Standard RAG/LLM pipeline vs. Colrows autonomous infrastructure
| Security capability | Standard RAG/LLM pipeline | Colrows autonomous infrastructure |
|---|---|---|
| Access enforcement | Runtime (database-level) | Compile-time (deterministic) |
| Data exposure | High (context window risk) | Masked/filtered at compile-time |
| Policy logic | Patchwork / distributed | Centralized / auditable |
| Audit trail | Fragmented / incomplete | Full verifiable lineage |
| Inference risk | High (unrestricted access) | Restricted by semantic graph |
| Attack surface | Multiple (vector DB, LLM, agent) | Single point (compiler) |
The RAG security flaw and the compiler security advantage
The RAG security flaw: Most Company Brains rely on runtime filtering. The model receives data context first. Security is applied as a post-hoc mask. This is brittle. If the prompt changes slightly or an agent refines its query, the security filter often fails. The attack surface spans the vector database, the retrieval system, the LLM context window, and the agent orchestration layer.
The compiler security advantage: Colrows compiles the security policy into the SQL itself. The AI agent simply cannot construct a query that violates your access guardrails, because the compiler prevents it at the structural level. Access control is deterministic. Policies are enforced before data is retrieved. The result is a single, auditable control channel where security is a property of the compilation process, not a filter applied after the fact.
Security is not a feature; it is an architectural prerequisite. Do not govern the model. Govern the data context. Fix the context, not the model.
Learn how compile-time data access control works, and explore the full governance and semantic control plane architecture that makes this deterministic enforcement possible.
TL;DR
- Shadow AI and ad-hoc RAG add $670,000 to the average cost of a data breach (IBM 2025). 97% of organizations suffering AI-related breaches lacked explicit AI access controls. Only 34% with an AI governance policy audit for unsanctioned usage.
- Ad-hoc RAG creates structural attack surfaces: embedding inversion turns vector stores into plaintext document breaches, corpus poisoning succeeds with 5 malicious documents per 1,000 target questions, and indirect prompt injection (EchoLeak / CVE-2025-32711) bypasses four layers of defense in a single chain.
- A compile-time semantic layer enforces authorization before SQL is generated. The model never sees unauthorized data. Audit trails are tamper-evident and replayable. This is structurally different from runtime filtering and satisfies ISO 42001, SOX, GDPR, and HIPAA requirements as a byproduct of execution.
The Hard Truth About Ungoverned AI
Your organization just deployed a GenAI agent to your data warehouse. Your CISO was not consulted. Your data officer did not map the query surface.
This is shadow AI. And it is already a $670,000 liability.
IBM's 2025 Cost of a Data Breach Report examined organizations that suffered AI-related breaches. A clear pattern emerged: 97% lacked explicit AI access controls. High levels of shadow AI added an average of $670,000 to breach costs. The global average breach cost was $4.44 million. Organizations with shadow AI? $5.11 million.
This is not theoretical. It is the cost structure you face the moment your teams deploy RAG, LLM agents, or semantic-search tools without a single unified governance layer underneath.
An ad-hoc RAG system does one thing well: move data fast. It does one thing catastrophically: it replaces invisible, ungoverned flows with even more invisible flows. Your database logs show nothing. Your DLP/CASB cannot see conversational egress (it looks like HTTPS). Your compliance audit finds no trail.
A properly governed semantic layer acts as a net risk reducer. It forces all agent interactions through a unified compiler where row-level security, column-level masking, and audit logging are applied instantly. It replaces invisible flows with a single inspectable control channel. We covered the broader governance pattern in our guide on how to add governance to AI agents.
The cost difference is not marginal. It is the difference between operating and bankrupt.
