Semantic layer vs semantic compiler: the definition
A semantic layer is the model of meaning: typed entities, relationships, measures, dimensions, time grains, and access policies. A semantic compiler is the runtime that translates intent (a natural-language question, an agent function call, a workflow trigger) into executable SQL by compiling it through that model — see semantic layer vs. semantic execution layer for how this compile-time resolution differs from a traditional runtime semantic layer. Compilation means a fixed sequence happens before any data is touched:
- Concepts in the request are resolved against governed, versioned definitions.
- The join path between the entities involved is proven against known relationships.
- Access policies (RBAC, ABAC, row-level and column-level predicates) are applied as a compilation pass, injected into the plan itself.
- Deterministic, dialect-specific SQL is emitted, carrying a reproducible audit trail.
If any step cannot succeed, compilation fails loudly, with a reason: unknown concept, unprovable join, unauthorized access. The layer holds the meaning. The compiler is what makes the meaning binding.
The compiler analogy, made exact
This is not a metaphor. The correspondence is structural, and it maps cleanly onto the standard compiler pipeline from Aho, Lam, Sethi, and Ullman's Compilers: Principles, Techniques, and Tools (the Dragon Book): lexical analysis, parsing to an abstract syntax tree, semantic analysis, intermediate representation, and target code generation.
Front end: lexing, parsing, name resolution
A programming-language compiler tokenizes source and parses it into an AST, then resolves names against a symbol table. A semantic compiler takes intent as its source, parses it into a structured query specification, and resolves each concept ("revenue," "active customer," "last quarter") against the semantic graph, which is the symbol table: typed entities, relationships, and metric definitions. "Revenue" resolves to one governed definition, not a model's guess.
Semantic analysis and type checking: join-path proof
A compiler's type checker rejects programs that are syntactically valid but semantically wrong. The semantic-compiler equivalent is join-path proof: the plan must trace a known, valid path between entities. This is what prevents silently fan-out-doubled aggregates, the single most common class of wrong-but-plausible analytics answers.
Code generation: dialect-specific SQL
A compiler emits target code per architecture. A semantic compiler emits dialect-perfect SQL per engine (Snowflake, BigQuery, Databricks, Redshift, Postgres, and others) from one semantic model. SQL is the intermediate representation and the target language at once. This is the foundation of why SQL will not die as the semantic layer compile target.
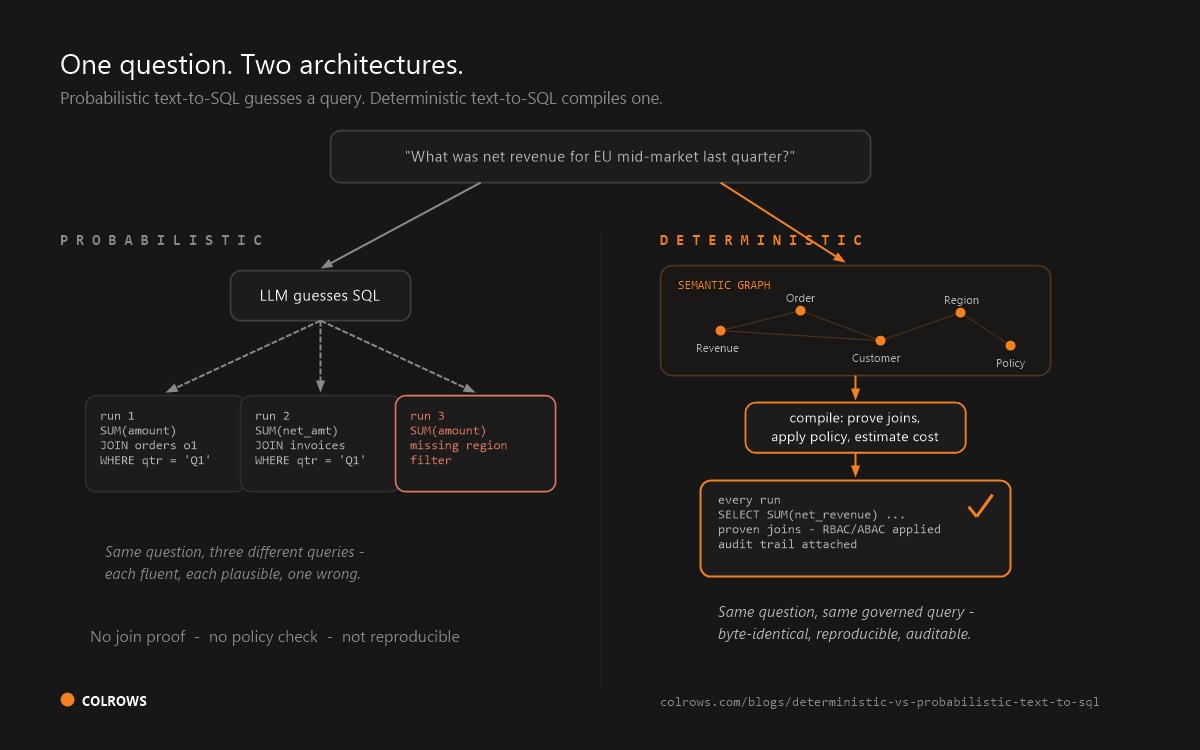
Determinism is what compilation IS
Nobody asks whether their C++ compiler will emit a different binary on the second run, and nobody audits a binary by asking the compiler to "explain its reasoning." Determinism and provenance are not features bolted onto a compiler; in formal terms they follow from referential transparency, the property that the same input always produces the same output. The reproducible-builds movement in software engineering treats compiler non-determinism as a defect to be eliminated, not a quirk to tolerate. Apply that standard to analytics and you have the entire argument for the category. See the full evidence in deterministic vs probabilistic text-to-SQL.
