Why "shows its SQL" is the right filter
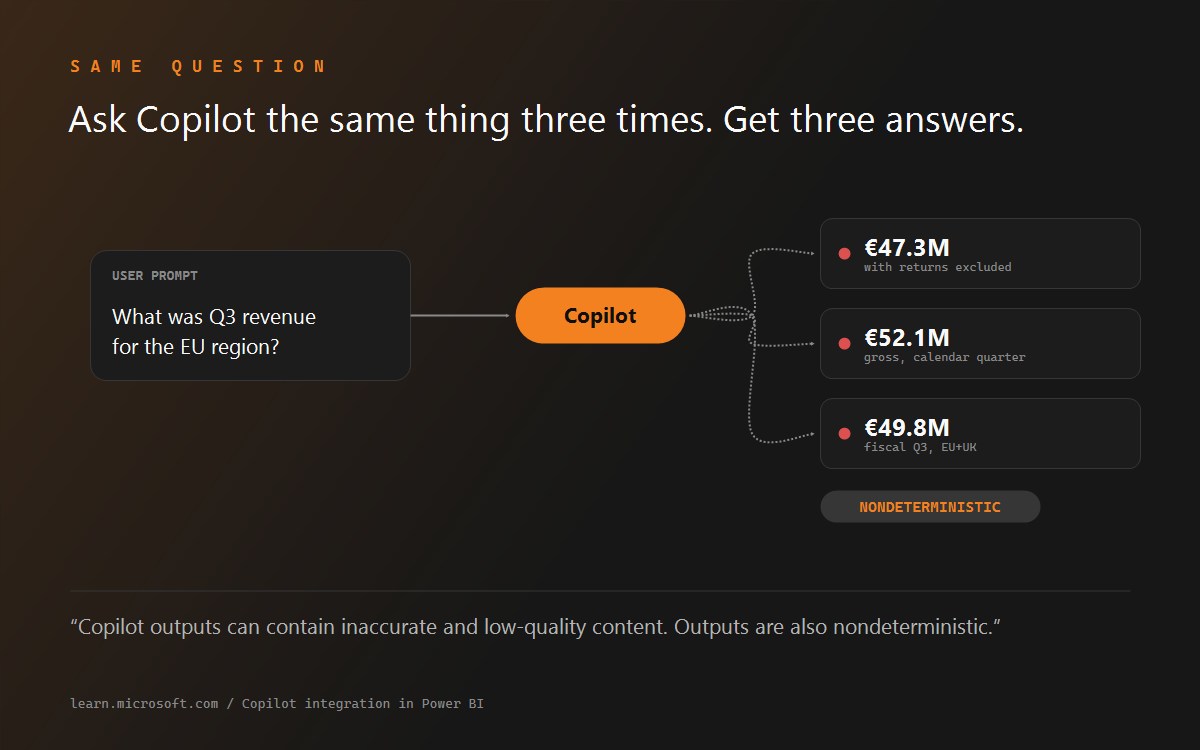
Three buyers keep arriving at this requirement from three directions. The analyst wants to debug: when a number looks wrong, the fastest diagnosis is reading the join and the WHERE clause. The data leader wants trust: business users who have been burned once by a confident wrong answer stop using the tool, and visible queries are how you re-earn the trust. The compliance officer wants evidence: a regulated decision traced to "the AI said so" is a finding, while a decision traced to a specific, reviewable query is a record. Our deep dive on the failure mode is Why Power BI Copilot Gives Confidently Wrong Answers; the cost side is in Power BI Copilot Pricing.