Why Ad-Hoc RAG Explodes Your Attack Surface
The Hidden Attack Surface You Did Not Budget For
An ad-hoc RAG deployment chains together several independently managed layers:
- A vector store (Pinecone, Weaviate, pgvector) holding millions of embeddings
- Unverified source documents in that store (PDFs, emails, Slack, OneDrive)
- An LLM (yours, rented, or both) retrieving and reasoning over embeddings
- An agent layer with tool access, often running as a privileged service account
- A user interface channeling queries to all of the above
Each layer is a separate security perimeter. Governance is often non-existent. Nobody owns the data-classification problem. Nobody audits who accessed what. We unpacked this architectural fragility in RAG vs Semantic Layer: Architecture, Cost, and When You Need Both.
Embedding Inversion: Your Embeddings Are Plaintext
You assume embeddings are opaque. They are not.
Academic research published at ACL 2024 demonstrated transferable embedding inversion: recovering a meaningful share of original text from stored embeddings without even querying the embedding model. This means a breached vector store is functionally equivalent to a plaintext document breach. If a threat actor gets read access to your Pinecone cluster or your pgvector database, they recover the source documents.
This is not a distant risk. Pinecone has been the subject of multiple public credential-exposure incidents. PostgreSQL misconfigurations are among the most common cloud data breaches (17% of breaches in 2024 per Wiz).
For a CISO, the implication is simple: encrypt vector stores at rest with keys you control. Partition by tenant strictly. Treat the vector database with the same posture as the source documents, because it is the source documents in recoverable form.
Corpus Poisoning: Five Malicious Documents Can Dominate Retrieval
A sophisticated attacker does not need access to your entire knowledge base. They need access to inject documents.
PoisonedRAG (Zou, Geng, Wang & Jia; USENIX Security 2025) studied this systematically. The researchers injected five malicious texts per target question into knowledge bases ranging from 2.68 million to 8.84 million documents. Success rate: 90%. On some benchmarks, 97 to 99%. This scales. Injecting five documents per thousand target questions still represents poisoning less than 0.001% of the corpus, and it works.
How would an attacker inject documents? Email attachments indexed by your RAG ingester. Resumes uploaded to your career portal. Support tickets. A crafted SharePoint document shared with "everyone." A blog post hyperlinked in a Slack thread your agent crawls.
For a data officer, the implication is: every document reaching your RAG pipeline is a potential attack vector. If you are indexing external sources, you need document classification, malware scanning, and an inference-time filter that can detect poisoning signatures. The same hallucination class is documented in our analysis of how to prevent AI hallucinations on enterprise data.
Indirect Prompt Injection: The EchoLeak Proof Case
On June 25, 2025, Aim Labs disclosed CVE-2025-32711, a CVSS 9.3 zero-click vulnerability in Microsoft 365 Copilot. An attacker sent a crafted email to a victim. The email contained no visible malicious content. The victim never clicked anything. Copilot silently executed the attacker's instructions and exfiltrated data from the victim's OneDrive, SharePoint, Teams, and email.
The attack chained four bypasses:
- It evaded the XPIA (Cross-Prompt Injection Attack) classifier using reference-style Markdown links instead of direct URLs
- It bypassed the auto-redaction of embedded hyperlinks using a CSS image-loading technique
- It leveraged a CSP-allowed proxy (Teams/SharePoint) to fetch the actual malicious instructions
- It chained these techniques together so that at no single step did a safety classifier flag the payload as dangerous
Microsoft patched server-side in May to June 2025. The attack class, however, did not go away.
This is called LLM scope violation. It happens when an agent operating in context A (a victim's email) retrieves or follows instructions from context B (malicious content) without strict authorization boundaries.
You cannot patch your way out of this. Prompt-injection-style attacks are structural to how RAG and agent systems work. The best defense is multilayered: partition prompt space aggressively, filter both inputs and outputs, apply least-privilege access controls, and treat every document the agent touches as potentially adversarial.
A governed semantic layer helps by making the agent's access boundary explicit and compile-time-enforced. If an agent tries to query unauthorized rows or columns, execution halts before the model is even invoked. The model cannot hallucinate its way into data it should not see.