Why "semantic layer" alone is no longer enough
For a decade, the layer-without-a-compiler gap was tolerable, because the consumer was a human in a BI tool. The constrained surface (dropdowns, predefined explores) meant consultation and enforcement blurred together. The lineage runs from Business Objects, which coined "semantic layer" in the early 1990s and filed a 1991 patent for a "relational database access system using semantically dynamic objects" (the "universe"), through OLAP cubes such as Essbase and SQL Server Analysis Services, through Looker's LookML in 2012, to the headless BI movement (Cube, dbt MetricFlow) that decoupled the model from the BI tool.
AI changed the consumer. An LLM asked a free-form question does not look definitions up; it generates. A layer it merely consults is advisory context the model may or may not honor. The vendors document this themselves. Microsoft's Power BI Copilot documentation states plainly: "Because AI instructions are unstructured guidance to Copilot, the LLM only interprets them. There's no guarantee that the LLM will exactly follow instructions." The benchmark record is just as clear, and it is the strongest evidence a buyer can demand.
The text-to-SQL accuracy cliff: the empirical case
Public benchmarks show that raw LLM SQL generation collapses as schemas get realistic:
- Spider 1.0 (clean academic databases): top methods reach about 86-91% execution accuracy. This is the number that shows up in demos. GPT-4 reached 86.6%.
- BIRD (larger, noisier, real-world databases): human experts reach 92.96% execution accuracy. GPT-4 with evidence reached only 54.89% in the original 2023 study; as of 2026 the leading system (AskData with GPT-4o) reaches 81.95% on the test set.
- Spider 2.0 (real enterprise workflows, databases with over 1,000 columns, BigQuery and Snowflake dialects): in the ICLR 2025 paper, the best agent built on o1-preview "successfully solves only 21.3% of the tasks, compared with 91.2% on Spider 1.0 and 73.0% on BIRD." GPT-4 alone solved just 6.0%.
- BEAVER (an enterprise data-warehouse benchmark from MIT, September 2024): off-the-shelf LLMs including GPT-4o score effectively zero, roughly 0 to 2% execution accuracy, on the warehouse-native queries.
The pattern is unambiguous: accuracy is a function of schema realism, and enterprise schemas are exactly where generation fails. The cause is architectural, not a lack of model intelligence. The LLM lacks the business context (which of ord_amt, revenue_adj, net_rev_usd is "revenue"), the correct grain, and the join semantics. A semantic layer supplies that context, and the published vendor benchmarks show the jump. dbt Labs reran its 2023 comparison in 2026 and reports near-100% accuracy for queries covered by the Semantic Layer, attributing it directly to deterministic query generation: when the LLM picks the right metric and dimensions, MetricFlow guarantees the SQL is correct, and, crucially, the LLM "can't produce correct-looking numbers that are subtly different across runs."
Determinism is a separate problem from accuracy
Even at temperature zero, hosted LLM inference is not guaranteed to be reproducible. Floating-point non-associativity, GPU kernel scheduling, dynamic request batching, and load-balanced hardware all introduce run-to-run variation. OpenAI documents that its seed parameter is best-effort only. Anthropic's API documentation states: "Note that even with temperature of 0.0, the results will not be fully deterministic." For a regulated report, "usually the same" is not the same as "the same." A compiler closes this gap by construction: the LLM, when present, only maps phrasing to concepts; the compiler does the generation deterministically.
Why determinism matters for regulated enterprises
Audit and compliance regimes (SOX for financial reporting, GDPR for personal data, sectoral rules in financial services and healthcare) require that a number can be reproduced and explained. Point-in-time reproducibility, re-running yesterday's question against yesterday's definition versions and getting yesterday's answer, is the property regulators actually test. A probabilistic generator cannot offer it even in principle. A compiler treats it as a baseline guarantee, the way reproducible builds do in software.
