0% retrieval-free, and the authors state plainly that "none of the off-the-shelf LLMs (even GPT-4o) can answer any question correctly."
- BIRD, the long-running benchmark of large, "dirty" databases, shows the gap from the other side: the best published system scores around 82% execution accuracy while human data engineers score 92.96% - a double-digit gap that has survived every model generation since the leaderboard opened.
The three gaps that create the cliff
Why does the same model lose 70 points crossing from benchmark to warehouse? Three specific things change.
1. Scale breaks the reading strategy
On a 30-column schema, the model reads everything and reasons over all of it. On a 1,400-column estate, the schema does not fit usefully in context - and even when it technically fits, relevance gets diluted. The model must guess which subset of the schema matters before it writes a line of SQL, and a wrong guess at that step is unrecoverable. This is why Spider 2.0's hardest failures are not syntax errors; they are queries built on the wrong tables.
2. The decisive semantics are not in the database
Which of the four columns containing the word "revenue" is the one finance signs off on? Is customer in the billing schema the same entity as account in CRM? Does "last quarter" mean calendar or fiscal? No schema encodes these answers. They live in documentation, in BI definitions, in the heads of analysts - outside anything the model can see. The Sequeda, Allemang and Jacob study isolated this variable: GPT-4 zero-shot on an enterprise insurance schema scored 16.7%, and on the high-schema-complexity questions, 0%. The same questions over a knowledge-graph representation of the same database: 54.2%. Nothing about the model changed. The available meaning did.
3. Nothing verifies the answer
A generated query that parses and executes looks exactly like a correct one. There is no ground truth at runtime, no error message for "this join silently double-counts subscriptions." Snowflake's engineering team measured GPT-4o at 51% on their internal set of 150 real BI questions - which means roughly every second answer was wrong, fluently. dbt's 2026 benchmark named this failure mode precisely: "Text-to-SQL will cheerfully give you a wrong number."
The three gaps decompose operationally into six concrete failure modes that show up in production logs and post-incident reviews. If you have triaged enterprise text-to-SQL incidents, you have seen this taxonomy already.
| Failure mode | What happens | Why it is dangerous |
|---|---|---|
| Metric drift | The model chooses a column that sounds right but is not the approved metric. | Teams get different numbers for revenue, churn, margin, risk, or active users - and reconcile by argument. |
| Wrong joins | The model joins tables using guessed keys or incomplete relationships. | Rows duplicate silently, records disappear, or totals inflate - all without an error. |
| Schema guessing | The model assumes table semantics from naming patterns rather than the system of record. | SQL executes against the wrong source of truth; the result looks defensible until finance audits it. |
| Calendar mismatch | The model uses calendar dates when the business expects fiscal periods, or vice versa. | Quarterly and monthly reports never agree with finance numbers; mismatches surface in board reviews. |
| Governance bypass | The model includes restricted columns because it only optimizes for the answer. | Sensitive PII, PAN, or health data can leak through AI-generated queries that no human reviewed. |
| No audit trail | The generated SQL has no approved definition or version behind it. | The enterprise cannot prove why an answer was generated; regulators get a log, not a reproduction. |
The hard part is not generating SQL. The hard part is generating the right SQL - and a system that cannot tell the difference between the two is a confident-failure machine. Every failure mode in the table is a symptom of one root cause: the decisive context lives outside the schema, and the model never sees it.
Why "deterministic settings" are not deterministic
Buyers often assume temperature 0 means same question, same answer. It does not. Floating-point accumulation order, GPU parallel reductions, request batching, and mixture-of-experts routing all introduce run-to-run variation. Anthropic's own documentation states that "even with a temperature of 0.0, the results will not be fully deterministic." Atil et al. (Eval4NLP 2025) found "accuracy variations up to 15% across naturally occurring runs." For a regulated metric, "the model usually gets the same answer" is not a control you can put in front of an auditor. True determinism requires compile-time governance that exists outside the model.
What it costs when the number is wrong
Here is the bridge from engineering to the income statement. A fluent wrong answer does not announce itself. It flows into a forecast, a pricing model, a risk metric, or a board slide, and the cost surfaces downstream where it is most expensive to fix.
