Cortex Analyst is fast and accurate inside Snowflake, but bounded by design
Cortex Analyst is a fully managed, LLM-powered REST service that converts natural-language questions into SQL grounded in a semantic model (YAML) or, on the now-recommended path, a semantic view. By default it runs on Snowflake-hosted models; per Mistral's own customer page, Cortex Analyst integrates "two LLMs - Mistral Large and Codestral - selected for their excellent natural language understanding and SQL generation ability," alongside Meta's Llama, and selects the best combination per query.
On accuracy, Snowflake's engineering blog "Behind the Scenes" states Cortex Analyst is "close to 2x more accurate than single-shot SQL generation using a state of the art LLM, like GPT-4o, and delivers roughly 14% higher accuracy than another text-to-SQL solution in the market." Snowflake's evaluation blog adds that on its internal set, single-shot GPT-4o "plummeted to 51%," while Cortex Analyst reached "90%+ SQL accuracy." These are internal benchmarks of 150 questions, not independently verified results.
Concrete limits documented by Snowflake and corroborated by practitioners
- Stateless. Large language models used by Cortex Analyst "do not store state between requests"; the full history is reprocessed each turn, and it cannot reference results from prior queries.
- SQL-only. It answers only questions resolvable with SQL, not open-ended analysis such as "what trends do you observe?"
- Semantic model size cap. A 1 MB / ~32K-token ceiling applies after sample values and verified queries are removed; community and partner guidance recommends roughly 50-100 columns total across all tables. (One Snowflake quickstart page cites a 2 MB limit while the main documentation and multiple partner write-ups cite 1 MB - flag this conflict.)
- No join inference. It uses only the relationships you define; if a relationship is missing from the model, it will not infer it.
- Latency. A default 60-second timeout applies; one production case documented text-to-SQL generation taking 60+ seconds on complex semantic models before tuning.
The real gaps for enterprise buyers
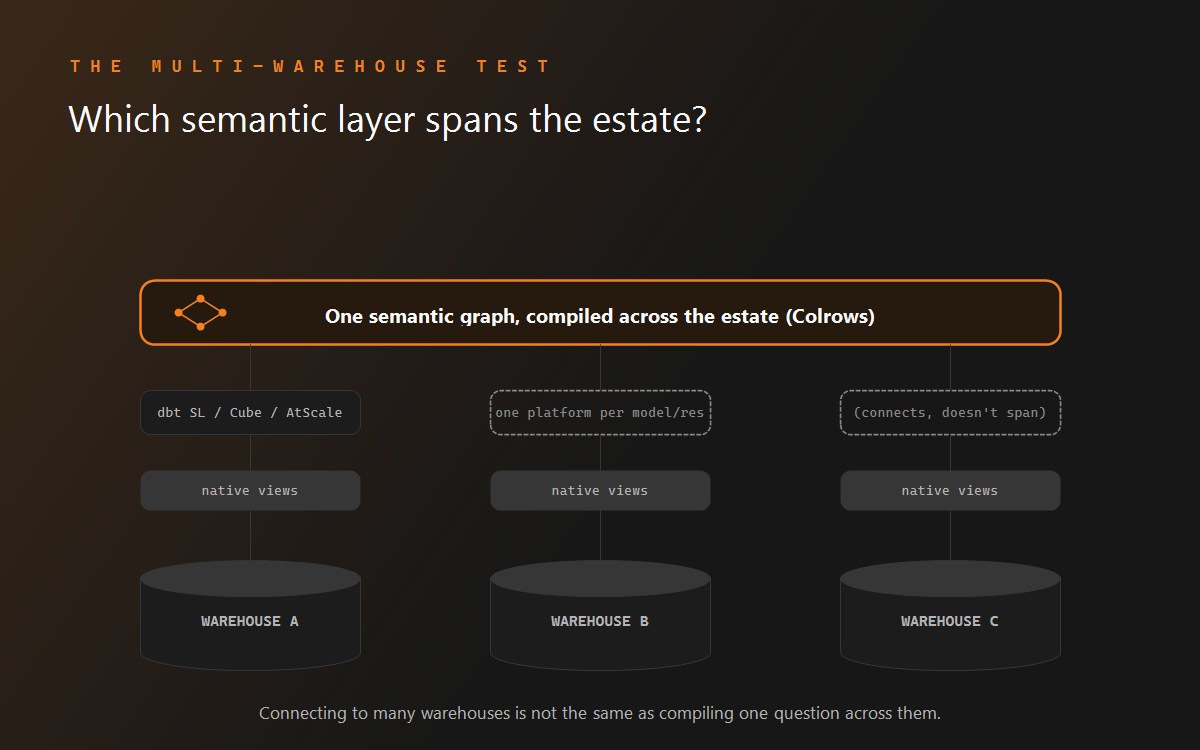
- Snowflake lock-in / single-warehouse constraint. Cortex Analyst works only against Snowflake data. Semantic views are warehouse-bounded: they see only Snowflake data, not BigQuery, Databricks, dbt models, Looker metrics, or Salesforce objects. Cross-warehouse questions require ingesting other data into Snowflake first. The semantic-model artifact itself is Snowflake-specific and must be rebuilt if you leave.