Side-Channel Attacks on Cached Context
In "The Early Bird Catches the Leak: Unveiling Timing Side Channels in LLM Serving Systems" (Song, Pang, Wang et al., Institute of Information Engineering, Chinese Academy of Sciences; arXiv 2409.20002), researchers demonstrated per-token cache hit/miss detection at 99% accuracy by measuring response latency. They recovered system prompts at 89% accuracy. They inferred other users' requests at 81.4% accuracy (rising to 95.4% with multiple queries).
The vulnerability affects every major provider: GPT-4, Gemini, Claude, DeepSeek, and Azure OpenAI all share KV-cache or semantic-cache memory between users.
For a CISO running multi-tenant AI infrastructure, this means: require per-user or batched KV-cache isolation (costs up to 38.9% first-token latency) or accept the side-channel risk and compensate with other controls (TTFT padding, network-layer timing obfuscation, monitoring for timing-based exfiltration attempts).
The Risk Comparison: What Each Architecture Exposes
| Architecture | Access Control | Audit Trail | Vulnerability Surface |
|---|---|---|---|
| Ad-Hoc RAG / Vector DB | Often absent or per-tool. Queries invisible to centralized identity systems. | Fragmented across vector DB, LLM provider, and application. Replay nearly impossible. | Highest. Embedding inversion, corpus poisoning, indirect injection, side-channel leakage. |
| LLM Chatbot / Shadow AI | None. Tool access via unvetted OAuth integrations. Query context opaque. | User-initiated queries logged nowhere. DLP/CASB cannot see conversational egress. | Highest. IBM found shadow-AI breaches compromised PII in 65% of cases vs. 53% global average. |
| Traditional BI Layer (Looker, Tableau, Power BI) | Mature RBAC + RLS. Enforced at query time. | Audit logs queryable. Gold standard for SOX/GDPR for human users. | Low for human users. Agent access often bypasses RLS via API. |
| Governed Semantic Layer (Colrows) | RBAC + ABAC + RLS + CLS enforced once at compile time. User identity propagated. | Compile-time execution logs every decision with full context. Tamper-evident. Replayable. | Reduced significantly. Malformed or unauthorized intents fail before data is read. |
The throughline is clear: governance must be enforced before the model is invoked. Runtime filtering (traditional BI, post-hoc masking) leaves a window where an agent can see data before policy is applied. Compile-time enforcement closes that window entirely. We covered the broader governance pattern in How to Govern AI Agents That Query Enterprise Data.
Why This Matters: The IBM Numbers
IBM's 2025 Cost of a Data Breach Report surveyed 600+ organizations:
97% of AI-related breaches lacked AI access controls. This is the core finding. Organizations that suffered AI breaches had done little to nothing to govern agent access.
Shadow AI added $670,000 to average breach cost. Compare: global average breach cost was $4.44 million. With high levels of shadow AI, it jumped to $5.11 million. The delta is significant and repeatable. The economic argument is reinforced in our analysis of the token cost hidden tax.
Only 34% of organizations with an AI governance policy audit for unsanctioned AI usage. Policies exist. They are not enforced.
60% of AI security incidents led to compromised data. 31% led to operational disruption. These are not edge cases.
Conversely, organizations using AI/automation extensively in security saved $1.9 million per breach and resolved breaches 80 days faster. The path forward is not "shut down all AI." It is "govern all AI through a single control point."
A governed semantic layer is that control point.
How Colrows Differs: Compile-Time Governance vs. Runtime Filtering
This is the critical distinction.
Traditional BI layers resolve governance at query time. Looker compiles your dashboard, and at the moment you run it, RLS rules are applied to the result set. Power BI creates a semantic model; when you slice it, RLS is evaluated. This works well for humans using dashboards.
But it breaks for autonomous agents. Why? Because the agent submits a natural-language request. The system must:
- Interpret the request (did the agent ask for revenue or costs?)
- Generate a query (which tables, which joins?)
