The 30-second version
- Text-to-SQL wins at exploration, prototyping, and engineer-supervised scratch work, anywhere a human reads the SQL before anyone trusts the number.
- A semantic layer wins at mission-critical, recurring, governed metrics, anywhere a wrong answer has consequences and no human is checking the query.
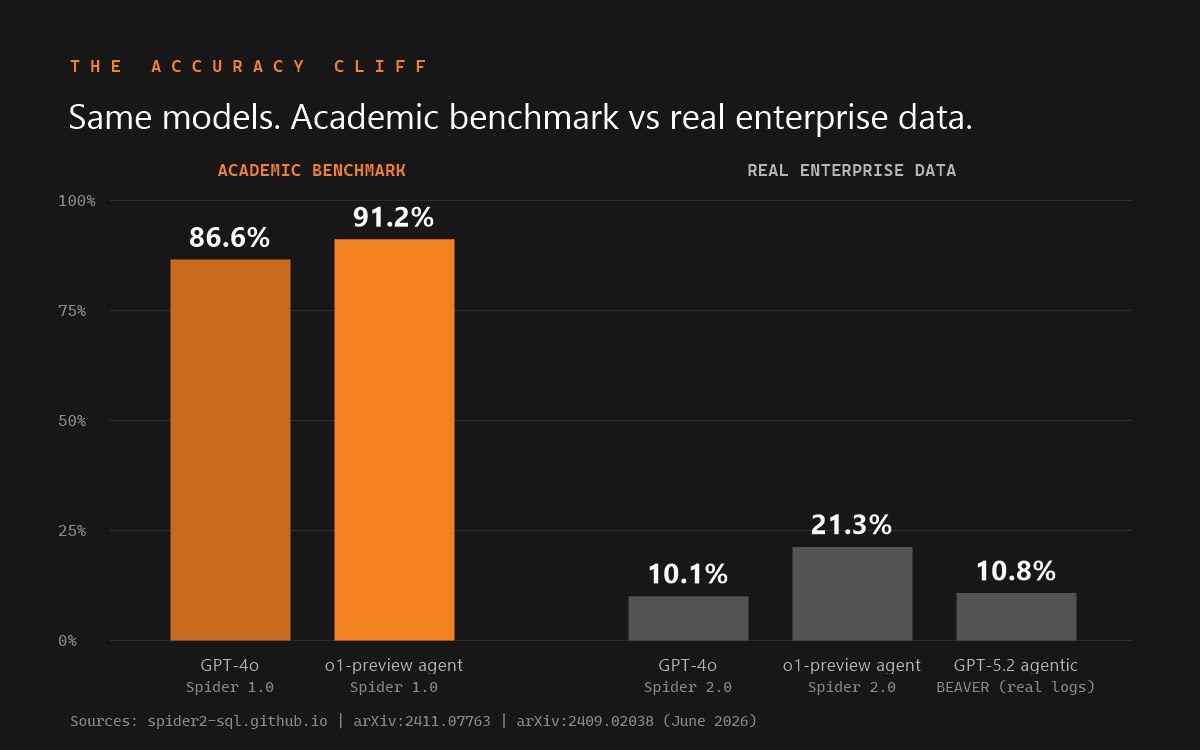
- The benchmarks are not close on hard enterprise data. Frontier models score 86-91% on academic schemas and 10-21% on enterprise-realistic ones. Adding a semantic model recovers most of that gap.
- The mature pattern is hybrid: semantic layer for the recurring 80%, text-to-SQL for the ad-hoc 20%.