The cost of inconsistent definitions is not abstract. Gartner's Magic Quadrant for Data Quality Solutions (27 July 2020, authors Melody Chien and Ankush Jain), based on a survey of 154 reference customers across 16 vendors, found that "poor data quality costs organizations on average $12.9 million per year." That cost compounds when every AI agent multiplies an inconsistent definition across thousands of decisions.
| Programming-language compiler | Semantic compiler | The guarantee it buys |
|---|---|---|
| Source code | Intent: a question, agent call, or trigger | One front end for every consumer |
| Symbol table + type system | The semantic graph: typed entities, relationships, metric definitions | "Revenue" means one governed thing, not a model's guess |
| Name resolution | Context resolution against versioned definitions (multi-scope: global → datastore → persona → user) | Ambiguity resolved by rules, not probability |
| Type checking | Join path proof: the plan must trace a known, valid path between entities | No silently fan-out-doubled aggregates |
| Semantic analysis passes | Compile-time governance: policies injected before SQL exists | Unauthorized queries never reach the warehouse |
| Code generation per target | Dialect-perfect SQL per engine (Snowflake, Databricks, BigQuery, Postgres, 16+) | One semantic model, many warehouses |
| Compile error | A refusal with a reason | Failure is loud, not fluent |
| Debug symbols / build provenance | Audit trail: definitions version, join proof, policies applied, point-in-time reproducible | Yesterday's answer can be re-derived byte-for-byte |
Notice what the analogy predicts: nobody asks whether their C++ compiler will produce a different binary if they compile twice, and nobody audits a binary by asking the compiler to "explain its reasoning." Determinism and provenance are not features bolted onto compilers - they are what compilation is. The same standard, applied to analytics, is the whole argument. (We made the SQL-as-target-language case in Why SQL Will Not Die; this page is about everything that happens before the SQL.)
The architecture of a semantic compiler
- Input: business definitions. Entities, dimensions, measures, joins, time grains, and policies, typed and versioned. This is the semantic graph, the symbol table.
- Front end: intent parsing and multi-scope context resolution (global, datastore, persona, user), so ambiguity is resolved by rules, not probability.
- Middle: an intermediate representation for metric logic, on which the compiler proves join paths, applies governance passes, and runs optimizations (predicate pushdown, scan reduction, aggregate routing).
- Back end: dialect-specific SQL code generation, with caching and query planning.
- Cross-cutting: lineage tracking and an audit trail recording which definition versions, join proofs, and policies produced each answer, so it is point-in-time reproducible.
- Consumption: humans via chat-to-chart and governed self-service; AI agents via HTTP, JDBC, and the Model Context Protocol (MCP) or function calling. The same pipeline serves both.
How the landscape compiles today
Every modern semantic tool generates SQL from a declarative model. They differ on when generation happens and whether enforcement is structural or advisory. None of these is "wrong"; the question is what guarantee each gives an AI consumer.
- dbt Semantic Layer / MetricFlow compiles metric requests into a dataflow DAG and renders engine-specific SQL at query time across seven engines. Coverage-bounded, but the closest mainstream design to compilation.
- Cube is an open-source headless layer with a mature pre-aggregation caching engine, REST/GraphQL/SQL/MDX, and an MCP server. Query-time generation; interoperable and open.
- AtScale is a universal semantic layer presented as virtual OLAP cubes that markets deterministic, governed execution and agents that resolve through semantic objects rather than generated SQL.
- Looker / LookML is the original code-based model with deterministic calculations, now exposed via JDBC and grounding Conversational Analytics.
- Power BI uses Tabular/DAX semantic models with row-level security and TMDL. Deterministic DAX, but engine-bound to Analysis Services.
- Snowflake Semantic Views with Cortex Analyst give Cortex a native governed object to read before it generates SQL. This improves grounding, but an LLM still generates.
- Databricks Unity Catalog Metric Views are catalog-registered YAML metrics that separate measures from dimensions and rewrite the correct computation at runtime, with catalog RBAC and lineage.
The throughline: most of these are models that tools and LLMs consult. A compiler is a model that every query must pass through and prove itself against. The Open Semantic Interchange standard, announced in September 2025, makes the definitions portable across them. For the full side-by-side on graph autonomy, dialect coverage, governance, and audit, see the semantic layer platform comparison.
Why this matters now (2025-2026)
The consumer of your data is becoming an agent, and the industry has noticed. Gartner's 2026 Data and Analytics predictions elevate the universal semantic layer to a "non-negotiable foundation" and forecast it will be treated as critical infrastructure by 2030, alongside data platforms and cybersecurity. Y Combinator's Summer 2026 Request for Startups names the "Company Brain," a system that structures fragmented company knowledge into an executable, current, trustworthy layer that AI can act on safely. A deterministic semantic compiler over the data estate is the analytics-grade instance of exactly that primitive. When every vendor ships a semantic something, the differentiating question is no longer who has a layer. It is who has the compiler.