Gartner has pegged the cost of poor data quality at an average of $12.9 million per organization per year. IBM's Institute for Business Value found in its 2025 CDO study that over a quarter of organizations lose more than $5 million annually to poor data quality, and 7% lose $25 million or more. In a BlackLine survey, almost seven in ten finance professionals believed they or their CEO had made a significant business decision based on out-of-date or incorrect financial data. Equifax's 2022 credit-score data error ended in a $725,000 settlement plus class-action litigation, and Unity Technologies reported roughly $110 million in lost revenue from corrupted model-training data the same year.
The old engineering rule still holds: an error costs about $1 to catch at the source, $10 downstream, and $100 in production. A conversational analytics tool that fabricates instead of failing is a $100-stage error generator wearing a friendly chat interface.
What failure looks like, in actual SQL
The benchmarks tell you accuracy collapses. They do not show you what wrong looks like at the level a reviewer would catch. Three production-shaped examples make the failure modes concrete - and show what the same question compiles to once a semantic layer resolves intent first.
Example 1: "Q3 revenue in the EU"
A sales leader asks: "What was our Q3 revenue in the EU region?" A text-to-SQL system inspects the schema, finds tables called orders, customers, regions, payments, and emits a query that runs cleanly:
SELECT
SUM(o.amount) AS revenue
FROM orders o
JOIN customers c ON c.id = o.customer_id
JOIN regions r ON r.id = c.region_id
WHERE r.name = 'EU'
AND o.order_date BETWEEN '2026-07-01' AND '2026-09-30';The SQL parses. The SQL executes. The number is wrong, for at least seven reasons a finance auditor would name immediately: orders.amount is booked value not recognized revenue; refunds and credit notes are not subtracted; cancelled orders are not excluded; EU should be derived from billing country, not customer-master region; Q3 means fiscal Q3 at this company, not calendar Q3; internal test customers are not filtered; the requesting user is only authorized to see aggregated revenue. None of those facts are in the schema. All of them live in the semantic layer - if one exists.
-- Resolved intent
-- Metric: Recognized Revenue (governed, v3.2, owner: finance)
-- Region scope: EU billing region (excludes UK post-Brexit)
-- Period: Fiscal Q3 FY2026
-- Exclusions: cancelled orders, test accounts
-- Adjustments: refunds, credit notes
-- Policy: aggregate-only for role=sales_leader
SELECT
SUM(i.recognized_amount - COALESCE(cr.credit_amount, 0)) AS revenue
FROM finance_invoices i
LEFT JOIN finance_credit_notes cr
ON cr.invoice_id = i.invoice_id
JOIN dim_billing_region br
ON br.billing_region_id = i.billing_region_id
JOIN dim_fiscal_calendar fc
ON fc.date_key = i.recognition_date_key
WHERE br.region_group = 'EU'
AND fc.fiscal_year = 2026
AND fc.fiscal_quarter = 'Q3'
AND i.status = 'RECOGNIZED'
AND i.is_test_account = FALSE;The second query is not "better SQL." It is SQL emitted from a resolved, versioned business definition. A regulator can re-execute it next quarter and obtain the same number; a reviewer can name which definition produced each clause. The first query has neither property.
Example 2: "active customers last month"
A product manager asks: "How many active customers did we have last month?" The model finds a column called customers.status with the value 'ACTIVE' and answers in seconds. The number is high. Sales loves it. Finance disagrees. Product disagrees differently. They are all defensibly correct - because "active customer" means a different thing to each function, and the schema enforces none of those meanings.
| Team | Working definition of "active customer" |
|---|---|
| Sales | Customer with an open opportunity or active contract. |
| Finance | Customer with at least one paid invoice in the period. |
| Product | Account with at least one non-internal user login in the last 30 days. |
| Support | Customer with an active support entitlement. |
| Customer success | Customer above an agreed usage / adoption threshold. |
A text-to-SQL model picks the column that looks obvious. None of the five definitions lives in that column.