What each one actually is
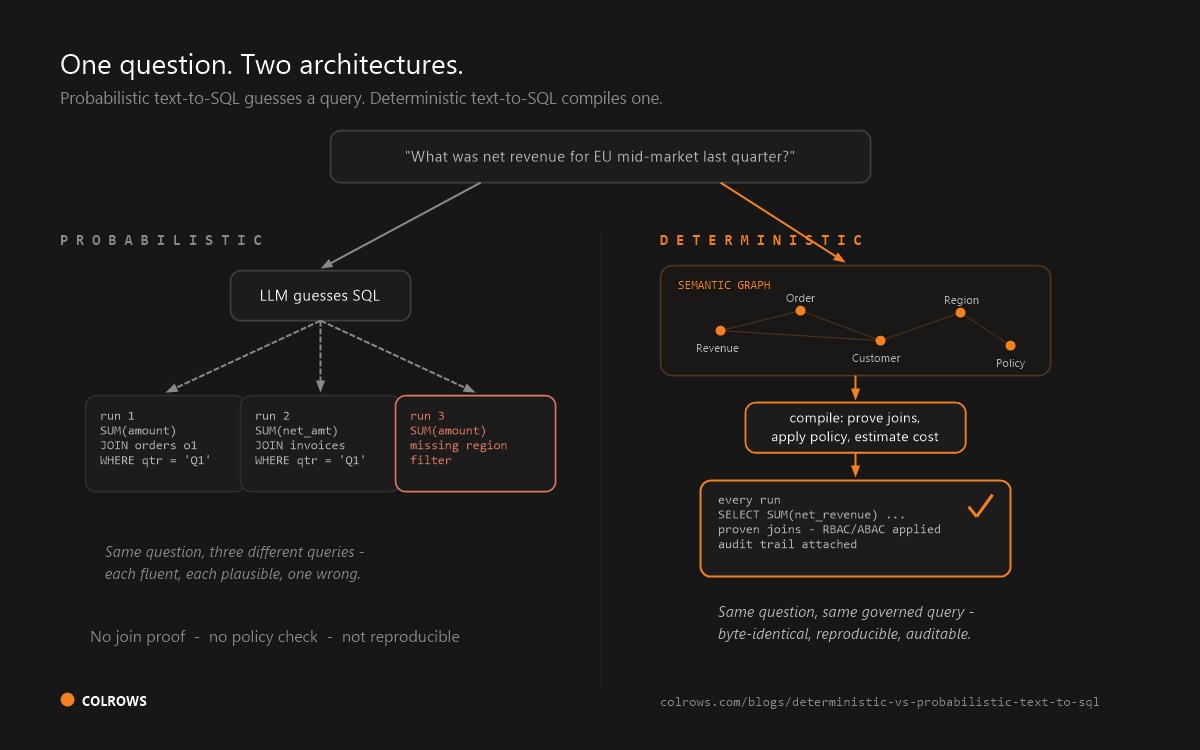
Text-to-SQL is generation. The model gets the question plus whatever context fits (table DDL, sample rows, maybe retrieved documentation, maybe a few example query pairs) and predicts SQL one token at a time. Chain-of-thought prompting makes it reason in steps; few-shot examples bias it toward your patterns; temperature controls randomness; agentic wrappers let it execute, see errors, and retry. The defining property survives every wrapper: the SQL is composed fresh, probabilistically, per request. Ask twice, you can get two queries.
A semantic layer is compilation. You define entities, relationships, metrics, join paths, and policies once, as typed and versioned objects. A question resolves against that model, the engine proves a valid join path, applies governance, and emits SQL mechanically. The LLM's job shrinks from "write correct SQL about a business it has never seen" to "map this question onto defined concepts." SQL as a compiler target puts it plainly: if the model picks the right metric and dimensions, "the query is guaranteed to be correct." (The distinction between resolving that logic at runtime versus compiling it upfront is explored in semantic layer vs. semantic execution layer.)
These are not two maturity levels of one thing. They are two answers to one question: where should the knowledge of what your data means live, in per-query model judgment, or in reviewable infrastructure?
Why text-to-SQL fails on real schemas (the mechanics)
This is the part a data engineer needs, because the failure modes are specific and they compound.
1. Schema linking. Mapping the words in a question to the right tables and columns. It is easy on a 15-table toy schema and brutal on a real one. On the Spider 2.0 enterprise benchmark, databases average over 755 columns versus roughly 54 in BIRD, and "wrong schema linking" is the single largest error class at 27.6% of failures. Cross-database studies put schema-linking errors at over 60% of all failures. Multi-hop query understanding compounds this when questions span multiple tables.
2. Join-path explosion and fan-out. When several join paths connect two tables, the model has to pick the right one. Enterprise warehouses on BigQuery often lack declared foreign keys, so the model infers keys from column names and gets them wrong. Pick a one-to-many join carelessly and you get fan-out: rows multiply, and your SUM silently doubles. Spider 2.0 attributes 8.3% of failures to JOIN errors specifically.
