Raw LLM SQL vs semantic-layer text-to-SQL
The single most important distinction. A model guessing SQL against raw tables is not the same as a model whose output is constrained by a governed semantic layer.
| Dimension | Raw LLM text-to-SQL | Semantic-layer text-to-SQL |
|---|---|---|
| Enterprise accuracy | ~21% on Spider 2.0; near 0% on BEAVER off-the-shelf | Far higher: the layer supplies context and constraints |
| Determinism | Same question can yield different SQL | Deterministic when compiled against a typed graph |
| Governance | Applied after generation, if at all | Enforced before or during compilation |
| Join safety | Guessed; can fabricate joins | Proven or refused |
The accuracy reality (why the semantic layer matters)
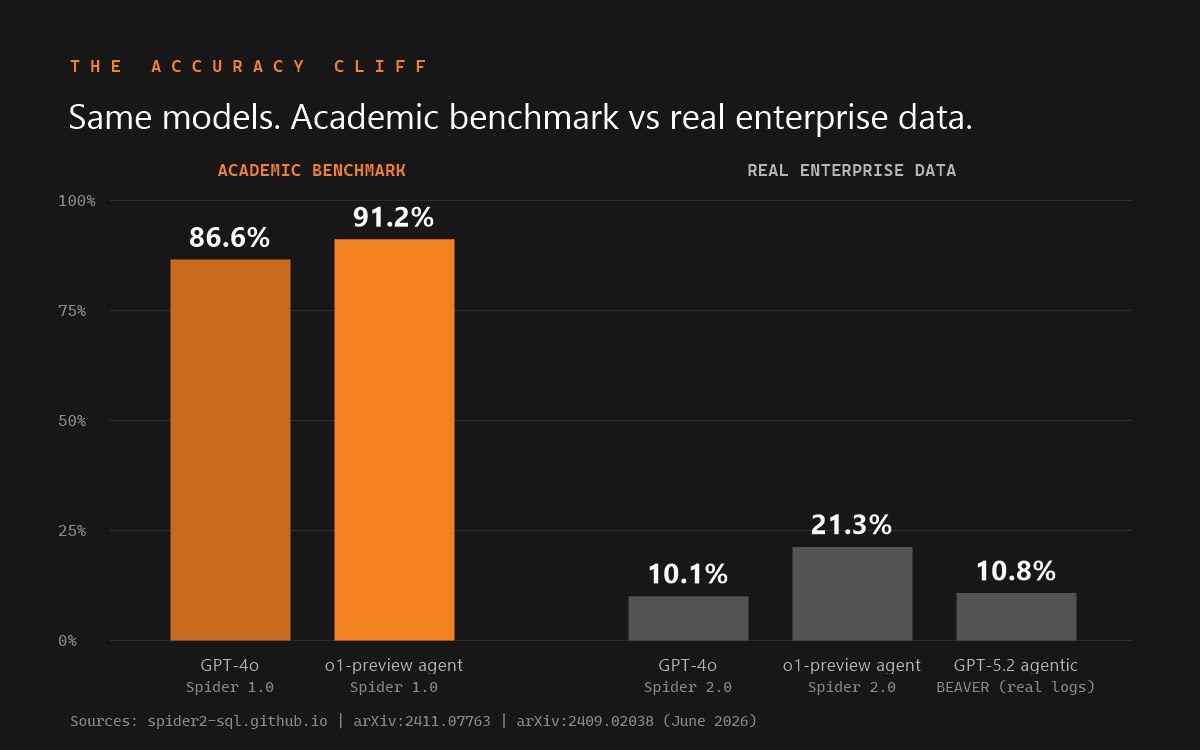
Independent benchmarks are blunt. The Spider 2.0 paper reports an o1-preview code-agent framework solving only 21.3% of tasks, against 91.2% on the older Spider 1.0, across real enterprise databases averaging hundreds of columns. The BEAVER enterprise benchmark found off-the-shelf models including GPT-4o near 0% end-to-end accuracy on real warehouse data. The lesson is not "LLMs are useless." It is that the semantic model doing the grounding is the real bottleneck. See the text-to-SQL accuracy cliff and deterministic vs probabilistic text-to-SQL.
