What WisdomAI actually is
WisdomAI (legal name Wisdom AI, Inc.; wisdom.ai) was founded in 2023 in San Mateo, California by Soham Mazumdar (CEO and co-founder, previously co-founder and chief architect of Rubrik), Sharvanath Pathak, Kapil Chhabra, and Guilherme Menezes. It launched publicly in late 2024. It raised a $23M seed round (led by Coatue, May 2025) and a $50M Series A (led by Kleiner Perkins with participation from NVIDIA's NVentures, November 12, 2025). Per TechCrunch (November 12, 2025), CEO Soham Mazumdar said WisdomAI "has grown from two enterprise customers to around 40 enterprise customers," naming Descope, ConocoPhillips, Cisco, and Patreon.
WisdomAI positions itself as the "AI Data Analyst for the enterprise" and a "Federated Agentic Intelligence Platform." Its product line includes Conversational BI, AI-powered Dashboards, Analytics Agents (May 2026), Proactive Agents (September 2025), and Embedded Agentic Analytics. The core is the "Adaptive Context Engine" (also called the Enterprise Context Layer or Knowledge Fabric), which learns metric definitions, entity relationships, and business vocabulary.
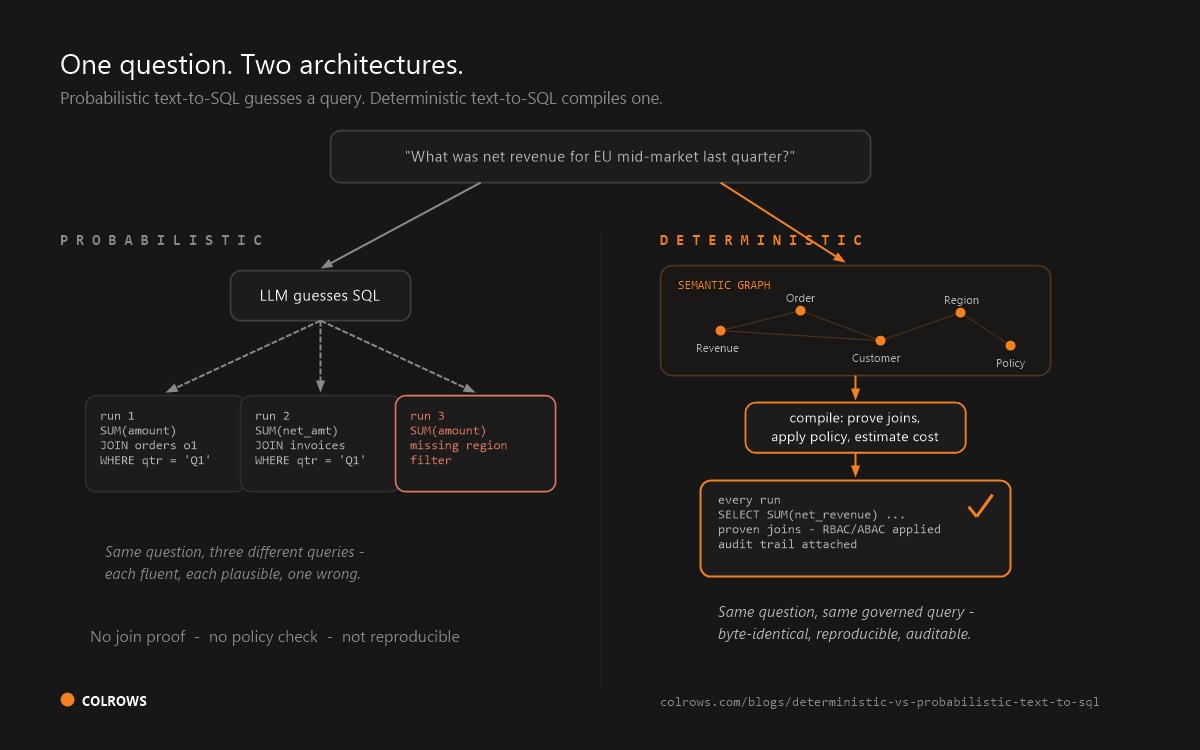
Architecturally, WisdomAI's key design decision is that it uses LLMs only to generate queries, not answers, which limits hallucination risk. It connects to Snowflake, BigQuery, Redshift, Databricks, and Postgres, and can ingest unstructured data such as PDFs. It enforces row-level and column-level security at query time in the data layer, offers single-tenant VPC, on-prem, and bring-your-own-LLM deployment, and carries SOC 2 Type II, HIPAA, and GDPR compliance.