3. The grain problem. Counting rows when you should sum values. Missing a GROUP BY. Double-counting after a multi-hop join. On Spider 2.0, "erroneous data analysis" is the biggest bucket at 35.5%, including advanced calculation (7.5%) and intricate query planning (17.7%). Warehouse platforms document a model filtering a date range before a rolling-window calculation, corrupting the first three days of every window, a query that looks perfect and is wrong.
4. Hallucination. Inventing a column, a function, or a join that does not exist. In Spider 2.0 this is folded into schema linking: the model requests tables or columns that "do not exist."
5. Nondeterminism. This is the one that breaks trust. Even at temperature 0, LLMs are not reliably repeatable. The paper "Non-Determinism of 'Deterministic' LLM Settings" measured "accuracy variations up to 15% across naturally occurring runs with a gap of best possible performance to worst possible performance up to 70%," concluding that "none of the LLMs consistently delivers repeatable accuracy." The cause is structural: floating-point addition is not associative, GPUs sum in parallel in varying order, requests get batched differently, and mixture-of-experts routing shifts. You cannot fully prompt your way out of it. That is why finance got a different number on Monday.
6. Silent wrong answers. Every failure above shares one trait. The SQL runs. It returns a plausible number. Nothing throws an error. There is no natural predator for a fluent wrong answer once a human stops reading the query.
-- Question: "What was our net revenue in EMEA last quarter?"
-- Text-to-SQL output (looks fine, three subtle bugs):
SELECT SUM(o.amount) AS net_revenue
FROM orders o
JOIN regions r ON o.region_id = r.id
WHERE r.name = 'EMEA'
AND o.created_at >= '2026-01-01';
-- Bug 1: amount is gross, not net (no refunds/credits subtracted)
-- Bug 2: a one-to-many join to a shipments table inflates the sum (fan-out)
-- Bug 3: "last quarter" hardcoded; "EMEA" misses the 'EU-West' code used in this table
-- It executes. It returns a number. The number is wrong. No error is raised.# Semantic-layer equivalent: the answer is a compiled definition, not a guess
metric: net_revenue
expr: SUM(orders.amount) - SUM(orders.refunds) - SUM(orders.credits)
grain: order_id # fan-out is structurally impossible
join_path: orders -> regions # proven valid at compile time
filter: emea
expr: regions.code IN ('EU-WEST','EU-CENTRAL','EU-SOUTH','MEA')
# Ask the same question 1,000 times -> identical SQL, identical number.
# Ask an UNCOVERED question -> a compile error, not a wrong number.The benchmarks, with conditions attached
Do not cherry-pick. Here is the published evidence with test conditions, so you can judge relevance to your own data.
| Benchmark | Date / venue | Conditions | Text-to-SQL result | With semantics / humans |
|---|---|---|---|---|
| Spider 1.0 | Yu et al., EMNLP 2018 | 200 DBs, 10,181 Qs, clean academic schemas | GPT-4o 86.6%; DAIL-SQL+GPT-4 86.6% | n/a |
| BIRD | arXiv:2305.03111, NeurIPS 2023 | 95 real DBs, 12,751 pairs, 33.4 GB, dirty values | GPT-4 54.89% w/ evidence, 34.88% without; SOTA ~82% | Humans 92.96% |
| Spider 2.0 | arXiv:2411.07763, ICLR 2025 | Enterprise warehouses, >1,000 columns, multi-dialect | GPT-4o 10.1%, o1-preview 17.1% | (vs 86.6% on Spider 1.0) |
| BEAVER | arXiv:2409.02038, MIT 2024 | Private warehouse logs, 812 tables, 19 domains | GPT-4o 0.0% (retrieval), 2.0% (retrieval-free) | SOTA agentic 10.8%; oracle hints 30.1% |
| Sequeda / data.world | arXiv:2311.07509, Nov 2023 | Insurance schema, 43 enterprise questions | GPT-4 zero-shot SQL 16.7% | Knowledge graph 54.2% (3x); raw SQL 0% on high-complexity |
| dbt 2026 | dbt Labs, 7 Apr 2026 | ACME Insurance, 11 Qs × 20 runs, 15 tables | Sonnet 4.6 90.0%; GPT-5.3 Codex 84.1% | Semantic Layer 98.2% / 100.0% |
| Snowflake Cortex | Snowflake, 29 Aug 2024 | 150-question internal BI set | GPT-4o single-prompt 51% | Cortex Analyst (semantic) 90%+ |
Read it honestly in both directions. Models have gotten genuinely good: dbt's text-to-SQL number nearly doubled from 32.7% (GPT-4, 2023) to 64.5% (2026 models) on the same questions, and reached 84-90% once the underlying data was modeled well. Better modeling helps both approaches. But the gap on hard, realistic data is real and consistent, and every published recovery comes from adding explicit structure: a semantic model, a knowledge graph, declared keys. The decisive context (which revenue column is the governed one, which join path is approved, what "active" means) is not in the schema. No amount of token prediction recovers information that was never there.
