Headless BI semantic layer vs semantic execution layer
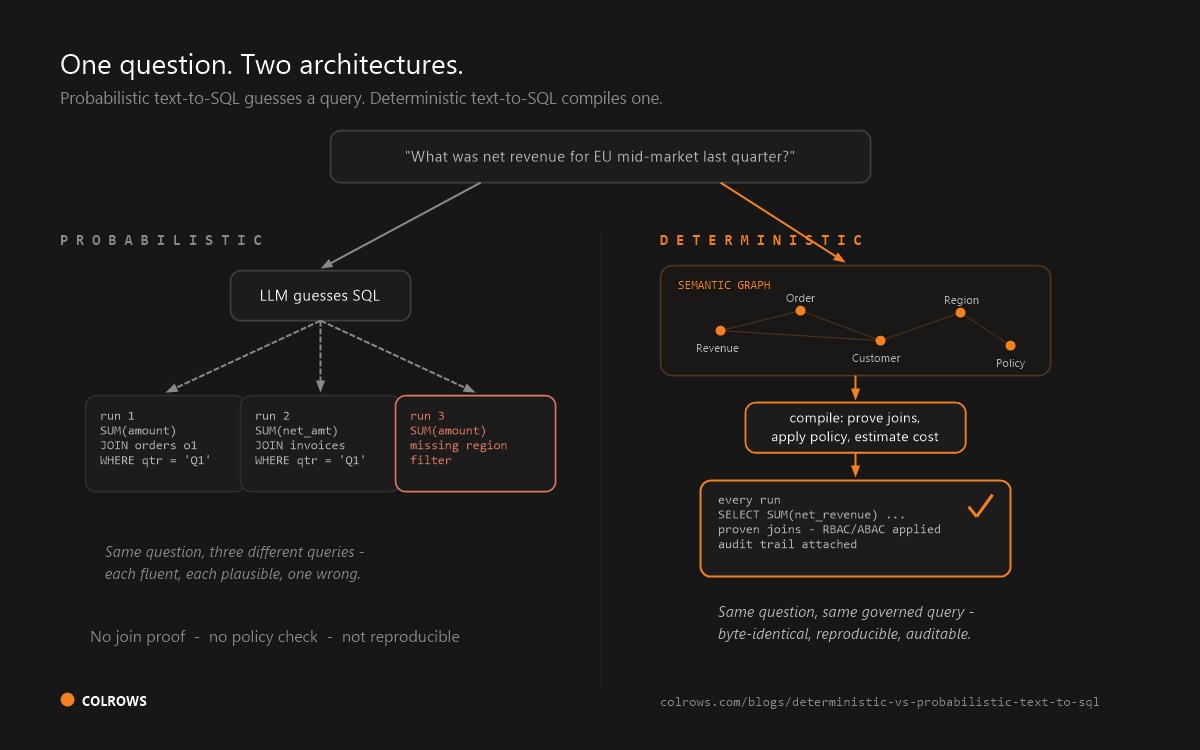
Before the list, the distinction that decides your shortlist. Cube resolves metrics at query time and serves them to consumers. A semantic execution layer resolves meaning, proves the join path, and enforces policy at compile time, before any SQL runs.
| Dimension | Cube (headless BI semantic layer) | Colrows (semantic execution layer) |
|---|---|---|
| Built for | Consistent metrics for dashboards, embedded apps, data tools | Governed, deterministic SQL for AI agents |
| Semantic model | Hand-authored YAML / JavaScript (cubes, views, measures, joins) | Autonomous, continuously maintained typed semantic graph |
| Governance | Query-time, via security context on the API | Compile-time: RBAC + ABAC + row/column predicates before execution |
| Join safety | Only joins you defined; ambiguity resolved by the model author | Join path proof; ambiguous requests fail at compile time |
| Determinism | Deterministic SQL from defined metrics; AI layer sits on top | Deterministic by construction; same question, same scope, same SQL |
What Cube does well
Give Cube its due. It is a mature, widely adopted project with a genuine architectural strength: one metric definition, many consumers.
- Headless and API-first. Cube exposes the same governed metrics over a SQL API, REST, GraphQL, and MDX. One definition powers Superset, Tableau, a custom React app, and a notebook at once.
- Open-source core. Cube Core is Apache 2.0 and self-hostable. You can run it yourself at no license cost, which is rare among semantic layers.
