TL;DR
- Tom Blomfield's YC Summer 2026 RFS formally launched the "Company Brain" category. Hyper leads on early traction ($1K MRR in 12 days). GBrain's open-source baseline has 23.6K GitHub stars. But all current solutions focus on unstructured retrieval.
- Most current solutions fail for regulated operations. A true enterprise brain must query structured data warehouses deterministically. When an AI agent and a CFO calculate "revenue" differently, silent wrong answers go to board decks.
- The competitive landscape will bifurcate. Consumer Company Brains (Hyper, GBrain) will be free or nearly free. Enterprise Semantic Layers (Colrows) will be premium. Both are real. Both will win in their lane.
The Category That YC CEO Endorsed (And Why It Matters)
In April 2026, Y Combinator published its Summer 2026 Request for Startups. Among 15 priority categories, one stood out as officially ordained: "Company Brain."
Tom Blomfield, a YC General Partner and the co-founder of Monzo and GoCardless, wrote the entry. His framing was direct:
"If we want every company to run on AI automation, we need a new primitive: a company brain. A system that pulls knowledge out of all these fragmented sources, structures it, keeps it current, and turns it into an executable skills file for AI. This isn't a company-wide search or a chatbot over documents. It's a living map of how a company works: how refunds get handled, how pricing exceptions are decided, how engineers respond to incidents. I think every company in the world is going to need one."
Within weeks, the category exploded. Startups rebranded around the term. LinkedIn filled with founders claiming they'd been building "the company brain" all along. Garry Tan, YC's CEO, open-sourced his personal agent memory system under the same banner. The narrative became inescapable: AI models are finally smart enough. The bottleneck is now context.
But here's what nobody says out loud: most of these teams are solving the wrong problem.
Understanding the Current Landscape
The Core Thesis (That Everyone Gets Right)
All entrants agree: in 2026, throwing raw data at LLMs doesn't work. An AI agent needs structured knowledge about how a company actually operates.
Slack threads bury critical decisions. Email chains scatter context. Notion wikis go stale. Meeting notes live in personal apps. Nobody has a single source of truth for how to handle an exception, approve a refund, or calculate a customer's lifetime value.
A "Company Brain" is supposed to solve this. Pull knowledge from everywhere. Structure it. Keep it fresh. Feed it to agents.
Where the Current Solutions Succeed
Hyper (YC Spring 2026) leads the pack on execution and traction.
Founders Shalin Shah and Kanyes Thaker built some of the most sophisticated autonomous systems in the industry. Thaker was a Snorkel AI founding engineer. Hyper's pitch: "The self-driving company brain." It ingests Docs, Slack, Email, Calendar, GitHub, Granola. It builds a self-maintaining knowledge graph. It injects context into Claude Code, Cursor, ChatGPT via MCP on every prompt turn.
Traction in 12 days post-launch: $1K MRR, 50+ teams onboarded, paid design pilots scoped with Razorpay and Snorkel AI.
The architecture is sophisticated. Facts carry provenance, staleness tracking, and per-user access control. Retrieval uses query expansion, reciprocal rank fusion over embeddings and Postgres full-text search, plus a ZeroEntropy reranker.
GBrain (Garry Tan, open-source) sets the free baseline and proves the market can move fast.
Tan open-sourced GBrain on April 5, 2026 under MIT license. It's his production memory system for running dozens of autonomous agents. Within 24 hours: 5,000 GitHub stars. Within two months: 23,600 stars and 3,400 forks.
What makes GBrain compelling: it extracts a typed knowledge graph with zero LLM calls per write. It uses regex and string matching to identify relationships (attended, works_at, invested_in, founded). It runs on PGLite locally or Postgres in the cloud. Hybrid search combines vectors, BM25, reciprocal rank fusion, and a reranker. A nightly "dream cycle" consolidates and fixes citations. Cost: under $100/month for a 25-person company brain.