One caveat for the skeptics: the academic benchmarks are imperfect. A 2026 audit found roughly 32% annotation errors in parts of BIRD, and strict pass/fail execution accuracy agrees with human judgment only about 62% of the time. Treat any single number as directional. The pattern across seven independent benchmarks is what holds.
Where text-to-SQL is genuinely the right call
We sell a semantic layer, so take this section as the part we are not incented to write. Text-to-SQL is the correct architecture whenever a SQL-literate human reviews the query before anyone trusts the number:
- Engineering scratch work. An analyst asking a model to draft a gnarly window function. The human is the verification layer.
- One-off exploration. Unfamiliar dataset, throwaway questions, no decision riding on the result.
- Prototypes and demos. Proving the interaction pattern before investing in the meaning layer.
- Migration tooling. Generating candidate dialect translations, with tests as the arbiter.
The common thread: the SQL gets read. The architecture flips at the exact moment consumers stop reading it, a business user in a chat window, a scheduled report, an AI agent acting on the result. That is the production boundary, and it is sharper than most roadmaps admit.
The cost nobody puts in the demo
Text-to-SQL's demo economics are seductive: no modeling, just a prompt. Production economics invert.
- Inference compounds. Production-grade text-to-SQL is not one model call. The systems near the top of enterprise leaderboards run agentic scaffolds. Published multi-step pipelines like CHESS use about 78 LLM calls and 339,000 tokens per query at roughly 47 seconds of latency. You pay that token and latency bill on every query, forever, to rebuild context the architecture refuses to persist.
- Evaluation becomes a department. Without deterministic behavior, your only safety mechanism is empirical: golden-question suites, regression runs per model release, prompt-injection review, accuracy dashboards. Teams budget the model and forget the harness around it.
- The semantic layer's cost is the modeling. It is real and upfront, then amortized across every query, and it regression-tests like any other software artifact. Compile-time generation runs sub-second.
The hybrid pattern is the mature architecture, not a compromise
Here is the part the "X vs Y" framing gets wrong. The serious platforms have already answered this question, and they all answered "both."
Snowflake Cortex Analyst is agentic text-to-SQL grounded in a semantic model; that grounding is what takes GPT-4o from a measured 51% (where "its accuracy plummeted") to "over 90% accuracy on real-world BI use cases," nearly 2x single-prompt generation. Databricks Genie reads Unity Catalog Metric Views and compiles governed definitions deterministically; one published curation case moved a Genie space from 50% to 90% after adding declared keys, Metric Views, and example queries. And dbt's own recommendation after rerunning its benchmark is exact: "The answer isn't text-to-SQL vs. Semantic Layer. It's both, for different things."
The pattern in practice:
- Route mission-critical, recurring questions through the semantic layer. Board metrics, regulatory reports, KPIs, anything an agent acts on. When the layer can answer, it is right. When it cannot, it returns an error, not a wrong number.
- Fall back to text-to-SQL for ad-hoc discovery. New questions, exploration, prototyping, with the understanding that a human should read the result.
- Expand coverage over time. The recurring questions are a small, knowable set. Model them. The dbt benchmark showed that "with just 3 additional models, the Semantic Layer can now answer every question in the benchmark."