- Embedded analytics. Cube shines when you are shipping analytics inside your own product to thousands of end users and need a fast, cacheable metric API with pre-aggregations.
- Caching and pre-aggregations. Cube's pre-aggregation engine is built for high-volume, low-latency metric serving.
If your job is "serve consistent metrics to many front-ends," Cube is a strong default. The question is what happens when the primary consumer stops being a dashboard and becomes an autonomous agent.
Where Cube gets stretched for AI agents
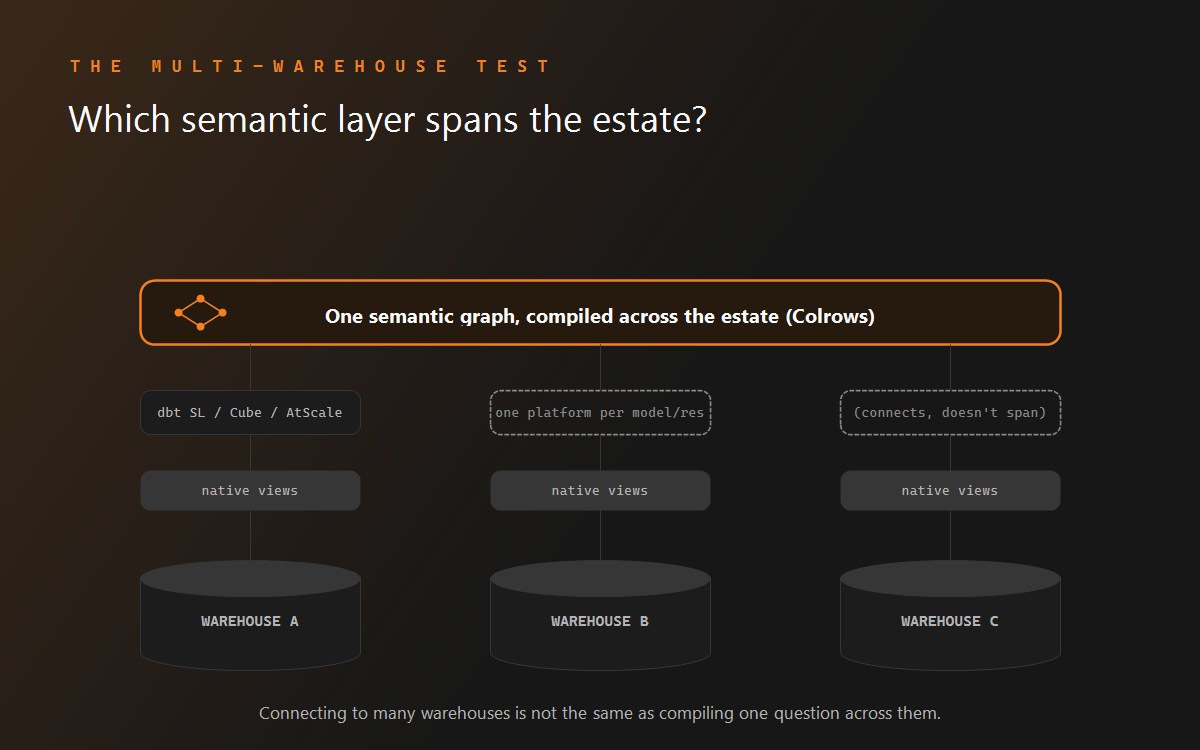
- The model is hand-authored and hand-maintained. Cubes, views, measures, dimensions, joins, and segments are written and versioned by people. On a large, drifting estate, keeping that YAML current is ongoing work, and the model quality is the ceiling on answer quality.
- Governance is applied at query time. Access control runs through the security context on the API surface. That is fine for serving metrics, but it is not compile-time proof that an unauthorized plan could never be generated.
- The AI features sit on top of the metric API. Cube's agent capabilities query the same metric layer a human would. There is no native compile-then-execute step that proves a join path before the SQL is emitted.
- Context is per-query. A headless metric API does not carry persistent, cross-workflow context the way an agent-native graph does.
None of this makes Cube wrong. It makes Cube a metric-serving layer, not an execution layer. That is the fork in the road. For the deeper architectural contrast, see Colrows vs Cube and deterministic vs probabilistic text-to-SQL.
