AI agents execute logic faster than manual monitors can track. If you rely on database-level runtime security, you are already too late. The vulnerable query has already been generated. The only safe place to enforce governance is before the SQL exists. That place is compile time. Fix the context, not the model.
Short answer
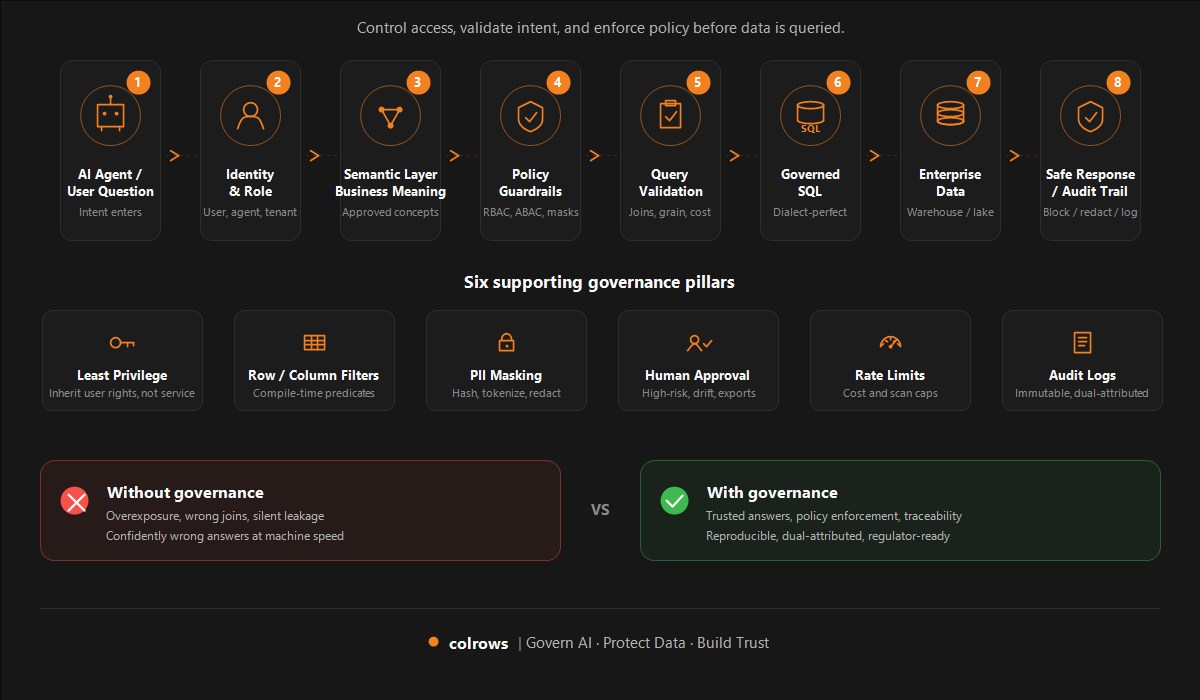
To govern AI agents that query enterprise data, do not give them open access to databases. Route every request through a controlled pipeline that verifies who is asking, what business meaning applies, which data policies must be enforced, whether the resulting query is safe to execute, and what the response is allowed to contain. The simple rule: an AI agent should not go directly from natural language to raw SQL. It should go from identity to intent, intent to semantic meaning, semantic meaning to policy, policy to validated query, query to governed execution, and only then to an audited response.
This matters because agents do not only answer questions. They chain steps, call tools, retain context, run repeated queries, summarize sensitive results, and trigger downstream workflows. Governance must cover the full path from user request to final response, not just the database boundary.
Legacy runtime security vs. semantic governance
The fastest way to see the gap is to put the two enforcement models side by side. Legacy security waits for the database to reject a bad query. Semantic governance refuses to compile one in the first place.
| Capability | Legacy runtime security | Colrows semantic governance |
|---|---|---|
| Enforcement | Post-query (database layer) | Pre-query (compile time) |
| Policy logic | Scattered across DB views | Centralized semantic graph |
| Agent safety | High risk of over-querying | Deterministic access guardrails |
| Auditability | Manual log parsing | Automated SQL lineage |
| Speed | Query bottleneck | Zero-latency execution |
The architecture gap
The difference between the two columns is not a feature gap. It is an architectural rift. It decides whether an unauthorized agent query is ever generated at all.