Other credible entrants:
- Cerenovus (YC S26): Three Harvard sophomores building a markdown knowledge graph that maps the company as a system and infers operational inefficiencies. Pilot customers live.
- Savant (YC Spring 2026): Building an operational memory layer that captures undocumented procedures and turns them into agent skills.
- Memory Store (YC P26): Building "One memory for your team's agents" that synthesizes Slack, Gmail, Granola into a company brain.
All of these teams are shipping real products. Early traction is real. But they are all solving for the same customer: tech-forward teams with 1-20 people, no regulatory constraints, and time to experiment.
The Missing Piece: Why Context Retrieval Isn't Enough
The current YC batch views the "Company Brain" as a graph of Slack messages, emails, and markdown wikis. This works for engineering assistants or basic text retrieval. It fails for core operations.
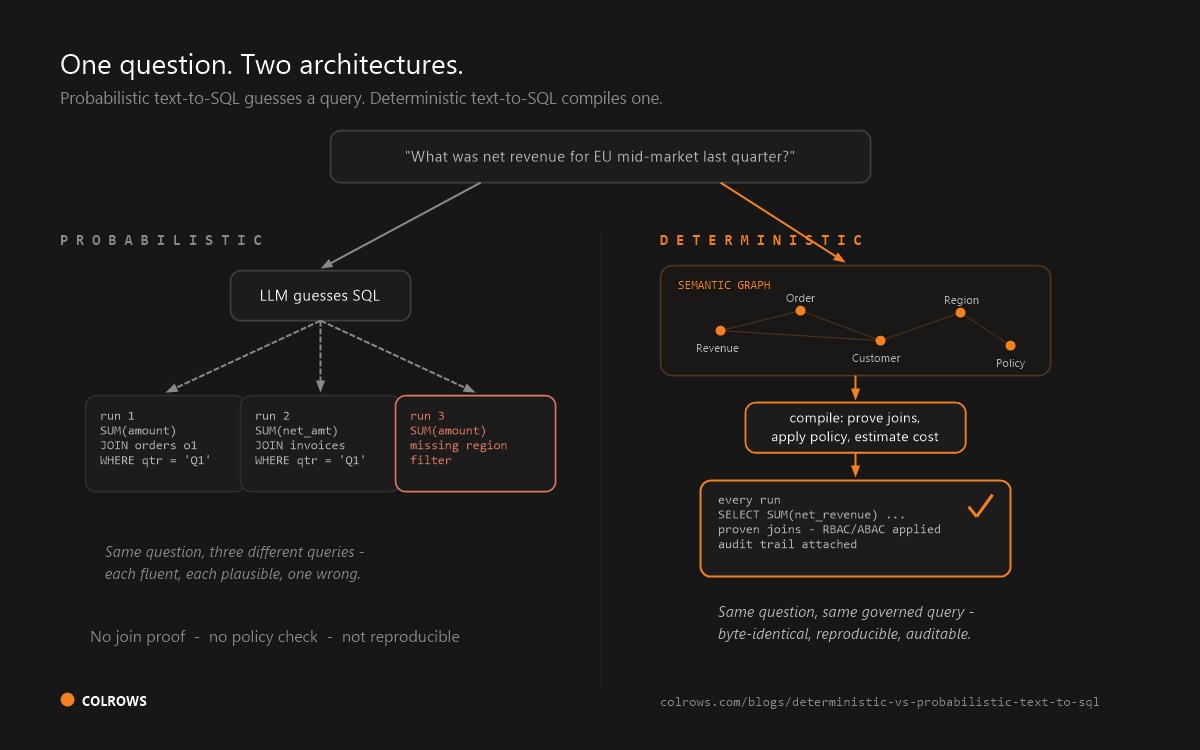
True enterprise automation requires access to the data warehouse. But here is what happens when you pass raw schemas to an LLM:
An AI agent is asked, "How many active customers do we have?" The agent sees 50+ table names and 200+ columns. It infers: "Active customer = someone who logged in in the last 30 days." It joins tables A, B, and C, executes the query, returns a number.