SELECT COUNT(*) AS active_customers
FROM customers
WHERE status = 'ACTIVE';In most operational systems, status = 'ACTIVE' only means the record is not archived. It does not encode payment, usage, entitlement, or contract state. The semantic layer forces the model to commit to a named concept - and exposes the parallel concepts as separate first-class metrics so finance, product, and CS can each ask the right question:
-- Resolved concept: active_customer_product
-- = account with >=1 non-internal user event in the last 30 days,
-- excluding trial-only accounts
-- Parallel concepts also available:
-- active_customer_finance, active_customer_success, active_customer_sales
SELECT COUNT(DISTINCT a.account_id) AS active_customers
FROM dim_account a
JOIN fact_user_activity ua ON ua.account_id = a.account_id
JOIN dim_calendar d ON d.date_key = ua.activity_date_key
WHERE d.month_start = DATE '2026-05-01'
AND ua.is_internal_user = FALSE
AND a.account_type != 'TRIAL_ONLY';Example 3: PII leakage at machine speed
A regional manager asks: "Show high-risk customers with overdue amount and contact details." The text-to-SQL model is not malicious. It is optimizing for the requested answer. Phone numbers, email addresses, PAN are all in the schema and all relevant to "contact details," so they all land in the SELECT list:
SELECT
c.customer_name,
c.mobile_number,
c.email,
c.pan_number,
r.risk_score,
l.overdue_amount
FROM customers c
JOIN loans l ON l.customer_id = c.customer_id
JOIN risk_scores r ON r.customer_id = c.customer_id
WHERE r.risk_score > 80
AND l.overdue_amount > 0;Post-query row-level security might filter rows the user is not allowed to see, but it cannot prevent columns the user is not allowed to project from being projected. By the time the answer is on screen, the disclosure has occurred. A semantic layer applies the policy before SQL is compiled - the restricted columns never enter the query plan at all:
-- Role: regional_manager
-- Allowed: customer_name (masked), risk_band, overdue_amount_bucket
-- Removed at compile time: mobile_number, email, pan_number
-- Row policy: c.region_id = CURRENT_USER_REGION()
SELECT
MASK(c.customer_name) AS customer_name,
r.risk_band,
l.overdue_amount_bucket
FROM governed_customer c
JOIN governed_loan_exposure l ON l.customer_id = c.customer_id
JOIN governed_risk_profile r ON r.customer_id = c.customer_id
WHERE r.risk_band IN ('HIGH', 'CRITICAL')
AND l.has_overdue = TRUE
AND c.region_id = CURRENT_USER_REGION();The architectural distinction is the entire point: the first query is what the model produces when it is asked to maximize answer quality against raw schema. The second is what the same model produces when it is forced to compile through a governed semantic surface. The accuracy cliff is the gap between those two surfaces, expressed in SQL.
What provably closes the gap
The published record contains exactly one pattern that recovers the lost accuracy, demonstrated independently at least four times: make the missing context explicit, and constrain generation through it. Unlike approaches like RAG that retrieve context dynamically per query, the durable solution is to build context into the infrastructure itself.
| Study | Without structure | With structure | What was added |
|---|---|---|---|
| Sequeda et al. (2023) | 16.7% | 54.2% | Knowledge-graph representation |
| Snowflake (2024) | 51% | 90%+ | Hand-authored semantic model |
| dbt Labs (2026) | 84-90% | 98-100% | Deterministic semantic layer (11-question set) |
| Spider 2.0 leaderboard (2026) | 10-21% raw | 70-96% self-reported | Multi-step agentic scaffolds with schema exploration and self-correction |
Read the fourth row carefully, because it is the one vendors will quote next. The systems now topping the Spider 2.0 leaderboard are not better raw models - they are elaborate scaffolds that explore the schema, retrieve context, execute, and self-correct across many model calls per question. They close the gap by rebuilding the missing structure on the fly, per query, every time. It works, at the cost of latency, tokens, and zero guarantees of consistency between runs. The alternative is to build that structure once - as a governed, versioned semantic layer - and compile every query through it. Same insight, durable form.
How every serious vendor has converged
The honest competitive picture: everyone now grounds the LLM in a semantic layer. They differ on determinism, governance, coverage, and portability. However, neither Snowflake nor Databricks can serve as a cross-warehouse semantic layer due to their warehouse-native architecture.