The flaw of runtime checks
Waiting for the database to reject an unauthorized AI query wastes compute and risks exposing schema layouts. By the time the engine returns a permission error, the agent has already built the query, named the tables, and inferred the relationships. The attack surface is the generated SQL itself. Every rejected query is a free schema probe. At agent speed, thousands of these run before a human sees one log line.
The compile-time mandate
Colrows enforces access policies during the semantic compilation process. The AI only receives SQL it is explicitly authorized to execute. If a user cannot see a column, the column never enters the plan, so it can never be probed, leaked, or rejected. Data access control binds RBAC, ABAC, row predicates, and column masking to identity at compile time, and the semantic control plane makes that enforcement a property of the architecture rather than a runtime hope. The same guarantee holds when the caller is an autonomous agent instead of a human: every MCP tool call resolves through the identical persona and predicate stack, scoped to metadata:read or data:query.
Do not attempt to secure the AI model. Secure the data context before the model ever sees it. Fix the context. Not the model.
Why AI agents create new enterprise data risks
Traditional analytics access was human-driven and constrained: a user opened a dashboard, picked filters, exported a report, or asked an analyst for SQL. AI agents change the pattern. They generate SQL dynamically, choose tools, infer intent, and run queries at machine speed. That collapses two assumptions enterprise data systems were quietly built on: that the consumer understands the schema, and that there is a human in front of every dangerous query.
The benchmark record makes the problem concrete. On clean academic data (Spider 1.0), top models reach roughly 86 to 91% execution accuracy; this is the number that powers most demos. On real enterprise schemas, accuracy collapses. The Spider 2.0 paper (Lei et al., arXiv:2411.07763) reports that an o1-preview code-agent framework "successfully solves only 21.3% of the tasks, compared with 91.2% on Spider 1.0 and 73.0% on BIRD," and the official leaderboard states that "even the advanced LLMs-o1-preview solve only 17.1% of Spider 2.0 tasks. For widely-used models like GPT-4o, the success rate is only 10.1% on Spider 2.0 tasks, compared to 86.6% on Spider 1.0." On MIT's enterprise BEAVER benchmark (Chen et al., arXiv:2409.02038), GPT-4o and Llama3-70B-Instruct "achieved close to 0 end-to-end execution accuracy," with BEAVER results "on average, 64.4% lower than Spider, 27.6% lower than Bird." This is the accuracy cliff that ungoverned agents fall off the moment they meet a real warehouse.
The risks that follow are not theoretical. They are the same risk classes OWASP enumerates for LLM applications, mapped to the data-access case:
| Risk | What happens | Governance impact |
|---|---|---|
| Over-broad access | The agent has access to more tables or columns than the user actually needs. | Sensitive data may be exposed through generated answers (OWASP LLM02, Sensitive Information Disclosure). |
| Prompt injection | A user, document, or tool response instructs the agent to ignore policy or reveal hidden data. | The agent may treat malicious instructions as valid task context (OWASP LLM01). |
| Wrong business logic | The agent picks a table, metric, or join that sounds correct but is not approved. | Executives receive confident but incorrect answers (the BEAVER-class failure). |
| Unbounded queries | The agent runs expensive scans, fans out joins, or repeats tool calls in a loop. | Costs rise and operational systems may degrade. |
| Data exfiltration | The agent includes sensitive values in responses, logs, summaries, or external tool calls. | Regulated information leaves approved boundaries (OWASP LLM05, Improper Output Handling; LLM08, Vector and Embedding Weaknesses for retrieval-backed agents). |
| Weak auditability | The enterprise cannot reconstruct why an answer was produced. | Compliance, incident response, and user trust all suffer. |
The cost of compounding these errors is concrete. Gartner's Magic Quadrant for Data Quality Solutions (27 July 2020, Chien and Jain), based on 154 reference-customer interviews, found that "poor data quality costs organizations on average $12.9 million per year." Agents multiply that cost: a single mistaken definition can ride a thousand auto-generated reports before anyone notices. The point is not that agents are unsafe to deploy. It is that they cannot be deployed safely on documentation alone.