WisdomAI's genuine strengths
- Strong conversational BI with a low learning curve. A Gartner Peer Insights reviewer noted business users self-serve answers on bookings and pipeline "while our compliance and RBAC controls stays intact."
- Handles structured, semi-structured, and unstructured or "dirty" data, which is unusual among BI tools.
- The query-only-LLM design is a sound, defensible approach to hallucination control.
- Fast time-to-value and proactive, agentic monitoring. Per TechCrunch, Mazumdar said one customer "started with 10 seats and expanded to 450, which is almost everyone in the company."
- Blue-chip investors (Kleiner Perkins, NVIDIA's NVentures), a strong founding pedigree from Rubrik, and rapid feature velocity.
WisdomAI's gaps and limitations
- Governance is enforced at query time, not compile time. WisdomAI states RLS and CLS are "enforced at query time in the data layer." This is materially weaker than compile-time governance, where unauthorized queries fail compilation and filtered rows are never read.
- Trust rests on a learned context engine, not a formally proven semantic graph. The Adaptive Context Engine "auto-learns" definitions and the company claims "95%+ accuracy." This is a probabilistic, learning-based approach. There is no published evidence of formally proven join paths or point-in-time, versioned reproducibility.
- Accuracy claims are self-reported and not benchmarked. WisdomAI's "95%+ accuracy" is a marketing figure with no published methodology. Independent enterprise benchmarks: on Spider 2.0 (ICLR 2025), the strongest model o1-preview scores 23.77% execution accuracy on Spider 2.0-Snow and ~23.22% on Spider 2.0-Lite. On BEAVER, off-the-shelf LLMs including GPT-4o and Llama3-70B-Instruct "achieved close to 0 end-to-end execution accuracy," and even SOTA agentic frameworks reach only 10.8%.
- Determinism is claimed but not externally verifiable. WisdomAI's Analytics Agents marketing claims "deterministic outputs" and full auditability and replay, but the underlying trust model is a learned context engine over LLM-generated SQL, so reproducibility is asserted rather than structurally guaranteed.
- Customer-reported pain points. Gartner Peer Insights reviewers cite non-transparent customer support, long run times loading data tables from Snowflake, "finicky" NL interactions when changing visualizations, and having to choose specific domains.
- Thin third-party validation. No substantive G2 product profile; only ~15 Gartner Peer Insights reviews. No public pricing.