Fix the Context, Not the Model. A bigger LLM will not rescue an agent sitting on a hand-authored metric API. The reliable path is a governed semantic layer that resolves meaning and proves the query before it runs.
The Cube alternatives, by job to be done
1. Colrows - for governed, multi-warehouse AI agents
Colrows is a compile-time semantic execution layer built agent-first. It compiles intent through a typed semantic graph into deterministic, dialect-perfect SQL across 16+ engines, proves join paths, and enforces RBAC, ABAC, and row/column policy before any query touches the warehouse. Where Cube serves metrics, Colrows governs and compiles agent intent. Best fit when the primary consumer is an autonomous agent and you need reproducibility and compile-time governance, not just a consistent metric API.
2. dbt Semantic Layer (MetricFlow) - for code-first, vendor-neutral metrics
The dbt Semantic Layer defines metrics once in version-controlled code and generates SQL for Snowflake, BigQuery, Databricks, and Redshift. It is the natural pick for teams already living in dbt who want standardized definitions. The catch is that the Semantic Layer requires dbt Cloud, a noted lock-in, and it targets metric consistency rather than agent execution. See the dbt Semantic Layer pricing teardown.
3. AtScale - for OLAP aggregate-awareness and BI-tool integration
AtScale is a universal semantic layer built around multidimensional models and aggregate awareness, with strong MDX/DAX integration into Excel, Power BI, and Tableau. If your consumers are BI tools that need live, fast aggregates over massive data, AtScale is purpose-built. It is heavier to model and, like Cube, human-first. See AtScale alternatives.
4. Looker (LookML) - for BI-native governed modeling
Looker's LookML is a mature modeling layer with governed metrics and embedded analytics inside the Google Cloud ecosystem. Choose it when your organization is standardizing on Looker for human BI. It is a BI platform first, not a headless API or an agent execution layer. See Looker alternatives.
5. Snowflake Cortex Analyst - for Snowflake-only self-serve
Cortex Analyst is a fast, warehouse-native text-to-SQL service. It is the lowest-friction path if your estate is entirely Snowflake, but it is Snowflake-only and governs after SQL is generated, not before.
6. Databricks Genie - for Databricks-only conversational BI
Databricks Genie inherits Unity Catalog governance and is a strong pick for Databricks-native teams, capped at 30 tables per Genie Space and bounded to Databricks. See Databricks Genie alternatives.
Cost snapshot (2026, USD)
Point-in-time figures. Verify against each vendor's pricing page before you commit.
| Platform | Entry | Model |
|---|---|---|
| Cube Cloud | Free dev tier; Starter $40/developer/mo; Premium $80/developer/mo | Per-seat + consumption (Cube Compute Units: ~$0.10/CCU Starter, ~$0.25/CCU Premium with $10K/yr commit) |
| dbt Cloud / Semantic Layer | Developer free; Starter $100/user/mo | Seats + usage; ~$0.075/queried metric; SL requires dbt Cloud |
| AtScale | Custom (no public list price) | Annual enterprise contract |
| Colrows | Free ($0) | Free + custom Enterprise (priced on Semantic Assets, not seats or queries) |
Which alternative fits you
- You ship embedded analytics to many front-ends: Cube is hard to beat. Stay unless AI agents become your main consumer.
- You are dbt-native and want standardized metrics: dbt Semantic Layer.
- Your consumers are Excel, Power BI, Tableau over huge aggregates: AtScale.
- Your primary consumer is an AI agent and you need deterministic, multi-warehouse SQL with governance before execution: evaluate Colrows. This is the gap a headless metric API structurally does not fill.
Frequently asked questions
Is Cube open source?
Yes. Cube Core is Apache 2.0 and self-hostable. Cube Cloud is the managed commercial product, priced per developer seat plus consumption in Cube Compute Units.
How much does Cube Cloud cost?
Starter is $40 per developer per month and Premium is $80 per developer per month, plus consumption billed in Cube Compute Units (roughly $0.10/CCU on Starter with a $99/month minimum; $0.25/CCU on Premium with a $10K/year commit). Enterprise is custom.
Is Cube built for AI agents?
Cube is a headless BI semantic layer that serves metrics over SQL, REST, GraphQL, and MDX. Its AI features sit on top of that metric API. It is not a compile-time execution layer that proves join paths and enforces governance before a query runs.