The distinction that matters most in production: text-to-SQL fails as a plausible wrong answer; the semantic layer fails as an error message. For a board deck, an auditor, or a KPI dashboard, that difference is everything.
Why this matters more for regulated enterprises
If you operate under BCBS 239, SOX, HIPAA, or the EU AI Act, "the model probably got it right" is not a control you can present to an auditor. BCBS 239 requires transparent, traceable lineage from source to report; regulators expect you to trace every risk metric back to its origin. A nondeterministic generator that produces a different query on re-run, with no stable definition behind the number, cannot satisfy that. A semantic layer produces versioned definitions, a proven join path, compile-time governance (RBAC, ABAC, and row/column predicates applied before the SQL exists), and a point-in-time-reproducible audit trail. For regulated, audit-heavy analytics, the semantic layer is not an optimization. It is the control.
Where Colrows fits, honestly
Colrows is the compilation path, built to span the estate rather than stop at one warehouse boundary. It builds a typed, versioned semantic graph across PostgreSQL, Snowflake, BigQuery, Databricks, and Redshift, then runs a compile-then-execute pipeline: resolve intent, prove the join path, enforce governance at compile time, emit dialect-correct SQL, and return an answer with an audit trail. The LLM interprets intent; it never freehands the SQL. Failure is a compile error with an explanation, not a confident guess. For a framework on evaluating your options, see the semantic layer buyer's guide.
The honest limits: a semantic layer requires upfront modeling; it does not do open-ended discovery as well as raw generation; and it governs structured data semantics, not documents or broad unstructured context. It is one layer of a larger stack. If your AI agents issue thousands of governed queries an hour across multiple sources under audit, that is exactly the job it is built for. For a data scientist poking at an unfamiliar table on a Friday afternoon, text-to-SQL is still the right tool. Use both, in their right layers.
Text-to-SQL asks the model to be right. A semantic layer makes it unnecessary for the model to be right. Use the first to explore. Use the second when the number has to be trusted.
Frequently asked questions
What is the difference between a semantic layer and text-to-SQL?
Text-to-SQL generates SQL probabilistically from the question and schema, fresh each time. A semantic layer resolves the question against versioned business definitions and compiles SQL from them deterministically. The difference is where correctness lives: in per-query model judgment, or in reviewable infrastructure.
Is text-to-SQL accurate enough for production?
On clean academic schemas, frontier models hit 86-91%. On enterprise-realistic benchmarks (Spider 2.0, BEAVER) the same models score 10-21%, and they fail as plausible wrong answers rather than errors. It is fine where a human reads the SQL; it is risky for business-user self-service, regulated reporting, or autonomous agents.
When should I use text-to-SQL?
Exploration, prototyping, one-off questions, dialect migration, and engineer-supervised scratch work, anywhere the SQL is read before the number is trusted.
When should I use a semantic layer?
Mission-critical, recurring, governed metrics: board data, KPIs, regulatory reports, and anything an AI agent acts on without a human in the loop.
Why does a semantic layer improve accuracy?
The errors come from missing business meaning, not weak models. Making meaning explicit and compiling through it is the only intervention with consistent published gains: 16.7% to 54.2% with a knowledge graph (Sequeda), 51% to 90%+ with Snowflake's semantic model, and up to 100% on covered queries with dbt's deterministic layer.
Can I use both together?
Yes, and you should. Route recurring mission-critical questions through the semantic layer and fall back to text-to-SQL for ad-hoc discovery. This is what Snowflake Cortex Analyst and Databricks Genie do internally.
What does "deterministic" actually mean here?
Same question plus same model version yields the same SQL and the same answer every time. The intent-resolution step still uses an LLM, but the SQL generation is compiled from fixed definitions, so the output is reproducible and auditable.
Does a semantic layer replace text-to-SQL?
No. It is a different tool for a different job. Text-to-SQL is for discovery; the semantic layer is for trusted, governed answers.
What is the cost difference?
Text-to-SQL pushes cost into per-query inference (agentic systems can run dozens of LLM calls and hundreds of thousands of tokens per question) plus an ongoing evaluation harness. A semantic layer pushes cost upfront into modeling, then amortizes it across every query at compile-time speed.