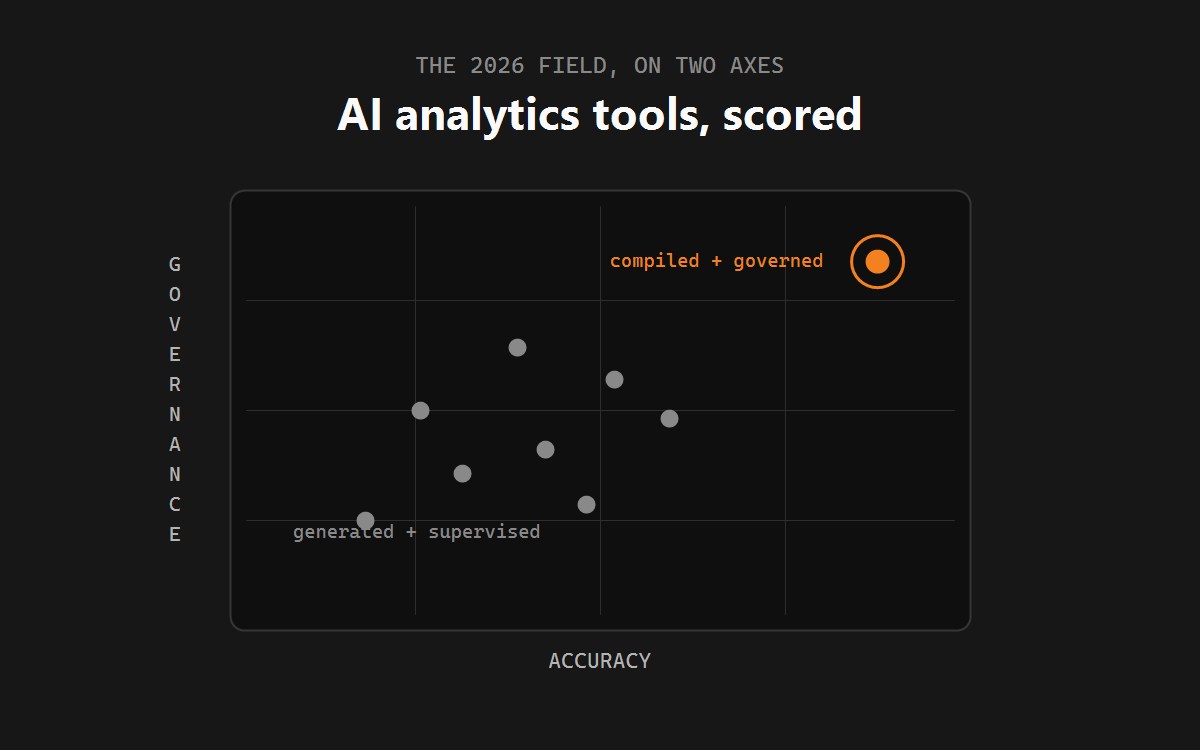
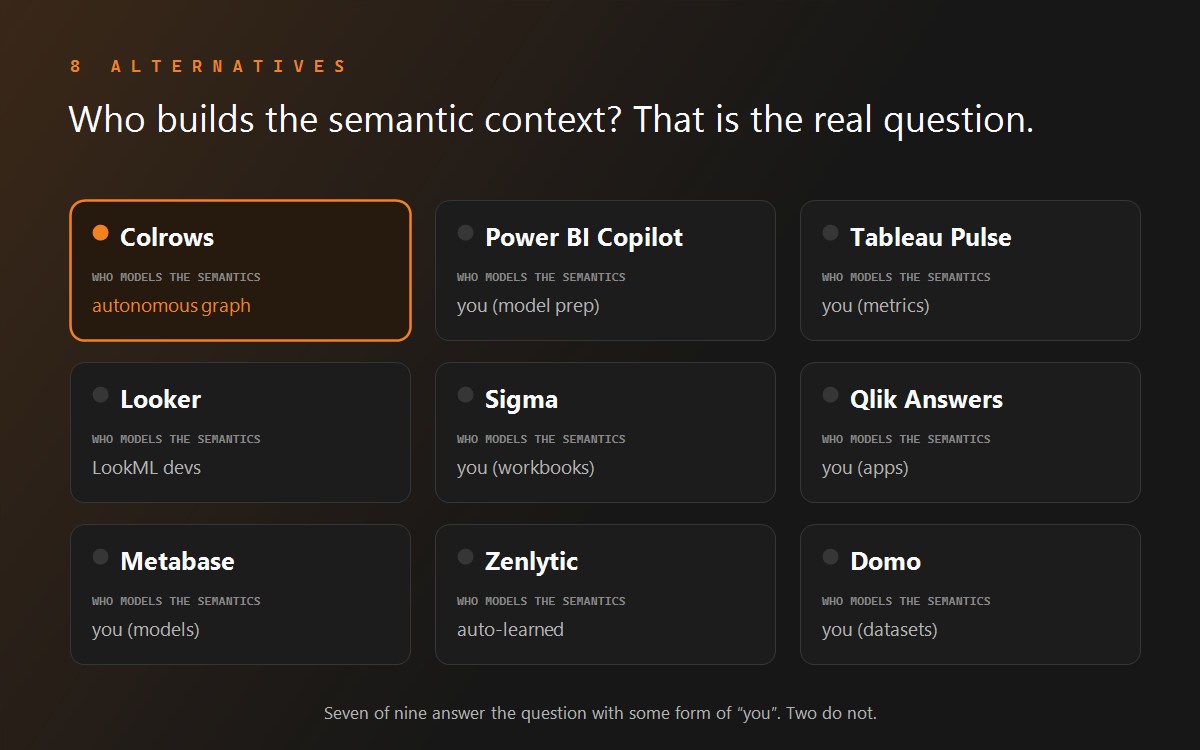
Colrows vs WisdomAI (head-to-head)
Colrows (founded 2024, Pune; bootstrapped) positions itself as a "semantic execution layer for enterprise AI." Its architecture is fundamentally different from WisdomAI's: rather than a learned context engine, Colrows autonomously builds and maintains a typed semantic graph and compiles every agent query through a deterministic pipeline (intent → context resolution → constrained planning with proven joins and policy enforcement → governed execution as dialect-perfect SQL).