A practical governance model: seven layers
Enterprise AI governance should not depend on system prompts or user training. Prompts are useful; they are not a control plane. Microsoft's Power BI Copilot documentation states plainly that "Because AI instructions are unstructured guidance to Copilot, the LLM only interprets them. There's no guarantee that the LLM will exactly follow instructions." Governance must be enforced in the architecture. A practical model has seven layers, ordered so that every request passes them in sequence and a failure at any layer stops the request with a logged reason:
- Identity and role. Every request carries the human user, agent identity and version, application, workspace or tenant, and business purpose. Anonymous agent access is not allowed. The agent inherits the effective permissions of the user, not a generic broad-rights service account.
- Semantic resolution. The agent's natural-language intent is resolved into approved business concepts, metrics, entities, relationships, and join paths before any SQL is generated. Without this step, the agent guesses from schema names and emits plausible but wrong SQL.
- Policy enforcement. RBAC, ABAC, row filters, column masking, purpose limitation, and data-classification rules are applied as a compilation pass, so they shape the plan rather than filtering its output. If a user is not allowed to see a column, the column does not appear in the SQL.
- Query validation. The compiled query is checked against the metric's declared grain, the approved join graph, cost and scan estimates, restricted fields, required filters, and anomaly heuristics. This is distinct from policy (see below) and prevents accidental broad scans, fan-out aggregates, and unusually wide queries.
- Execution. The governed SQL runs against the data engine. By the time the query reaches the database, it has already been bound, policed, and validated, so the database's own controls become a backstop rather than the primary defense.
- Response guard. The final answer is checked for sensitive values, derived disclosures, and aggregation or inference leakage before it returns to the user or to the next tool. The canonical actions are block, redact, or escalate to a human queue, applied with layered detectors (regex and secret patterns for structured PII, ML classifiers for content and groundedness).
- Audit and reproducibility. The system records the human question, resolved intent, semantic definitions and versions, policies applied, generated SQL, tables and columns accessed at a summary level, result metadata, response action, and dual-attributed timestamps. Logs are immutable, tamper-evident, queryable by data subject, and retained per regulation (SOX: 7 years; HIPAA: 6 years; GDPR: queryable and erasable per request).
The seven layers map cleanly onto the broader semantic control plane and the four-stage Colrows runtime: intent → context resolution → constrained planning → governed execution. The rest of this post takes each layer in turn.
1. Start with identity, role, and purpose
Governance begins before the query. The system must know who is asking, which agent is acting, what role the user holds, which workspace or tenant the request belongs to, and what business purpose it serves. The most common production mistake is giving the agent a single service account with broad database permissions. It is easy to ship and impossible to govern.
The agent should inherit the effective permissions of the human user and the task. The request context travels with the call through every subsequent layer.
Risky pattern: generic agent access
AI_AGENT_SERVICE_ACCOUNT
access: SELECT on all customer, revenue, transaction, and risk tables
masking: none
row filters: none
purpose controls: noneGoverned pattern: user-scoped agent access
request_context:
human_user: regional_manager_42
agent: finance_analytics_agent
agent_version: 2026.06.14
role: regional_manager
region_scope: west_india
purpose: portfolio_review
allowed_output: aggregated_summary
pii_access: masked_onlyThis context flows all the way through semantic resolution, policy enforcement, SQL generation, execution, response formatting, and audit. It is also the record the audit layer signs every event with, so dual attribution (human plus agent) is preserved end to end.
2. Resolve the agent's request through a semantic layer
AI agents understand natural language. Enterprise data requires business meaning. A request such as "show risky customers with overdue exposure" is not a database query yet. It is intent that must be resolved against approved concepts before SQL is emitted.