- Snowflake Cortex Analyst hits 90%+ with Semantic Views, about twice single-shot GPT-4o, but is Snowflake-only.
- Databricks AI/BI Genie leans on Unity Catalog Metrics plus a Benchmarks feature and an Inspect verification step; field reports show 50% raw climbing to 90% after semantic curation.
- Looker Conversational Analytics composes queries from LookML rather than writing full SQL, so the agent "doesn't need to understand the data and can operate more accurately and deterministically." Fast mode maps straight to governed measures.
- dbt Semantic Layer / MetricFlow reaches near-100% on covered queries, with the honest caveat that coverage is the limit and many-join questions still fail.
- Cube compiles governed metrics to SQL deterministically and serves them to agents over MCP.
- AtScale reports 100% on its NLQ benchmark with a semantic layer versus under 20% on raw models, and a Tier 1 bank case that cut compute up to 21,000x while lifting accuracy from 70% to 100%.
- Power BI Copilot grounds in the semantic model via retrieval but still warns that output "can seem plausible but is factually incorrect."
The convergence is the headline. The semantic layer is no longer optional infrastructure for trustworthy AI on data. The only open questions are how deterministic it is, how much it governs, how much it covers, and whether it is locked to one warehouse.
How to read any vendor's accuracy claim
Once you know the cliff exists, accuracy claims become checkable. Four questions strip the marketing off any number:
- Accuracy on whose data? Spider 1.0-class benchmarks predict almost nothing about a thousand-column warehouse. If the claim is not measured on enterprise-scale schemas - or better, your schemas - it is a translation-exercise score.
- How many questions, how many runs? dbt's benchmark is honest about being 11 questions; Snowflake's is 150. Small evaluation sets are fine if disclosed - undisclosed, they are a red flag.
- Single-shot or scaffolded? If the demo uses an agent loop with retries and self-correction, ask what the per-question cost and latency are, and whether two runs give the same answer.
- What does failure look like? The most important question. A system that errors when it cannot answer is operationally safe at 90%. A system that fabricates when it cannot answer is operationally dangerous at 99%.
That last distinction - loud failure versus fluent failure - is the dividing line between probabilistic and deterministic architectures, and it deserves its own treatment: the full buyer's framework is in Deterministic vs Probabilistic Text-to-SQL.
Is your text-to-SQL system enterprise-ready? A 10-point self-test
Reading vendor claims is one lens. The complementary lens is your own system. Before any text-to-SQL surface ships to business users or autonomous agents, run it against the ten questions below. Each "no" is a specific failure mode you can map back to the taxonomy above - and a specific gap you are accepting if you scale anyway.
- Can it distinguish booked, billed, collected, and recognized revenue - and refuse to answer if the request is ambiguous between them?
- Can it ask a clarification question when a business term has multiple governed definitions, rather than silently picking one?
- Can it use fiscal calendars by default for users whose org runs on them, instead of assuming calendar dates?
- Can it refuse invalid or many-to-many joins at compile time, instead of emitting them and double-counting silently?
- Can it enforce row-level and column-level access before SQL is generated - not after rows return from the warehouse?
- Can it hide or mask sensitive fields based on the requesting user's role, purpose, and jurisdiction?
- Can it explain which metric definition (with version) produced each number it returned?
- Can it reproduce the same answer in six months using the same definition version, the same source, the same policy snapshot?
- Can it work across multiple databases and SQL dialects without you rewriting metrics per warehouse?
- Can business owners approve or reject definitions through governance workflows - not by editing prompt templates?
If most of those answers are "no," the system is fine for analyst-assisted exploration and demos. It is not production analytics. The fixes are not bigger models or longer prompts. They are the same compile-time semantic substrate that closes the benchmark cliff - exposed to your buyer-evaluation process as ten concrete questions instead of one accuracy headline.
The fix: an autonomous semantic layer that replaces brittle RAG pipelines
The accuracy cliff has a single architectural answer: stop generating SQL probabilistically and start compiling it deterministically. An autonomous semantic layer is the infrastructure that makes this possible. It captures the meaning the LLM cannot infer from raw schema - governed metric definitions, proven join paths, entity identity, access policies - and makes that meaning the contract every AI agent compiles through. Where RAG pipelines patch context per query with retrieval and prompt engineering, an autonomous semantic layer builds the context once and resolves every query against it.