Verified Colrows claims:
- 16+ data sources and dialect-perfect SQL per engine (Snowflake, Databricks, Redshift, BigQuery, Postgres, MySQL, ClickHouse, Trino, +).
- Compile-time governance: RBAC, ABAC, and row/column-level predicates evaluated before any SQL touches the warehouse; "unauthorised queries fail compilation, not in production."
- Autonomous maintenance: statistical drift detection, structural diffing, conflict and duplicate resolution, and schema-change handling.
- Proven joins: "every join proven at compile time."
- Customers: Pfizer, Cipla, BTS Group, Flobiz, Brexa, plus case studies referencing SSP (retail) and BFSI/finance.
- Pricing: Free tier ($0 forever, 5 Colrows Compute Tokens, unlimited datasources/users/policies) and a custom Enterprise tier (SSO/SCIM, public or private LLM, shared/dedicated/private instance, SLA-backed support, SOC 2 and HIPAA on request).
There is no public evidence of customer overlap between WisdomAI (Cisco, ConocoPhillips, Patreon) and Colrows (Pfizer, Cipla, BTS Group) - they currently serve different accounts and somewhat different geographies (US versus India and global).
Competitive positioning matrix (8-point CTO checklist)
| Criterion | WisdomAI | Colrows | Cortex Analyst | Genie | dbt SL | Cube | ThoughtSpot | Sigma |
|---|---|---|---|---|---|---|---|---|
| Determinism | Claimed (learned engine) | Compile-time deterministic graph | Semantic-model-bound | Space-bound | Versioned code | Compile-time | Search-token bound | Live-query |
| Governance enforcement | Query time | Compile time | Snowflake RBAC | Unity Catalog | Warehouse perms | Compile time | Semantic layer | Warehouse-inherited |
| Multi-warehouse | Multi (5 named) | 16+ engines | Snowflake only | Databricks only | Multi (4 named) | All SQL sources | Multi | Multi (cloud DW) |
| Semantic maintenance | Auto-learned | Autonomous (drift/diff) | Manual YAML | Manual space tuning | Manual code | Manual code | SpotterModel assisted | dbt / Semantic Views |
| Cost model | Custom (opaque) | Free + custom Enterprise | Per-message + compute | PAYG DBUs | Queried Metrics | OSS + Cloud tiers | Enterprise custom | $300/mo + custom |
| Unstructured data | Strong | Ingests docs/Confluence | Via Cortex Search | Via Genie | No | No | Spotter 3 (MCP) | Limited |
| Time-to-value | Fast | Hours to graph | Fast (in Snowflake) | Fast (in Databricks) | Slower | Moderate | Moderate | Fast |
| Agent / MCP | MCP endpoint | LLM-agnostic | Via Cortex Agents | Managed MCP | SL APIs | MCP server | MCP server | Agent runtime |
The six alternatives
- Snowflake Cortex Analyst - warehouse-native text-to-SQL using a YAML or Semantic View model. Snowflake's engineering blog states it achieves "90%+ accuracy on real-world use cases" on an internal 150-question benchmark. Pricing is message-based (67 credits per 1,000 messages via the standalone API, plus warehouse compute). Best for Snowflake-committed shops; weak for multi-warehouse. See Cortex Analyst alternatives.