A semantic layer answers questions such as:
- What does "risky customer" mean in this domain, and which risk score or risk band is approved for this use case?
- Which "overdue exposure" metric should be used, with which currency and as-of grain?
- Which customer definition applies: borrower, applicant, account holder, or legal entity?
- Which join path connects customer, loan, collateral, payment, and region, and is it valid for this persona?
- Which fields are allowed for this user and purpose?
Without semantic resolution, the agent guesses from schema names and produces SQL that looks correct but uses the wrong definition. This is the BEAVER failure mode at zero percent.
Without semantic layer: direct schema guessing
SELECT
c.name,
c.mobile,
r.score,
l.overdue_amount
FROM customers c
JOIN risk_scores r ON r.customer_id = c.id
JOIN loans l ON l.customer_id = c.id
WHERE r.score > 80;With semantic layer: approved concepts before SQL
resolved_intent:
entity: borrower_account
metric: approved_overdue_exposure_v2
risk_definition: credit_risk_band_v4
region_scope: user.assigned_region
pii_policy: masked
output_grain: account_summary
query_mode: governed_sqlResolution makes governance practical because policy attaches to business concepts rather than to raw columns. A semantic layer also closes a class of leakage that row filters cannot touch: two tenants on the same warehouse can have identical schemas and different definitions of "revenue," and if the agent resolves to the wrong definition no row crossed a boundary and the answer is still wrong. Independent work (arXiv:2410.20024; OpenReview's "Semantic Grounding as a Hallucination Mitigation Layer"; dbt Labs' 2026 Semantic Layer accuracy reruns) confirms the size of the effect.
Semantic-layer approval: detect, route, approve
One contradiction worth resolving up front: if the semantic layer only resolves to approved concepts, why does a human-approval gate exist for "metric definitions that have changed recently"? Because the semantic layer is the detector, not the approver. When a definition drifts, is promoted from a draft, or has not yet cleared review, the layer flags it and routes the request to a named human approver with a defined window (for example, definitions promoted within the last 24 hours). The semantic layer detects; humans approve; the audit layer records both. Without that split the layer reads as if it both blesses and re-blesses meaning, which is incoherent.
3. Enforce policy before data is queried
Policy should not be a note in documentation. It must be part of query planning. If a user cannot see a column, the column does not appear in the generated SQL. If a user can only see one region, the region filter is injected before execution, not after. The main controls are:
- RBAC: role-based access for analyst, manager, auditor, executive, support user, and so on.
- ABAC: attribute-based rules for region, department, tenant, data domain, purpose, clearance level.
- Row-level filters: restrict records by geography, account ownership, business unit, or tenant.
- Column-level controls: block, mask, hash, or tokenize sensitive fields.
- Purpose limitation: allow a metric for one task and disallow it for another.
- Aggregation rules: allow summary answers while blocking record-level extraction.
Policy-aware governed SQL
SELECT
MASK(c.customer_name) AS customer_name,
r.risk_band,
l.overdue_bucket,
l.exposure_bucket
FROM governed_borrower c
JOIN governed_loan_exposure l
ON l.borrower_id = c.borrower_id
JOIN governed_risk_profile r
ON r.borrower_id = c.borrower_id
WHERE r.risk_band IN ('HIGH', 'CRITICAL')
AND c.region_id = CURRENT_USER_REGION()
AND l.business_unit IN CURRENT_USER_ALLOWED_BUSINESS_UNITS();Phone numbers, email addresses, PAN, Aadhaar, salary, and other restricted fields never enter the query. This is structurally stronger than generating broad SQL and hoping a downstream filter hides the sensitive columns. Compile-time policy enforcement is what makes precision security tractable on real schemas.
Policy layer vs. query validator: distinct responsibilities
These two layers overlap in casual descriptions and must be cleanly separated to be operable. The line:
- Policy layer answers "who is allowed to access what." It binds RBAC, ABAC, row predicates, and column controls per identity, persona, and purpose. Its inputs are identity and the semantic graph; its output is a permitted subgraph.