Your CFO sees the same question and answers differently: "Active customer = someone with a non-zero subscription balance in the last 30 days." Different join path. Different answer.
One goes in a board deck. The other goes in an investor call. Nobody catches the discrepancy until the numbers don't reconcile.
See our deep dive: How to Prevent AI Hallucinations on Enterprise Data
Every agent query that hits a raw schema forces the LLM to re-process the entire database schema. A 500-table warehouse is 15,000 tokens per query. If you run 100 queries per day, that's 1.5 billion tokens per month just on schema overhead.
At $0.01 per 1M input tokens, that's $15,000/month in schema cost alone.
Related: Semantic Layer vs Text-to-SQL: Cost and Accuracy Trade-offs
When something goes wrong, you cannot trace it. An agent approves a $1M refund based on a misinterpreted rule. Your compliance officer asks: "Show me the join path. Show me the business definition used. Show me the audit trail."
Nothing. The model hallucinated it. For regulated industries (BFSI, pharma, healthcare), this is a non-starter. Your regulator will not accept "the model decided" as an audit trail.
The Deterministic Alternative: Fix the Context, Not the Model
Instead of a chaotic context layer patched on top of unstructured data, enterprise teams need a different architecture.
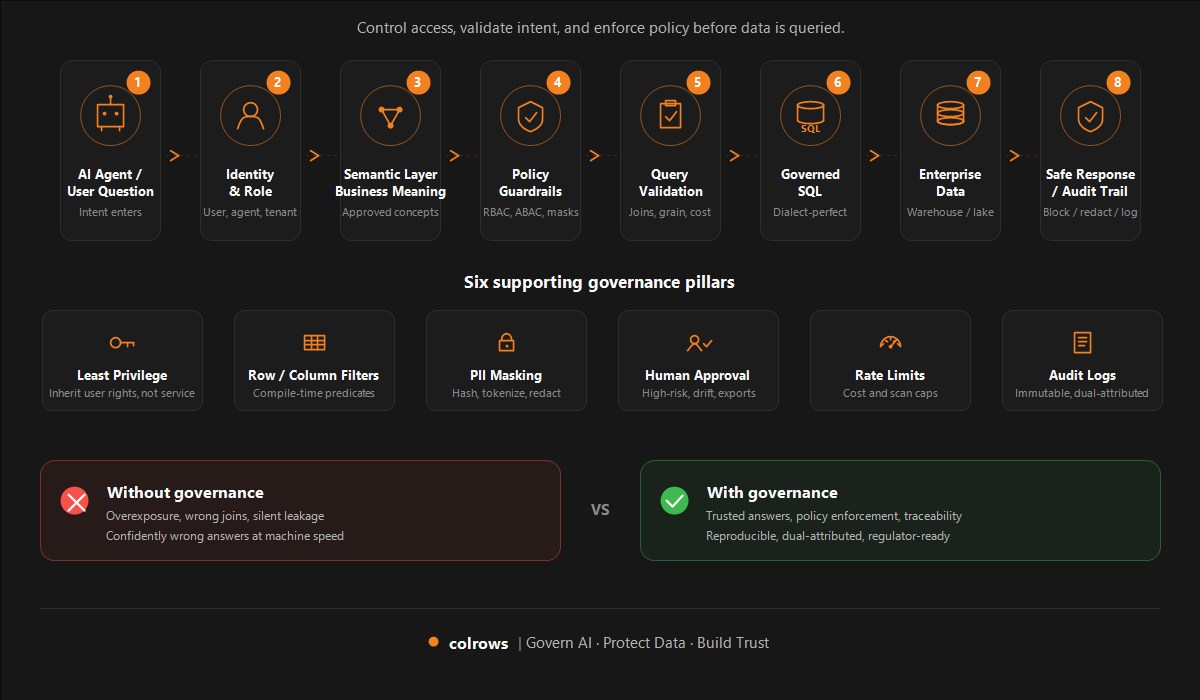
Build a deterministic semantic layer. Compile natural language business definitions into governed, auditable SQL. Then wire agents to that layer.