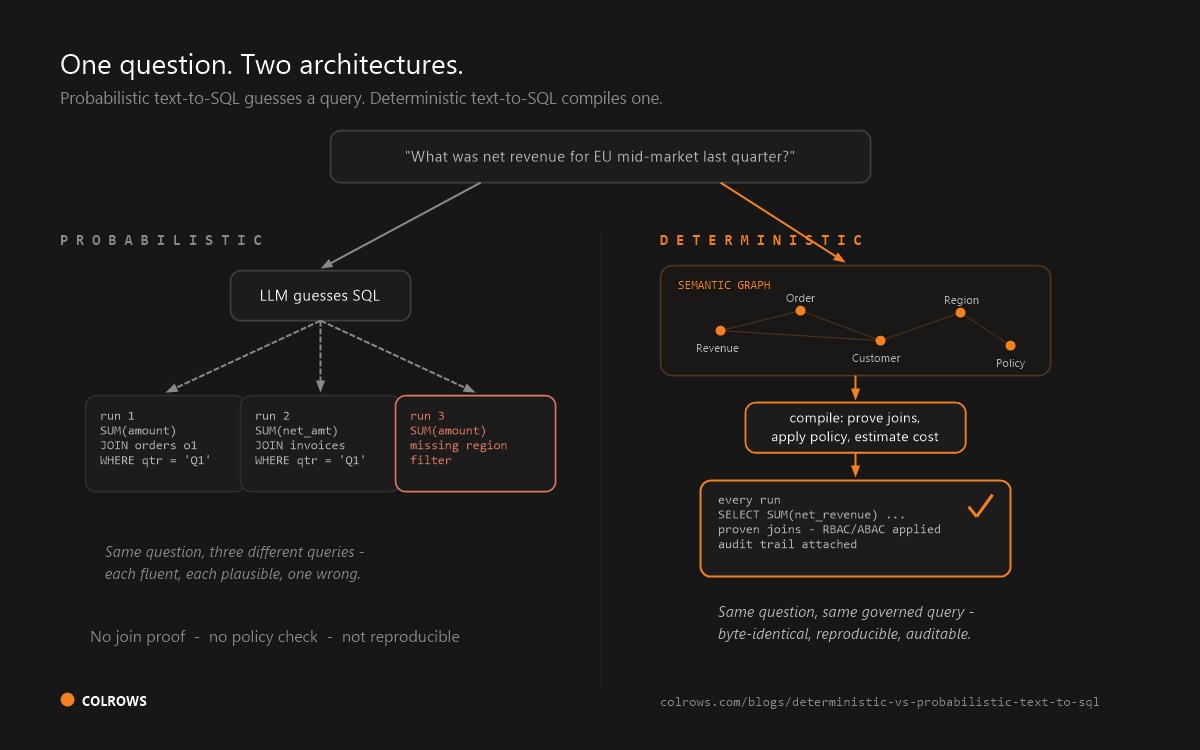
One distinction organizes the whole list, so we will state it once. Generated-then-shown: a probabilistic model writes the SQL, the tool displays it afterwards, and verification is left to whoever reads it. That is real transparency and it is worth paying for - but the model can still hallucinate a plausible join, and a wrong query you can read is still wrong. Compiled-with-proof: the SQL is constructed deterministically from a governed semantic model, joins are proven against known paths before execution, and the same question always yields the same query. The first lets you catch the error class; the second removes it. The full argument, with benchmark receipts, is in Deterministic vs Probabilistic Text-to-SQL.
Disclosure up front: Colrows is our product. It is first because it is the only entry in the compiled-with-proof class; the other six are described from their vendors' own documentation so the list stays useful even if you discount ours.
1. Colrows - compiled SQL with a join path proof (our product)
Transparency class: compiled-with-proof. Best for: regulated enterprises that need every answer to be auditable and reproducible.
Colrows does not show you the SQL a model guessed - it shows you the SQL it compiled. Every question runs through the pipeline intent → context resolution → constrained planning → governed execution: meaning is resolved against a versioned, typed semantic graph; every join in the plan carries a join path proof; RBAC + ABAC + row/column-level predicates are applied at compile time, before a byte is fetched; and the emitted SQL is deterministic and dialect-perfect for the target engine. What you inspect is therefore not a transcript of a guess but an artifact of a compilation - and the audit trail makes every answer point-in-time reproducible: you can re-derive exactly what the system knew and emitted when it answered. A question the graph cannot resolve fails loudly at compile time rather than returning something fluent. In production this is what let a confidential ARC put conversational analytics in front of RBI SARFAESI + DRT workflows with 100% regulatory coverage. Pricing: free tier + custom Enterprise. The head-to-head is in Colrows vs Power BI Copilot - ours, so read it with this disclosure in mind.
2. Snowflake Cortex Analyst - generated SQL, returned with every answer
Transparency class: generated-then-shown, semantically grounded. Best for: Snowflake estates with the team to maintain semantic views.
Cortex Analyst's API returns the generated SQL alongside each answer - inspection is part of the contract, not a buried feature. Generation is grounded in hand-authored semantic models (semantic views), which is why Snowflake's internal benchmark reports accuracy rising from roughly 51% to 90%+ on its 150-question set; execution stays inside the Snowflake perimeter and inherits warehouse RBAC and masking. The trade-offs: someone authors and maintains those semantic views per subject area, the generation step is still probabilistic under the grounding, and it answers only over Snowflake. Billing is consumption against Snowflake compute. Details and curation math: Cortex Analyst vs Genie.
3. Databricks AI/BI Genie - SQL visible per answer, curated per space
Transparency class: generated-then-shown, curation-grounded. Best for: Databricks shops running Unity Catalog.