- Query validator answers "is this specific compiled query safe, well-formed, and efficient." It checks join validity against the proven graph, result grain against the metric's declared grain, cost and scan estimates against budgets, restricted fields against the column registry, and unusual access patterns against the user's normal behavior.
Both can block a query, but they answer different questions and produce different audit events. Without the split, you cannot tell at incident time whether a denial was a policy decision (the user was not allowed) or a validation decision (the query was malformed or oversized).
4. Validate generated queries before execution
Even after policy is applied, generated SQL should be validated before execution. The validator's job is to catch the things policy does not encode: scans too large to be reasonable, join paths that fan out, grains that do not match what the metric promised, missing filters that turn an aggregate into a full-table sweep, columns flagged restricted that slipped through a view, and queries that look nothing like the user's normal pattern.
A working query validator should check:
- Only approved tables, views, metrics, and columns are referenced.
- All required row-level filters are present.
- No restricted columns appear in the projection or in derived expressions.
- Join paths match the proven graph (no implicit cross joins, no unsupported many-to-many fan-outs).
- Result grain matches the metric's declared grain (compared against the GROUP BY structure).
- Estimated scan size is within budget (per-engine dry-run bytes for BigQuery,
EXPLAINcost for Snowflake or Postgres, row-count caps for detailed outputs). - The query is not anomalously different from the user's normal access pattern.
Query that should be blocked or escalated
SELECT *
FROM customer_master c
JOIN transaction_history t ON t.customer_id = c.customer_id
WHERE t.transaction_date >= DATE '2020-01-01';This is risky on every axis: it projects every column (likely including PII), scans a six-year window, and returns customer-level detail. A governed system should block it, rewrite it into an approved aggregate, or escalate it to a human approver.
Safer rewrite
SELECT
DATE_TRUNC('month', t.transaction_date) AS month,
c.region,
COUNT(DISTINCT c.customer_id) AS active_customers,
SUM(t.amount) AS transaction_value
FROM governed_customer_summary c
JOIN governed_transaction_summary t
ON t.customer_id = c.customer_id
WHERE t.transaction_date >= DATE '2026-01-01'
AND c.region = CURRENT_USER_REGION()
GROUP BY 1, 2;5. Guard the response, not just the query
If policy already blocked unauthorized columns, why does a response guard exist? Because a compliant query can still produce a non-compliant answer. Three failure modes the response layer catches:
- Derived disclosure. A summary or natural-language gloss reconstructs a sensitive value from non-sensitive aggregates. The classic case: a five-row group that uniquely identifies a customer.
- Indirect prompt-injection fallout. A retrieved document instructs the agent to embed system context, credentials, or another tenant's content in its answer.
- Aggregation and inference leakage. Repeated queries combine into an inference that no single query authorized.
The response guard runs layered detectors on the output: regex and secret-pattern matchers for structured PII (PAN, Aadhaar, SSN, payment cards, API keys), groundedness classifiers for hallucinated facts, and content classifiers for derived disclosure. The standard on-flag actions are block, redact, or escalate to a human reviewer, with a logged reason. Industry alignment is broad: OWASP LLM05 (Improper Output Handling) and LLM02 (Sensitive Information Disclosure), plus AI-gateway vendors such as Bifrost, Maxim, Tetrate, TrueFoundry, and FutureAGI, all treat output-side guards as table stakes. This is the defense-in-depth layer that exists precisely because compile-time policy cannot model every disclosure path.
6. Log, audit, and make every answer reproducible
AI agent governance is incomplete without auditability. If an agent produces a wrong, sensitive, or contested answer, the enterprise must reconstruct exactly what happened, with what definitions, under what policy, for which user.