Here is how it works:
A data team works with a business stakeholder (CFO, Head of Risk, Chief Compliance Officer) and defines a metric once: "Active Customer = someone with a non-zero subscription balance as of the query date."
That definition is compiled into SQL. The join path is documented. The metric is versioned. Access control is enforced at the semantic layer level.
Now, any agent that asks "How many active customers?" gets the exact same answer. Every time. Guaranteed.
The benefits compound:
- No metric hallucination. Agents use deterministic SQL, not inferred joins.
- Predictable cost. Compilation happens once. Queries execute fast. No schema bloat per query.
- Full auditability. Every answer has lineage. You can prove what definition was used, when, by whom.
- Compliance-ready. You can show a regulator an exact SQL query and a versioned metric definition.
For more on this architecture: From Copilots to Autonomous Companies: AI-Native Operations
Colrows vs. the Company Brain Category: A Strategic Separation
Here is where we need to be direct: Colrows is not a "Company Brain" startup, and it should not be positioned as one.
Colrows is what the Company Brain category needs but doesn't know it wants yet.
Hyper, GBrain, Cerenovus, and Memory Store are solving the retrieval problem. Colrows solves the determinism problem.
Hyper + Colrows = The complete Company Brain.
Hyper provides the ambient memory and context enrichment. Colrows provides the governance layer underneath the data warehouse. Together, they cover the full stack.
Think of it this way:
Agent → Hyper (fetch context from Slack, docs, email)
→ Colrows (resolve metrics deterministically)
→ Data Warehouse (execute governed SQL)
→ Audit Log (record lineage and access)
Hyper is horizontal (works with any agent, any tool). Colrows is vertical (sits between the semantic layer and the warehouse).
The market opportunity is massive. Enterprise teams will adopt both. Hyper for context. Colrows for consistency.
What This Means for Your Company AI Strategy
If you are evaluating Company Brain solutions, ask yourself three questions:
1. Are you regulated? (BFSI, pharma, healthcare, public sector)
If yes, the pure-play Company Brain startups are not yet ready for you. You need determinism and auditability. That requires a semantic layer. If no, Hyper or GBrain could work. They are cheaper and faster. Just know the ceiling: they will break at scale without a governance layer underneath.
2. Are your data definitions already governed?
If yes, you are in the top 5% of enterprises. You can layer a Company Brain on top of solid data foundations. If no, you need to fix your data layer first. That is 80% of the work.
3. Do you have time to experiment?
If yes, start with GBrain (free). Build your own company brain as a Git repo. See what sticks. If no, jump straight to a complete solution. That is Hyper plus Colrows.
The Verdict: Winners and Losers by 2027
Who Wins
- Hyper will likely be acquired by Anthropic, OpenAI, or a notebook-native AI platform (Cursor, Windsurf). They are building the connector layer that every agent needs.
- GBrain will become the default free DIY pattern. Founders will fork it, adapt it, and run it on their own infrastructure.
- Semantic Layer vendors (Colrows, dbt Labs, Snowflake) will consolidate the governance space. As enterprises move beyond pilots, they will need determinism.
Who Loses
- Cerenovus, Savant, Memory Store will struggle to differentiate from GBrain. They will either get acquired for their team or die.
- Pure-play "Company Brain as a SaaS" will not work for enterprises. Enterprises will want to own their Company Brain. They will use open-source or build it themselves.
The Bottom Line: Fix the Context. Not the Model.
The YC RFS correctly identified the problem: AI models are smart enough. Context is the bottleneck.