Genie shows the SQL behind each response and lets users open it for inspection - again, transparency by design. Answers are scoped to curated "spaces" (focused bundles of tables, instructions, and example queries) and governed by Unity Catalog permissions. The caveats come from Databricks's own documentation: Genie operates nondeterministically, and shared spaces can run on the embedding author's credentials - a real review item for regulated deployments. The recurring cost is per-space curation, and cross-domain questions stop at the space boundary. For estates already on Databricks, it is the natural first evaluation; just price the curation.
4. Looker Conversational Analytics - grounded in LookML you can read
Transparency class: generated-then-shown, model-grounded. Best for: Google Cloud estates with an existing LookML practice.
Looker has always let analysts open the SQL behind an Explore, and its Gemini-powered Conversational Analytics inherits that culture: answers are grounded in centrally defined LookML, and the underlying queries are inspectable rather than hidden. The strengths and costs are the same fact: every metric is defined once by a LookML developer, which gives consistency and a famous bottleneck. Commercially, platform pricing is quote-only while the AI is metered - Gemini Data Token allowances per edition, with overage billing of $3/1M input and $20/1M output tokens from 1 October 2026. The numbers, such as Google publishes them, are in Looker Pricing in 2026.
5. Sigma (Ask Sigma) - the reasoning shown step by step
Transparency class: generated-then-shown, with visible intermediate steps. Best for: warehouse-native teams that want explorable, editable AI reasoning.
Ask Sigma deserves specific credit on this list's criterion: it exposes each step of its reasoning - the interpretation, the intermediate calculations, the path to the answer - for users to inspect and edit, not just a final query dump. Everything computes live against the cloud warehouse, so what you inspect is what ran. Limits: semantics live in your warehouse schemas and workbook logic (you maintain them), there is no published accuracy benchmark, and pricing is quote-only (Vendr median ~$62,000/year). Strong for exploration; pair it with governed definitions for regulated reporting.
6. Zenlytic - answers validated against a Git-versioned semantic layer
Transparency class: generated-then-shown, semantically validated. Best for: teams that want an AI-native analyst and accept startup risk.
Zenlytic's AI analyst ("Zoë") checks its answers against a Git-versioned semantic layer before rendering them, and the queries are visible - the same architectural instinct as the warehouse-native entries, from an AI-native startup. Version-controlled semantics also mean the definitions themselves are reviewable, diffable artifacts, which compliance teams like. The risk axis is vendor scale rather than architecture: a $9M raise as of late 2024, quote-only pricing (with a small-team self-serve tier), and a public review base too thin to cite sentiment honestly. Evaluate the architecture on its merits and the vendor on yours.
7. Metabase + Metabot - open-source SQL you can always open
Transparency class: generated-then-shown. Best for: teams that want transparent pricing and editable SQL with lighter governance needs.
Metabot generates queries you can open, read, and edit - and because Metabase is open source, the entire stack is inspectable, not just the SQL. Pricing is the most transparent in the market: $0 self-hosted, cloud from $100/month, AI at a flat $3.75 per million tokens. The documentation lists Metabot's limits plainly, which we wish were the industry norm. The honest ceiling: governance is lighter than everything above it, and third-party testing finds Metabot degrades sharply on messy models - the semantics are still yours to build and keep clean.
At a glance
| Tool | How the SQL becomes visible | Deterministic? | Governance enforcement |