- Databricks Genie / Genie Code - Databricks-native agentic BI. Requires Unity Catalog, allows up to 30 tables per space, only queries data stored in Databricks. Best for Databricks-committed shops.
- dbt Semantic Layer / MetricFlow - code-first, version-controlled metrics with warehouse-agnostic SQL generation. A single global namespace and dbt-platform dependency are real limitations. Best when dbt is the center of the stack.
- Cube - open-source headless semantic layer (Cube Core, Apache 2.0) with compile-time row-level and multi-tenant security and an MCP server. Per Cube's case study, Brex chose Cube over dbt Semantic Layer and LookML to build Brex Spaces, an embedded AI financial analyst for 35,000+ customers, raising insight relevance from the high 50s to nearly 90%.
- ThoughtSpot Spotter - search-driven agentic BI that translates natural language into verifiable "search tokens" rather than direct text-to-SQL. LLM- and cloud-agnostic.
- Sigma Computing - warehouse-native, spreadsheet-UI BI plus an AI runtime, with a live-query model. Essentials starts at $300/month with unlimited users; the median annual deal is about $61,000 (range roughly $17,500 to $131,000), with warehouse compute separate.
(Palantir Foundry/AIP is a heavier, ontology-driven, full-stack alternative for mission-critical operational AI.)
Staged buyer guidance
- Choose WisdomAI when: you are mostly on one cloud warehouse, want fast proactive and conversational insights and unstructured-data Q&A, value a turnkey managed product, and do not require structural compile-time governance or formal multi-warehouse determinism.
- Choose Colrows when: you are standardizing AI agents across multiple warehouses, require compile-time RBAC/ABAC and proven joins, need point-in-time reproducibility and audit, and want autonomous semantic maintenance rather than manual modeling.
- Switching thresholds (evaluate alternatives when): you add a second warehouse dialect; an auditor requires that unauthorized queries fail before execution rather than at runtime; agents return inconsistent numbers for the same question; semantic maintenance becomes a recurring manual burden; or per-message or per-seat costs become unpredictable at scale.
Frequently asked questions
How much funding has WisdomAI raised?
~$73 million total. The $50M Series A led by Kleiner Perkins (with NVIDIA's NVentures) closed November 12, 2025.
What is WisdomAI's hallucination-avoidance approach?
Per TechCrunch: WisdomAI uses LLMs only to write queries, not answers. If the model hallucinates, it writes a failing query rather than a fabricated number.
Where does WisdomAI enforce governance?
At query time in the data layer (RLS and CLS). Colrows enforces RBAC, ABAC, and row/column predicates at compile time before SQL runs.
Does WisdomAI publish pricing?
No. WisdomAI does not publish public pricing. Colrows publishes a Free tier and a custom Enterprise tier.
How accurate is enterprise text-to-SQL?
Independent benchmarks show real difficulty: Spider 2.0 around 21-24% for top methods; BEAVER close to 0% end-to-end for off-the-shelf LLMs. Validate any 95%+ accuracy claim on your own schema.
Caveats
WisdomAI's "95%+ accuracy" and "deterministic outputs" are vendor marketing claims without published, independent benchmark methodology; present them as claims, not facts. Funding and employee data for WisdomAI conflicts across aggregators (Tracxn lists "$0/unfunded"; getlatka lists "$3.6M revenue, bootstrapped") - the authoritative figures are PR Newswire, Kleiner Perkins, TechCrunch, and PitchBook (about $73M raised). Colrows is an early-stage, bootstrapped 2024 company; it is smaller and less capitalized than WisdomAI. Its architectural claims (compile-time governance, proven joins, autonomous maintenance) are stated on its own site and should be validated in a proof of concept.