An audit event for a single agent question should capture, at minimum:
- Human user identity
- Agent identity and version
- Original user question
- Resolved business intent
- Semantic definitions and versions used (e.g.,
approved_overdue_exposure_v2,credit_risk_band_v4) - Policies evaluated and applied
- Generated SQL or tool calls
- Tables, columns, and rows accessed at a summary level
- Result size, response type, and response action (allowed, blocked, rewritten, escalated)
- Dual-attributed timestamps (human plus agent)
Example audit event
{
"user": "regional_manager_42",
"agent": "portfolio_ai_agent",
"agent_version": "2026.06.14",
"question": "Show high-risk borrowers with overdue exposure",
"resolved_metric": "approved_overdue_exposure_v2",
"risk_definition": "credit_risk_band_v4",
"policy_result": "allowed_with_masking",
"row_scope": "west_india",
"columns_blocked": ["mobile_number", "email", "pan_number"],
"sql_status": "compiled_governed_sql",
"result_grain": "account_summary",
"response_action": "delivered",
"audit_status": "recorded"
}Audit fields that are necessary but not sufficient
The event above is necessary; on its own it does not satisfy any regulator. Regulatory requirements layer on top:
- SOX (financial reporting). 7-year retention, segregation of duties between requester and approver, dual attribution (human plus agent), and a tamper-evident store.
- HIPAA. 6-year retention, field-level access logs against PHI, unique user ID per accessor (45 CFR 164.312(a)(2)(i) and (b)). Enforcement settlements (Memorial Healthcare System, $5.5M; Excellus, $5.1M) cite organizations that logged but did not review.
- GDPR. Queryable by data subject (Article 15), portable (Article 20), erasable on request (Article 17), with retention bounded by purpose. No silent deletion.
- EU AI Act. For high-risk AI systems, Article 12 requires automatic logging of events relevant to the system's operation, and Article 14 requires demonstrable human oversight.
Point-in-time reproducibility is the property regulators actually test: re-running yesterday's question against yesterday's definition versions, policies, and identity context produces yesterday's answer. A versioned semantic graph plus immutable audit logs is the only architecture that makes this property cheap rather than heroic.
7. Human approval for high-risk requests
Not every agent action should be fully automated. Some requests should require a human checkpoint: anything that involves sensitive identifiers, external sharing, large exports, irreversible side effects, or unusually broad access. The principle is from the NIST AI Risk Management Framework (Manage function) and EU AI Act Article 14: human oversight must be demonstrable, not nominal, on high-risk decisions.
Human approval should be required when the agent tries to:
- Export record-level customer or employee data.
- Access sensitive identifiers or financial detail at row grain.
- Query outside the user's normal region or business unit.
- Send results to an external destination (email, webhook, third-party tool).
- Run a high-cost query across very large datasets.
- Trigger downstream operational actions (a payment, a status change, a notice).
- Use a metric definition that the semantic layer has flagged as recently changed (promoted within the last 24 hours, for example) and not yet re-blessed.
Human-in-the-loop is not a weakness in the architecture. It is the control that exists precisely where the blast radius of an autonomous decision exceeds the system's ability to prove it correct.
Multi-tenancy: never trust the LLM with the boundary
If you run a SaaS or shared-warehouse deployment, tenant isolation is the first thing reviewers will ask about, and it cannot be enforced at the semantic layer alone. As Brian Hess writes in "Don't Trust the LLM with Tenant Isolation: Multitenant Cortex Agents on Snowflake" (Snowflake Builders Blog, May 2026): "We can't just trust the LLM to put the right WHERE clauses on every query — security should not depend on prompt engineering... Snowflake's existing governance primitives — RBAC, row access policies, and immutable session attributes — give you everything you need."
The correct stance is defense in depth:
- Database engine enforces tenant boundaries with row access policies and immutable session attributes that the LLM cannot rewrite.
- Semantic layer scopes meaning per tenant (so "revenue" can mean different things for tenant A and tenant B) and binds policies to identity and purpose. Data can be isolated; meaning must also be isolated, or two tenants get correctly scoped rows with the wrong definitions.
- Identity layer passes immutable tenant context through MCP, HTTP, and JDBC, set per transaction so a pooled connection never leaks the previous tenant.
The semantic layer is a strong control, not the only one. The blog you are reading describes governance over the data path; tenant boundaries belong in the engine and the identity provider as well.