- Execute the query (and now apply RLS)
- Return results
- Pass results to the model
If the agent gets the data at step 4, and only then is security applied, the model has already "seen" it. Masking a result set is too late if the model can reason backward from the masked output.
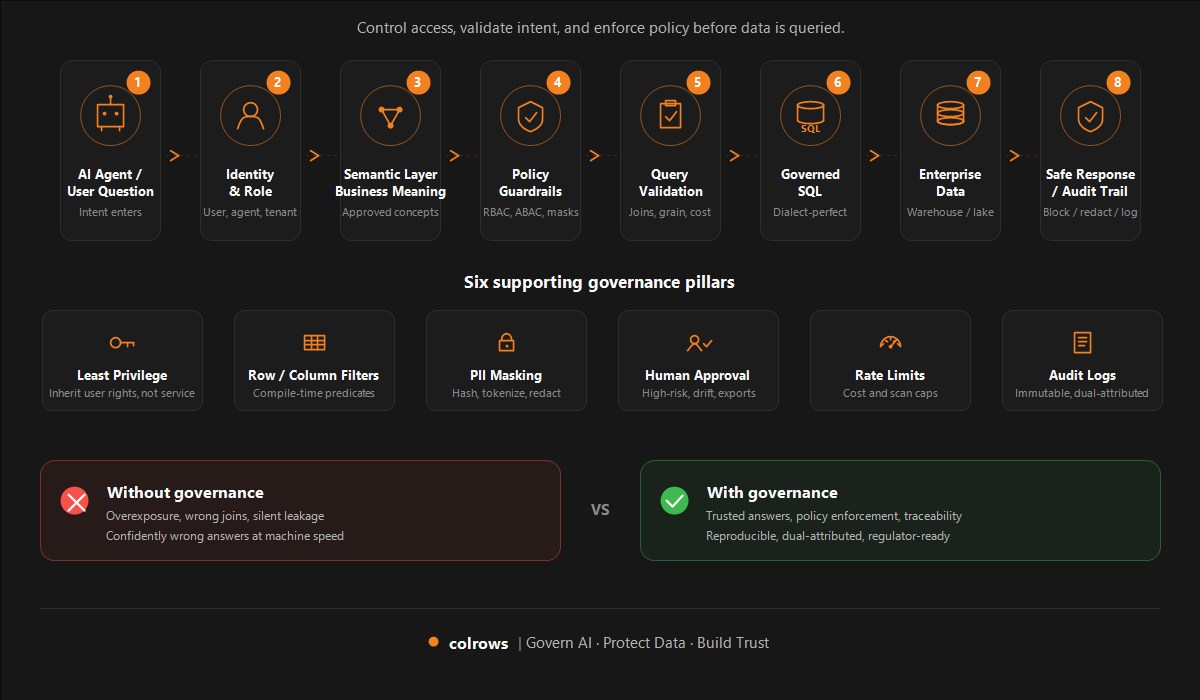
Colrows operates at compile time. Your schema is compiled into a typed semantic graph. When an agent submits intent ("show me Q4 revenue by customer segment"), the system:
- Parses the intent
- Resolves it against the semantic graph
- Checks user identity and policy before producing a query
- Compiles the final SQL with row-level filters baked in
- Executes the compliant query
- Returns results
The authorization checkpoint happens before the SQL is generated. If the user lacks permission to see customer-segment detail, the system does not produce a query at all. It returns an error. The model never gets to hallucinate its way around the boundary. We described the underlying mechanism in What Is a Semantic Compiler? Deterministic SQL for AI.
This is the difference:
Presentation-time governance: Filter the results after retrieval. Agent sees intermediate data. Security is a mask.
Compile-time governance: Filter the query before execution. Agent never sees unauthorized rows. Security is structural.
For a CISO, this matters enormously. Compile-time governance means the compliance boundary is no longer "did we redact the output?" It is "was the query itself authorized?" The latter is auditable, deterministic, and reproducible.
Fix the Context. Not the Model.