- Governance enforced after generation, not before. Cortex Analyst inherits Snowflake RBAC, masking, and row access policies - a real and meaningful strength - but enforcement happens when the generated SQL executes against physical tables, not at the moment intent is compiled. A May 2025 disclosure by security firm Cyera ("Unexpected behavior in Snowflake's Cortex AI") showed that "because CORTEX Search uses owners' rights, it effectively 'borrows' all privileges of the role under which it's running, potentially allowing a lower-privileged user read access over indexed data." Snowflake acknowledged the issue and updated its documentation. The lesson for buyers: "governance is inherited" is true but configuration-dependent.
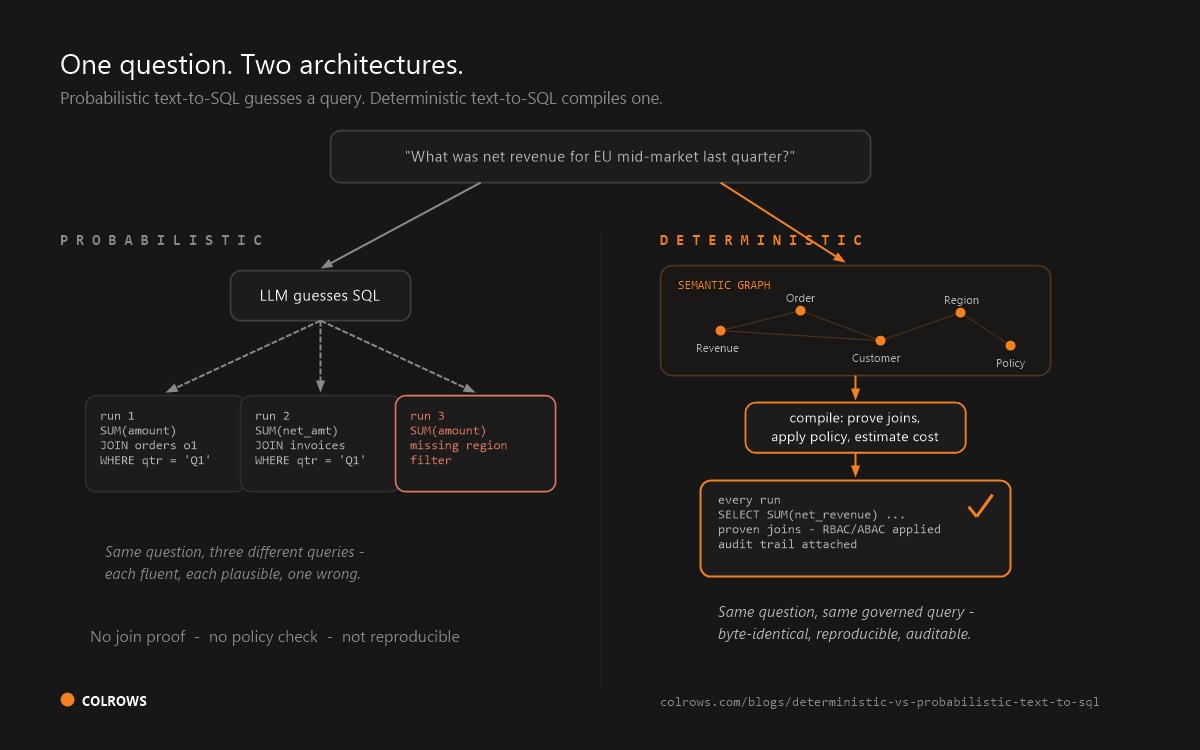
- Non-determinism. LLM generation means the same question can yield different SQL across runs, and there is no native compile-time proof that a chosen join path is valid.