Colrows does not prompt an LLM to guess your data structure. We resolve business metrics into deterministic, governed SQL at compile time. Fix the context, not the model.
- Metric Resolution: mapping business intent to a typed, versioned schema before any SQL is drafted.
- Constraint Enforcement: applying RBAC, ABAC, and row/column-level data authorization before SQL is generated, not after the warehouse returns rows.
- Deterministic Compilation: outputting auditable, dialect-perfect, standard SQL that is reproducible for the same intent across runs.
Where Colrows sits
Colrows is built on the premise the benchmarks keep confirming: the accuracy is in the context, so the context should be infrastructure. The semantic graph - versioned, typed, multi-scope - captures the meaning the cliff studies found missing: governed metric definitions, proven join paths, entity identity across systems, policies. Every question compiles through it: intent → context resolution → constrained planning → governed execution, with compile-time governance and dialect-perfect SQL out the other side. And because the graph is built and maintained autonomously with drift detection, the structure that closes the cliff does not become a second modeling backlog. Learn more about how Colrows positions against the accuracy cliff in our pricing and product tiers.
The cliff is not a model problem wearing a data costume. It is a context problem wearing a model costume. Fix the context. Not the model.
Frequently asked questions
Why do text-to-SQL models score high on benchmarks but fail in production?
Because the benchmarks and production are different problems. Academic sets like Spider 1.0 use small, clean, well-named schemas where the question contains nearly everything needed. Real estates exceed a thousand columns, with ambiguous names, multiple plausible join paths, and decisive context that lives outside the database. Spider 2.0, built from real workflows, measured the same models at 10-21% that scored 86-91% on Spider 1.0.
What is the Spider 2.0 benchmark?
A 632-task text-to-SQL benchmark (Lei et al., ICLR 2025) derived from real enterprise workflows on BigQuery, Snowflake, and other platforms, with databases that often exceed 1,000 columns and solutions requiring multi-step SQL past 100 lines. Reported results: 21.3% for the authors' o1-preview agent framework (versus 91.2% on Spider 1.0); 10.1% for GPT-4o (versus 86.6%).
How accurate is natural language to SQL on enterprise data?
Raw generation: roughly 10-51% in published evaluations (Spider 2.0, BEAVER, Snowflake's internal set). With an explicit semantic model: 90%+ (Snowflake Cortex Analyst) to 98-100% on well-modeled questions (dbt, 2026). The spread is the whole story - accuracy tracks the structure around the model, not the model.
How can I improve text-to-SQL accuracy?
Add explicit structure: every published gain comes from a knowledge graph (16.7% → 54.2%), a semantic model (51% → 90%+), or a deterministic semantic layer (98-100%). The durable version is a governed semantic layer that queries compile through - not per-query prompt engineering rebuilt on every request.
Related governance reading
The accuracy cliff and the governance gap are two faces of the same context problem. To go deeper on the architecture that solves both:
- Data Authorization: Problem and Solution - why RBAC and ABAC enforced after SQL generation is structurally too late, and how compile-time governance closes the gap that hallucinated SQL exploits.
- The Colrows SaaS architecture - the typed semantic graph, compile pipeline, and policy engine that power deterministic, auditable SQL for AI agents.
- RAG vs. Semantic Layer - why retrieval-first architectures cannot guarantee deterministic answers, and what compilation-first infrastructure adds.
A note on the numbers
Every figure is the cited source's own published claim as of June 2026. Benchmarks are dataset-specific and several evaluation sets are small (dbt: 11 questions; Snowflake: 150) or vendor-run (AtScale's NLQ benchmark); Spider 2.0 leaderboard entries above the raw-model baseline are agentic scaffolds, often self-reported. BEAVER's near-zero figures are off-the-shelf 1-shot results from the published paper (arXiv:2409.02038); the expanded 9,128-query dataset on the project page does not yet publish populated leaderboard scores. Treat the figures as evidence of a directional pattern, not universal constants.