But the current solutions are solving 40% of the problem. They are solving for ambient memory and context enrichment.
The other 60% is determinism and governance. That is where the real value lives. That is where regulated enterprises will spend money.
If you are building in this space, you have two options:
- Build retrieval and sell to tech teams. Compete with Hyper and GBrain. Hope for an acquisition.
- Build governance and sell to enterprises. Build a semantic layer. Own the data definition layer. That is where the defensibility and pricing power live.
The category will bifurcate. Consumer company brains (Hyper, GBrain) will be free or nearly free. Enterprise semantic layers (Colrows) will be premium.
For Colrows Prospects: The Path Forward
You do not need a Company Brain. You need a data foundation strong enough to support autonomous AI.
That foundation is a semantic layer.
If you are already running Hyper or GBrain, great. Now layer a semantic layer underneath. Colrows compiles business definitions into governed SQL. No hallucinations. No ambiguity.
If you are building enterprise AI but hitting accuracy walls, the diagnosis is almost always the same: your semantic layer is weak.
Fix the context. Not the model.
Want to audit your semantic foundation? Let's talk. We can spot the gaps in 90 minutes.
For deeper technical context, see our posts on preventing AI hallucinations on enterprise data, deterministic vs probabilistic text-to-SQL, and how to govern AI agents that query enterprise data.
Frequently asked questions
What is a Company Brain, and why does YC care?
A Company Brain is a system that pulls knowledge from fragmented sources (Slack, email, docs, wikis), structures it, keeps it current, and turns it into an executable skills file for AI agents and autonomous systems. YC endorsed it in April 2026 as a top infrastructure priority because models are smart enough—the bottleneck is now context.
How is Hyper different from GBrain?
Hyper is a SaaS company brain layer with managed integrations, $1K MRR in 12 days, and enterprise traction. GBrain is Garry Tan's open-source memory system with 23.6K GitHub stars. Hyper aims to sell polish and integrations; GBrain sets the free baseline that any startup must undercut.
What's the biggest problem with current Company Brain startups?
They solve for context retrieval—pulling Slack, emails, docs into a knowledge graph and feeding it to agents. They do not solve for metric consistency or auditability. When an AI agent queries the warehouse, it halluccinates join paths and metric definitions. Your CFO calculates the same metric differently. Silent wrong answers go to board decks.
Why do AI agents hallucinate metrics?
Because they see a raw database schema (50+ tables, 200+ columns) and infer what data means. 'Active customer' to the agent might mean logged-in-last-30-days; to the CFO it means non-zero subscription balance. Without deterministic, versioned business definitions, the same question returns different answers at machine speed.
What is a semantic layer, and how does it fit into a Company Brain?
A semantic layer sits above the warehouse and compiles business definitions into governed SQL. It is the missing piece. A Company Brain needs retrieval (Hyper/GBrain) plus semantic governance (Colrows). The Company Brain retrieves context; the semantic layer ensures the context is calculated correctly.
Should I build my own Company Brain or buy one?
If you are a 1-20 person tech team with no compliance constraints, GBrain (open-source, free) is a good starting point. If you are an enterprise running autonomous AI and need auditability, you need both Hyper-class retrieval plus Colrows-class semantic governance. Pure-play SaaS Company Brain (standalone) has a difficult path to enterprise adoption.
Is Colrows a Company Brain product?
No. Colrows is the semantic execution layer that Company Brain startups need underneath their retrieval layer. Think of it as: Hyper retrieves context, Colrows governs it. Colrows compiles business definitions into deterministic SQL and enforces audit trails. It's infrastructure for the layer below the warehouse.
When will the Company Brain category consolidate?
By mid-2027. Most current YC startups will either be acquired (likely by larger AI platforms like Anthropic, OpenAI, or Cursor) or will focus on specific niches. GBrain will remain the free DIY baseline. Enterprise adoption will require layered solutions that pair context retrieval with deterministic governance.