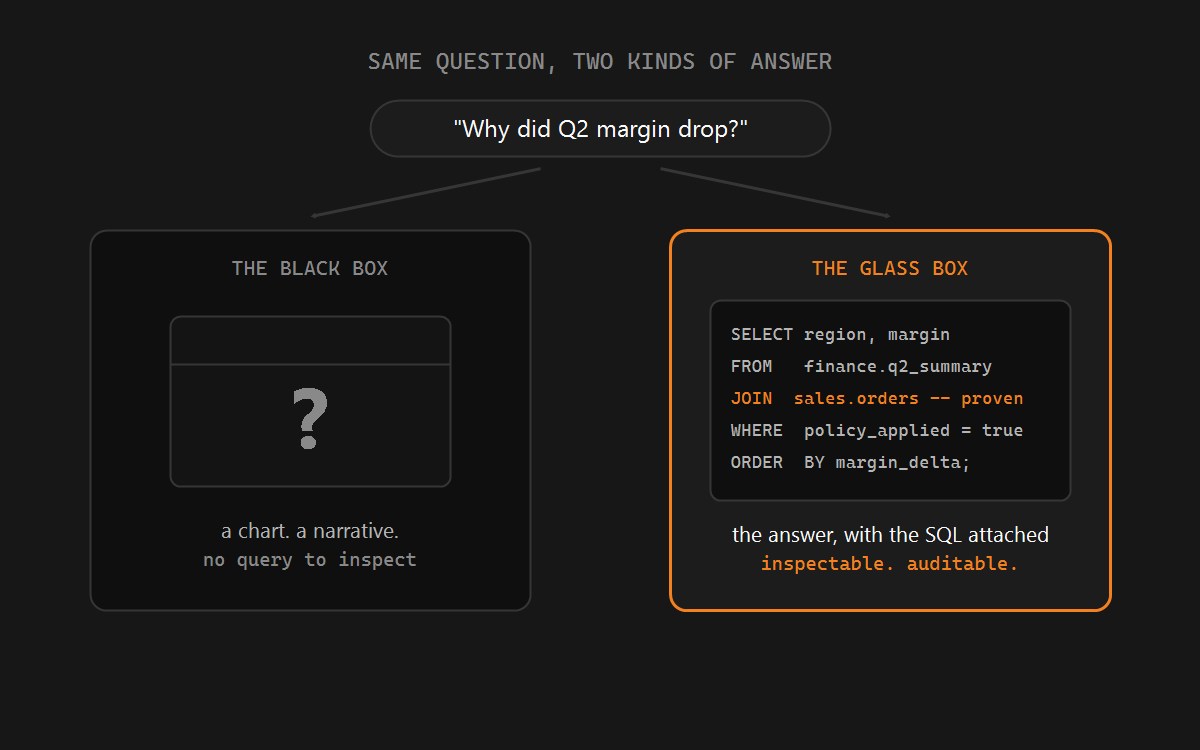
- Reproducibility / audit. Generated SQL is logged in Query History, but conversation history is not logged natively, and there is no built-in way to distinguish agent-generated queries from manually written ones. Native point-in-time traceability of "which definition produced this number" is limited.
- Cost model. The standalone Cortex Analyst API costs 67 Snowflake credits per 1,000 messages (~$201 at $3/credit; ~$348 at $5.20/credit on Business Critical in Azure West Europe). You also pay separate virtual-warehouse compute to execute every generated query.
- Maintenance burden. Semantic models are hand-authored, hand-maintained YAML. Reverse-engineering relationships, metrics, and business terms can take weeks or months for large estates.