|---|---|---|---|
| Colrows | Compiled artifact + join path proof + audit trail | Yes - compile-then-execute | Compile-time RBAC + ABAC + row/column predicates |
| Cortex Analyst | Generated SQL returned with each answer | No - grounded generation | Snowflake RBAC + masking |
| Databricks Genie | SQL shown per answer in the space | No - documented nondeterministic | Unity Catalog permissions |
| Looker Conv. Analytics | LookML-grounded queries, inspectable | No - grounded generation | Central LookML + access filters |
| Sigma (Ask Sigma) | Step-by-step reasoning, editable | No | Warehouse + workspace controls |
| Zenlytic | Validated against Git-versioned semantics | No - validated generation | Semantic-layer definitions |
| Metabase + Metabot | Generated SQL, fully open/editable | No | Lighter app-level controls |
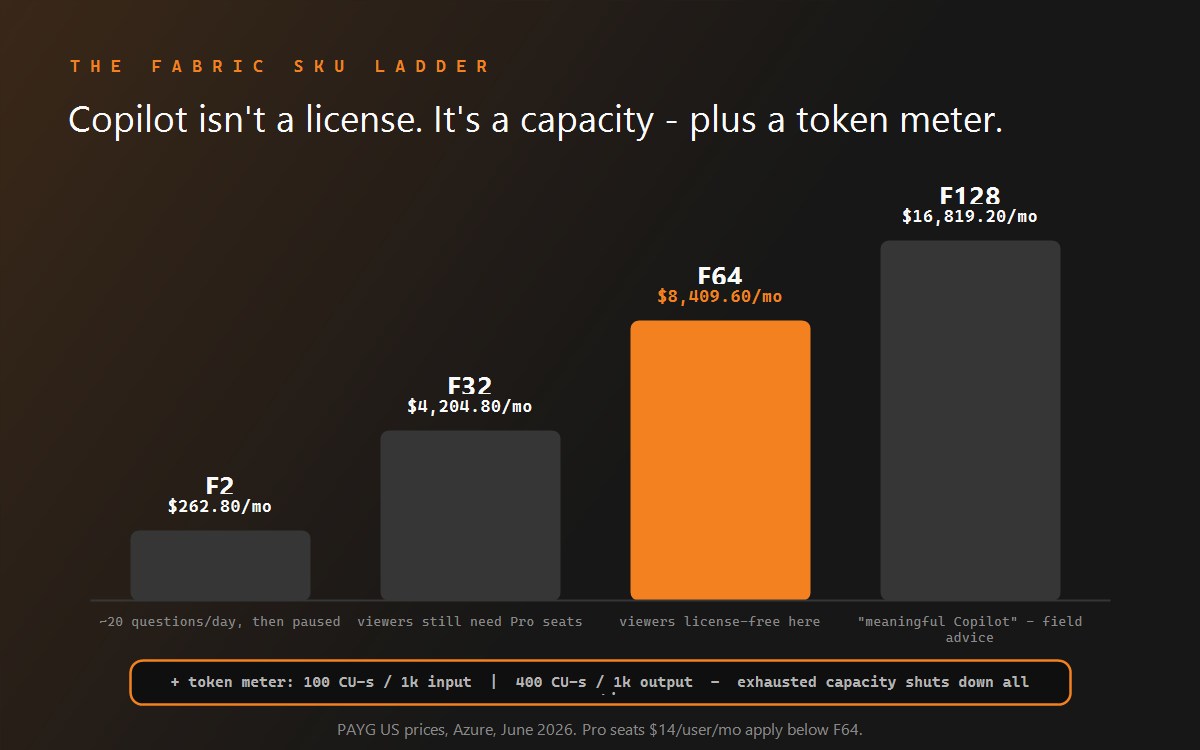
Power BI Copilot, for reference: outputs documented as nondeterministic; query logic not consistently exposed; requires paid Fabric capacity (F2 from $262.80/month) plus per-token metering.
The transparency ladder
Reading the table top to bottom, there are really three rungs, and it is worth knowing which one you are buying. Rung one: the answer is opaque - you get a visual and a narrative, and trust is the product. That is where Copilot sits today, by Microsoft's own documentation. Rung two: the answer is inspectable - the SQL is shown, errors are catchable by someone qualified to read SQL, and your audit process becomes "a human reviews the queries that matter." Six of the seven tools here live on this rung, and it is a genuine upgrade. Rung three: the answer is provable - the SQL is compiled deterministically from governed semantics, policy is enforced before execution, and the audit trail reproduces any answer point-in-time. The question that separates rungs two and three is simple to ask in a vendor evaluation: "If I ask the same question twice, do I get the same SQL - and can you prove what the system knew when it answered?" The rest of the procurement script is in the Semantic Layer Evaluation Checklist.
Frequently asked questions
Why does showing the SQL matter?
Because the SQL is the answer; the chart is its rendering. Visible queries make errors catchable, rebuild user trust, and turn "the AI said so" into an auditable record - the difference between a finding and a defensible decision in a regulated review.
Generated-then-shown vs compiled - what's the difference?
Generated-then-shown: a probabilistic model writes the query and you can read it afterwards; verification is your job. Compiled: the query is constructed deterministically from a governed semantic graph with proven join paths and compile-time policy. One catches errors; the other removes the error class.
Does Power BI Copilot show its queries?
Not reliably enough to audit. Answers render as visuals or narrative from the semantic model, the underlying logic is not consistently exposed, and Microsoft documents outputs as nondeterministic - the same question can produce different answers on different runs.
Which alternative is best for regulated industries?
Weight determinism and reproducibility first: Colrows (compiled, compile-time governance, point-in-time reproducible audit trail), then warehouse-native options (Cortex Analyst, Genie) whose visible SQL and inherited controls earn partial credit despite probabilistic generation. The regulatory bar itself is documented in Auditable SQL for Regulated Industries. For a broader comparison against search-driven platforms, see ThoughtSpot Alternatives.
A note on the claims
Vendor capabilities and caveats are taken from vendor documentation (Microsoft Learn, Snowflake and Databricks docs, Google Cloud, Sigma, Metabase) checked 12 June 2026; contract figures cite Vendr marketplace data, attributed inline. Vendor-internal accuracy figures are labelled as such. Colrows is our product; we put it first and stated why, so you can apply your own discount.