The five properties that qualify: your evaluation test
Ignore the word the vendor uses. Test for the properties. A system is a semantic compiler if and only if:
- Determinism. The same question against the same definitions version produces the same SQL, every run. Not usually; every run. Caching identical prompts masks variance; it does not remove it.
- Versioned inputs. Every answer can name the exact definitions it compiled from: which version of
revenue, which join paths, which policies. - Loud failure. A question it cannot answer correctly returns a compile error with a reason, never a plausible guess. Ask a vendor to demo a failure; it is the most revealing demo in the category.
- Governance as a compilation pass. Policies are applied before SQL exists, per requesting user, so unauthorized queries are never generated, not generated and then filtered.
- Reproducibility. Point-in-time re-execution: yesterday's question against yesterday's versions yields yesterday's answer.
A sixth property decides whether the first five stay true: who maintains the model as the estate drifts. A compiler enforcing stale definitions is precisely wrong. An LLM can sit in front of a semantic compiler, interpreting intent, without breaking any property, because interpretation feeds the compiler rather than replacing it. That is how natural language and determinism coexist.
Where Colrows sits
Colrows is a semantic compiler with its semantic layer built in, which is what "semantic execution layer" means. The graph (versioned, typed, multi-scope, autonomously maintained) is the symbol table. The pipeline (intent, context resolution, constrained planning, governed execution) is the compiler. The outputs satisfy all five properties: deterministic dialect-perfect SQL, versioned definitions behind every answer, compile errors instead of guesses, compile-time RBAC, ABAC, and row/column predicates, and point-in-time reproducible audit trails. Humans consume it as chat-to-chart and governed self-service; agents consume the same pipeline over HTTP, JDBC, and MCP. Pricing follows schema complexity and query volume rather than per-seat, because the consumer is increasingly an agent, not a person. Fix the context, not the model.
Conclusion
The layer is what your data means. The compiler is why anyone can trust an answer about it. As AI agents become the primary consumers of enterprise data, the gap between a model you consult and a model you enforce becomes the gap between a plausible answer and a provable one. If you are evaluating semantic infrastructure, run the five-property test against your shortlist, and against us. Prove the query, then run it.
Sources and fact verification
Benchmark figures, vendor documentation, and the competitive landscape reference primary sources (arXiv papers, vendor docs, Gartner, Microsoft Learn, dbt Labs) current as of 12 June 2026. The definition of semantic compiler is our own — we coined the framing because we build the thing — and the five properties are stated so you can test any vendor against them, including us. The architecture section references Aho et al.'s Compilers: Principles, Techniques, and Tools (Dragon Book) for the standard compiler pipeline mapping. Gartner figures come from their 2026 Data and Analytics summit predictions, and the cost figure from their 27 July 2020 Magic Quadrant for Data Quality Solutions. This page is reviewed quarterly.
Frequently asked questions
What is a semantic compiler?
A semantic compiler is the runtime that compiles intent (a question, agent call, or trigger) into governed SQL through an explicit semantic model: resolves concepts against versioned definitions, proves join paths, applies governance as a compile-time pass before SQL exists, emits deterministic dialect-specific SQL with an audit trail, and returns a compile error with a reason when compilation cannot succeed.
What is the difference between a semantic layer and a semantic compiler?
The semantic layer is the artifact (the model of meaning: metrics, entities, relationships, policies). The semantic compiler is the enforcement runtime every query must pass through. Most products ship a layer that tools or LLMs consult; few ship a compiler that makes every query prove itself. Consultation is not enforcement.
Is text-to-SQL a semantic compiler?
No. Generation is probabilistic, non-reproducible across runs, and fails fluently. Text-to-SQL that consults a semantic layer is better-informed generation, not compilation.
Why does LLM SQL generation fail on enterprise schemas?
On realistic benchmarks (Spider 2.0, BEAVER), top models drop from about 86% on clean academic data to the low 20s or near zero, because they lack business context, correct grain, and join semantics.
Why do regulated industries need deterministic SQL?
SOX, GDPR, and financial-reporting rules require that a number be reproducible and explainable. Probabilistic generation cannot guarantee point-in-time reproducibility; a compiler can.
Can an LLM work with a semantic compiler?
Yes. The LLM interprets intent and maps phrasing onto concepts; the compiler generates the SQL deterministically. That is how natural language and determinism coexist.
How do I evaluate a semantic compiler?
Test the five properties: determinism (same input, same output, every run), versioned inputs (you can name which definitions compiled each answer), loud failure (compile errors, never guesses), governance as a compilation pass (policies applied before SQL), and reproducibility (yesterday's question against yesterday's versions yields yesterday's answer), plus a sixth: who maintains the model as your estate drifts.