Enterprise text-to-SQL is hard - independent benchmarks prove it
Academic benchmarks confirm that natural-language-to-SQL on real enterprise schemas is far from solved. The Spider 2.0 paper (Lei et al., arXiv 2411.07763, ICLR 2025) reports that "based on o1-preview, our code agent framework successfully solves only 21.3% of the tasks, compared with 91.2% on Spider 1.0 and 73.0% on BIRD," across 632 real-world enterprise workflow problems with very large schemas (averaging roughly 800 columns per database). The BEAVER enterprise benchmark found that off-the-shelf LLMs including GPT-4o and Llama3-70B-Instruct "achieved close to 0 end-to-end execution accuracy" on real data-warehouse data.
This is the honest context for Snowflake's 90%+ figure: it is achieved with a curated semantic model on an internal evaluation set. The takeaway: the semantic model is doing the heavy lifting, and the quality of that hand-authored artifact is the real bottleneck. More on deterministic vs probabilistic text-to-SQL.
Competitive landscape: split by job-to-be-done
- Sigma Computing - warehouse-native spreadsheet BI with the "Ask Sigma" natural-language agent. Connects live to Snowflake, Databricks, BigQuery, and PostgreSQL, pushes queries down to the warehouse, and its AI "respects existing warehouse roles, permissions, and row-level security." Best for business users who want governed, spreadsheet-style exploration.
- Databricks Genie - Databricks-native NL-to-SQL that inherits Unity Catalog governance automatically. The table limit per Genie Space is 30; works only against Databricks. DBU cost is harder to pre-budget than Cortex credits.
- dbt Semantic Layer (MetricFlow) - code-first, version-controlled, vendor-neutral metric definitions that generate optimized SQL for Snowflake, BigQuery, Databricks, and Redshift. Requires dbt Cloud (a noted lock-in). Best for dbt-native teams standardizing metrics.
- Cube - open-source headless semantic layer exposing SQL, REST, GraphQL, and MDX APIs to many consumers at once. Best for embedded analytics and high-volume metric APIs where you own the serving infrastructure.
- ThoughtSpot Spotter - search-token architecture plus an agentic semantic layer; multi-cloud and LLM-flexible. As of June 2026 it integrates directly with Cortex Analyst and Cortex Agents via MCP and Snowflake Semantic Views. Best for search-driven self-service BI across thousands of users.
- Colrows - a compile-time semantic execution layer purpose-built for AI agents, emitting deterministic, dialect-perfect SQL across many warehouses with governance enforced before execution.
Colrows vs Cortex Analyst - verified head-to-head
Verified directly from Colrows' documentation:
- Multi-dialect. Colrows consistently claims "16+ engines" - Snowflake, Databricks, Redshift, BigQuery, Postgres, MySQL, ClickHouse, Trino, Oracle, SQL Server and more. Cortex Analyst is Snowflake-only. This is the single clearest architectural contrast.
- Determinism and compile-time governance. Colrows describes a "compile-then-execute" pipeline in which "parsing produces an AST, never SQL," the semantic control plane resolves that AST against a typed graph, join paths are "proven" via constrained graph traversal, and "row-level security, RBAC, ABAC, and column-level predicates are evaluated at compile time, before any SQL touches your warehouse." Its docs state that an ambiguous request "fails at compile time, with an explainable error - not at the warehouse, after a 4-minute scan," and that "filtered-out rows are never read - governance is structural, not advisory."
- Join path proof. "When a metric references entities across multiple datasets, Colrows must prove - not guess - that a deterministic join path exists," using pruning on grain, cardinality, and cycles; "ambiguity causes compilation to fail."
- Autonomous maintenance. Colrows describes background discovery, architecture, learning, and monitoring agents that "rebuild the graph automatically as each source changes - no human ticket required."
- Audit / reproducibility. Every result carries an audit trail, and "the next agent asking the same question in the same scope gets the same answer, because the compiler is deterministic."
Honest framing of Colrows. It is an early-stage company (founded 2024, Pune-based, operated by Alterbasics Technologies). Its homepage lists "engineering teams at Pfizer, Cipla, BTS Group, Flobiz, and Brexa." The correct positioning is "best fit for deterministic, multi-warehouse, regulated agent governance," never "the best."