Failure modes: what happens when the model is wrong, stale, or unreachable
Any honest architecture is judged by its failure mode. The seven layers should fail loudly with a logged reason at every boundary, and the system should be explicit about what happens when the semantic graph itself is stale, ambiguous, or in flight.
- Stale graph. If a new definition is being promoted, the compiler continues to bind against the last-known-good version until promotion completes and a human has approved it. Yesterday's question keeps yesterday's answer.
- Unresolved intent. If no approved concept matches the request, the system returns a structured error with a reason, not a guess. Loud failure beats fluent failure.
- Unprovable join. If the requested grain or relationship has no proven path in the allowed subgraph, the compiler refuses with the missing edge named in the error.
- Validator denial. Distinguished from policy denial in the audit event so incident review can tell "you were not allowed" from "the query was not safe."
- Response-guard flag. Records the detector, the rule, and the action (block, redact, escalate), so the same input can be replayed against a tuned ruleset later.
The pattern: never silently substitute. Always emit a reason. Always log enough to reproduce.
Reference architecture, at a glance
| Layer | Responsibility | Why it matters |
|---|---|---|
| Identity | Authenticates user, agent, tenant, workspace, and role; carries purpose and context end to end. | Prevents anonymous or generic access; enables dual attribution in audit. |
| Semantic layer | Resolves intent to approved metrics, entities, relationships, definitions; flags drift; routes unapproved definitions to a human. | Closes the BEAVER-class failure where schema-guessed SQL is plausibly wrong. |
| Policy | Binds RBAC, ABAC, row/column predicates, purpose limitation, classification rules to identity at compile time. | Unauthorized plans are never generated; precision security is structural. |
| Query validator | Checks joins, grain, cost, restricted fields, required filters, anomaly patterns against the proven graph. | Catches what policy does not encode: fan-outs, scans, grain mismatches. |
| Execution | Runs governed dialect-perfect SQL against the engine. | The database sees only policy-compliant, validated queries. |
| Response guard | Detects derived disclosure, prompt-injection fallout, and aggregation leakage; blocks, redacts, or escalates. | Defense in depth against disclosures that compile-time controls cannot model. |
| Audit | Immutable, tamper-evident, dual-attributed, point-in-time reproducible, data-subject queryable. | Satisfies SOX, HIPAA, GDPR, EU AI Act logging requirements; enables incident review. |
Implementation priorities: an eight-month rollout
A seven-layer architecture implemented from scratch is a multi-quarter program, not a sprint. The order matters: certain layers are prerequisites for the safety of the next. A reasonable rollout:
- Months 1 to 2: Identity and policy. Remove generic service accounts. Pass human identity end to end. Wire RBAC, ABAC, and row/column predicates into the planner so unauthorized plans are never generated.
- Months 2 to 4: Semantic layer. Build the approved-metric registry and natural-language-to-metric resolution. Version every definition. Add the drift detector that routes unpromoted definitions to a human queue.
- Months 4 to 5: Query validator. Add join-graph proof, cost and scan caps, grain checks, restricted-field guards, anomaly detection.
- Months 5 to 6: Audit and reproducibility. Immutable, dual-attributed, retention-compliant logs. Data-subject queryability for GDPR. Replay tooling.
- Months 6 to 7: Response guards. Layered detectors (regex + classifier), block/redact/escalate actions, reviewer queue.
- Months 7 to 8: Human approval workflows. Approval routes for high-risk requests; recently-promoted definitions; large exports; external sharing.
Test at each stage with non-production agent queries. Do not release agents to production until audit logging is in place. Track that governance is actually working with a small set of red-team scenarios per release: prompt injection through a retrieved document, a request for a recently-changed metric, a request for a cross-tenant join, a request that fans out, a request that asks for a restricted column by a synonym.
How Colrows approaches AI agent governance
Colrows is a semantic compiler with its semantic layer built in. It is the runtime sense of "semantic execution layer." When an AI agent asks a question, Colrows resolves the request through business meaning before SQL is produced. Governance attaches to semantic concepts (revenue, customer, loan, risk, claim, region, margin, active user) rather than being scattered across prompts, dashboards, SQL files, and individual applications.