Fix the Context, Not the Model. Every point of accuracy above the raw-LLM baseline comes from better context and constraints, not a bigger model. That is the whole game in enterprise text-to-SQL.
The scorecard
Scored on four production factors: determinism and reproducibility, governance timing, multi-warehouse reach, and maintenance burden. High / Medium / Limited are directional, not lab numbers.
| Tool | Determinism | Governance timing | Multi-warehouse | Maintenance |
|---|---|---|---|---|
| Colrows | High (compile-time) | Before execution | Yes (16+ engines) | Low (autonomous graph) |
| Cortex Analyst | Medium | At execution (Snowflake RBAC) | Snowflake only | Medium (hand-authored model) |
| Databricks Genie | Medium | At execution (Unity Catalog) | Databricks only | Medium (curated Spaces) |
| dbt Semantic Layer | High (defined metrics) | Metric-defined | Yes (needs dbt Cloud) | Medium (code-first) |
| Cube | High (defined metrics) | Query-time | Yes | Medium (hand-authored) |
| ThoughtSpot Spotter | Medium | Platform governance | Multi-cloud | Medium |
| Wren AI | Medium (open-source, MDL context) | Depends on setup | Multiple sources | Medium |
| Vanna AI | Low-Medium (RAG-trained) | Depends on setup | Multiple sources | Higher (train on your schema) |
The tools, by job to be done
1. Colrows - deterministic, multi-warehouse, governed before execution
Colrows compiles intent through a typed semantic graph into deterministic, dialect-perfect SQL across 16+ engines, proves join paths, and enforces governance before any query runs. Best when you need reproducible answers across many warehouses with compile-time governance, especially in regulated settings. See how compile-time refusal prevents hallucination.
2. Snowflake Cortex Analyst - fast, Snowflake-native
Cortex Analyst is a strong warehouse-native option if your estate is Snowflake. Governs at execution via Snowflake RBAC; Snowflake-only.
3. Databricks Genie - Databricks-native, Unity Catalog governance
Genie inherits Unity Catalog governance and is the natural pick inside Databricks, capped at 30 tables per Space.
4. dbt Semantic Layer - code-first metric definitions
The dbt Semantic Layer generates SQL from version-controlled metrics; deterministic where a metric is defined. Requires dbt Cloud.
5. Cube - headless metric API
Cube serves governed metrics over SQL, REST, GraphQL, and MDX. Deterministic within defined metrics; best for embedded analytics.
6. ThoughtSpot Spotter - search-driven self-service
ThoughtSpot Spotter pairs search-token architecture with an agentic semantic layer, multi-cloud and LLM-flexible.
7. Wren AI - open-source semantic context
Wren AI is an open-source text-to-SQL project that grounds generation in a modeling definition layer across multiple sources. A good starting point for teams that want to self-host and own the stack.
8. Vanna AI - RAG-trained SQL generation
Vanna AI is an open-source framework that trains a retrieval model on your schema and past queries to generate SQL. Flexible and developer-friendly, but accuracy and governance depend heavily on how you train and wire it.
How to choose
- Single warehouse, want the fastest path: Cortex Analyst (Snowflake) or Genie (Databricks).
- Standardized metrics across a modern stack: dbt Semantic Layer or Cube.
- Self-host and own the stack: Wren AI or Vanna AI.
- Deterministic, reproducible SQL across many warehouses with governance before execution, especially regulated: evaluate Colrows.
Frequently asked questions
How accurate is text-to-SQL in 2026?
On real enterprise schemas, still hard: about 21.3% on Spider 2.0 for an o1-preview agent, near 0% for off-the-shelf LLMs on BEAVER. A semantic layer is what lifts accuracy toward production-usable.
What makes a text-to-SQL tool production-ready?
Deterministic reproducible SQL, governance before execution, multi-warehouse reach, and a maintainable semantic model, not just a good benchmark on one curated dataset.
What is the most accurate approach?
Deterministic, compile-time resolution against a typed semantic graph that proves the join path and refuses on ambiguity rather than guessing.