Cost comparison (entry / mid / enterprise, USD)
| Platform | Entry | Mid-scale | Enterprise | Model notes |
|---|---|---|---|---|
| Cortex Analyst | Bundled with Snowflake Enterprise at $3/credit | ~$201 per 1,000 messages + warehouse compute | Heavy workloads $10K-$30K+/mo; ~$348 per 1,000 messages at $5.20/credit | Per-message (standalone API) or token-based (via Agents); always plus compute |
| dbt Cloud / Semantic Layer | Developer free | Starter $100/user/mo | Custom; Reddit reports $40K-$95K/yr for 10-20 devs; ~$0.075/queried metric | Seats + usage; SL requires dbt Cloud |
| Cube Cloud | Free dev tier | Starter ~$40/user/mo; Premium ~$80/user/mo | $8K-$15K+/mo high-volume; Enterprise commit | Consumption (Cube Consumption Units) |
| ThoughtSpot | Essentials $25/user/mo | Pro $50/user/mo | Custom; Vendr median ~$137K/yr; mid-market $100K-$350K/yr | Per-user + consumption |
| Sigma | Per-user (contact sales) | Per-user | Custom | Warehouse-native; no separate AI system |
| Colrows | Free ($0, 5 compute tokens) | "Schema complexity plus query volume" | Custom Enterprise (SSO/SCIM, dedicated/private, SOC 2/HIPAA) | Free + custom only |
Governance enforcement timing - the core technical distinction
Cortex Analyst, Genie, and Sigma all enforce governance at execution against the warehouse - RBAC, masking, and row-level security are inherited and applied when the query runs. Colrows enforces structurally at compile time by shaping an allowed subgraph per persona, so "unauthorized plans cannot be generated" and filtered-out rows are never read. For regulated buyers in financial services and healthcare who must demonstrate that sensitive data was never accessed (not merely masked in output), this difference is material. These are "controls that can assist in meeting requirements," not guarantees that anything "ensures compliance."
Staged buyer guidance
- Snowflake-only, want fast self-serve BI: start with Cortex Analyst; it is the lowest-friction path and the brand-trusted default.
- Estate spans two or more warehouses: evaluate a vendor-neutral layer (dbt Semantic Layer or Cube) or a compile-time execution layer (Colrows). Threshold to switch: when cross-warehouse questions or definition drift across systems become recurring rather than occasional.
- Regulated (finance / healthcare) needing proof of non-access (not just masking) and reproducibility: prioritize compile-time governance and deterministic compilation; this is where Colrows' "filtered-out rows are never read" model is most differentiated.
- Search-driven BI for thousands of business users: evaluate ThoughtSpot Spotter, especially if you also run Snowflake (it integrates with Cortex via MCP).
Benchmarks that should change the recommendation: if Snowflake ships native multi-warehouse semantic views, native conversation/audit logging, and compile-time policy enforcement, the lock-in and reproducibility arguments weaken materially - re-evaluate at that point.
Frequently asked questions
Is Cortex Analyst Snowflake-only?
Yes. Semantic views see only Snowflake data, not other warehouses or external systems.
How much does Cortex Analyst cost?
67 Snowflake credits per 1,000 messages (~$201 at $3/credit, up to ~$348 at $5.20/credit), plus virtual-warehouse compute for every executed query.
What's the semantic model size limit?
A ~1 MB / 32K-token cap applies. Community guidance recommends ~50-100 columns total. (Snowflake's quickstart cites 2 MB; primary docs cite 1 MB - a documentation conflict to flag.)
Is the 90%+ accuracy independently verified?
No. It is achieved with a curated semantic model on Snowflake's internal 150-question evaluation set. Independent benchmarks - Spider 2.0 (~21.3% for o1-preview), BEAVER (near 0% for off-the-shelf LLMs) - show enterprise text-to-SQL remains hard.
Where is generated SQL logged?
In Query History, but conversation history is not logged natively. There is no built-in way to distinguish agent-generated queries from manually written ones without query tags or warehouse/role isolation.
Caveats
Snowflake's 90%+ accuracy is an internal 150-question benchmark, not independently verified. A genuine documentation conflict exists on the semantic-model size cap (1 MB is most widely cited; one Snowflake quickstart page states 2 MB). Colrows is early-stage; its customer metrics are self-reported and partly illustrative, and the assumed four-tier pricing ($18K/$60K/$120K/$180K) does not exist publicly - only a Free tier and a custom Enterprise tier do. All pricing figures are point-in-time (2026) and vary by edition, region, and negotiation; verify against vendor pricing pages before publishing.