Concretely, this is how the seven layers land in Colrows: identity flows over MCP, HTTP, and JDBC and carries human, agent, tenant, persona, and purpose. The semantic graph is versioned, typed, and multi-scope (global → datastore → persona → user), with drift detected and routed to a human approver. Policy is a compile-time pass. RBAC, ABAC, row predicates, and column controls shape the plan before SQL exists. The query validator proves join paths and bounds scans against the engine's own cost estimates. Execution emits dialect-perfect SQL per warehouse. The response is checked before it leaves. Every step is logged into an immutable, dual-attributed audit trail that can be replayed point-in-time against the exact definitions, policies, and identity context that were in force when the question ran. Agents become more useful without becoming uncontrolled.
Frequently asked questions
Should AI agents have direct database access?
For enterprise data, direct access is risky. AI agents should query through governed interfaces, semantic layers, approved views, or policy-aware APIs rather than raw database credentials. The agent should inherit the user's effective permissions, not a generic service account with broad rights.
Is prompt engineering enough to govern AI agents?
No. Prompts can guide behavior, but they are not reliable governance controls. OWASP LLM01 (Prompt Injection) and Microsoft's own Power BI Copilot documentation confirm that LLM instruction-following is best-effort. Access rules, masking, row filters, validation, and audit logs must be enforced outside the model.
How does a semantic layer help governance?
A semantic layer maps natural language to approved business concepts, metrics, entities, relationships, and policies. This lets governance attach to meaning, not only to raw tables and columns, and it cuts the schema-guessing class of errors that LLMs produce on real enterprise databases (Spider 2.0: GPT-4o 10.1%; BEAVER: near zero).
What is the biggest risk of AI agents querying enterprise data?
The biggest risk is not only data leakage. It is confident wrong answers generated from incorrect metrics, invalid joins, missing filters, or misunderstood business terms, multiplied across thousands of agent calls before anyone notices.
Do all agent queries need human approval?
No. Low-risk, aggregated, policy-compliant queries can be automated. Human approval should be used for sensitive data, large exports, external sharing, high-cost queries, operational side effects, or any request that touches a metric definition flagged as recently changed and not yet promoted. NIST AI RMF Manage and EU AI Act Article 14 require demonstrable human oversight for high-risk decisions.
What should be logged for AI data access?
Log the human user, agent identity and version, original question, resolved business intent, semantic definitions and versions, policies evaluated and applied, generated SQL, tables and columns accessed at a summary level, result size, response action (allowed, blocked, rewritten, escalated), and timestamps. Logs must be immutable and retained per regulation.
How long should audit logs be retained?
SOX: 7 years for financial-reporting evidence. HIPAA: 6 years for PHI access logs. GDPR has no fixed retention but requires queryability by data subject and the ability to delete or export one subject's records without touching another's. Logs should be tamper-evident and dual-attributed (human plus agent).
What is point-in-time reproducibility and why does it matter?
A historical query can be re-run with the exact semantic definitions, policies, and access rules that were in force when the original query ran, producing the same result. Regulators (SOX, GDPR, sectoral financial rules) test for it, because a probabilistic generator cannot offer it even in principle.
Can multi-tenancy be enforced at the semantic layer alone?
No. The semantic layer should scope meaning per tenant and enforce policy at compile time, but tenant data isolation must also be enforced at the database engine using row access policies, column masking, and immutable session attributes. Defense in depth: never trust the LLM or any single layer with tenant boundaries.
Closing thought
AI agents can make enterprise data dramatically more accessible. Access without governance is dangerous. The right model is not to block agents; it is to give them a governed path from intent to answer, with seven well-defined layers in between, every one of which can refuse for a logged reason. In the AI era, governance moves from documentation to execution. Policies stop describing what is allowed and start shaping the query before any enterprise data is touched. Prove the query, then run it.