Regulatory Alignment and Compliance
Mandatory Frameworks
NIST AI RMF + GenAI Profile (US, de facto global baseline): Twelve risk categories including prompt injection, data leakage, and supply-chain vulnerabilities. The GenAI Profile (AI 600-1, July 2024) is the first NIST guidance built for generative AI specifically.
ISO/IEC 42001:2023 (certifiable AI management system): The only auditable AI governance standard. Clauses 4-10 parallel ISO 27001; Annex D guides integration. Now a procurement signal. Microsoft and Synthesia are certified. Expect supply-chain pressure starting 2026.
GDPR (data subject rights): Right to erasure (Article 17), access (Article 15), rectification (Article 16), and restriction of automated decision-making (Article 22). LLM systems encode data in parameters, making true erasure hard; a governed semantic layer backed by a clean source-of-truth database is the practical solution.
HIPAA / SOX / SOC 2 / PCI-DSS: Every healthcare AI access must be tracked (HIPAA). Financial metrics must be auditable and reproducible (SOX). Access controls and change management are table stakes. Our deep dive on this is in Auditable SQL: How Conversational Analytics Earns Its Place in BFSI.
EU AI Act / DORA: Explainability, audit trails, and data governance by design are now legal requirements, not nice-to-haves.
Colrows' Compliance Advantage
A governed semantic layer generates audit trails as a byproduct of compilation, not as a bolt-on. Every query logged with full context: user identity, intent submitted, policy checked, rows accessed, reason for access. This is tamper-evident by design and replayable for auditors.
For ISO/IEC 42001 compliance, you can demonstrate:
- Clause 5.1 (Leadership commitment to risk management): Colrows enforces policy at compile time, making governance the default.
- Clause 6.1 (Risk assessment): Every query is logged; threat surface is visible and manageable.
- Clause 7.5 (Governance and risk management): Policy travels with the metric; consistent across all tools and agents.
- Clause 8.2 (Assessment and governance of AI outputs): Lineage from source data to metric to output is explicit and auditable.
Essential Controls: Building Secure Semantic-Layer Deployments
Control 1: Identity Pass-Through (Not Service Accounts)
The service-account identity trap destroys audit trails and causes massive compliance failures.
Traditional integrations query the database as a single, over-privileged service account. The database logs do not show which user requested the data. RLS cannot be applied. Auditors see "did the service account access this table?" (yes), not "did the human behind this request have permission?" (unknown).
Colrows natively propagates the end-user's identity through to underlying row-level filters. Every query carries the human user's context. If row-level security is active, it applies per-user per-request. If an agent experiences a scope violation or an indirect prompt injection attack, the exploit fails at compilation. The model cannot hallucinate its way into unauthorized rows. The pattern is detailed in Fine-Grained Data Access Control: Precision Security for the AI Era.
Control 2: Compile-Time Policy Enforcement
Do not apply security at query time or result time. Apply it at plan time. This means:
- Policy is checked before SQL is generated
- Unauthorized intent fails with an explicit error (not a masked result)
- Auditors see "why was this query blocked?" not "what rows were hidden?"
- The semantic layer itself documents the governance rules, making them testable and versionable
Control 3: Governed Vector Store Partitioning
If you are using vector stores (for hybrid search or semantic similarity):
- Encrypt at rest with keys you control (BYOK)
- Partition strictly by tenant (no shared embeddings across users)
- Apply the same RLS rules to embedding retrieval as to raw data
- Treat embeddings as plaintext for security purposes (assume they will be inverted)
- Scan ingestion pipelines for malicious/poisoned documents before indexing
Control 4: Compliance-Grade Audit Logging
Log with full provenance: every agent interaction, retrieval step, policy decision, and data access. Make logs queryable and tamper-evident. Support replay of any decision for auditors.
A Colrows query log includes: user identity, agent ID, intent submitted, semantic graph path traversed, policy active at decision time, rows returned, timestamp, hash chain. Auditors can replay any query and confirm it was authorized.
Control 5: Supply-Chain Hardening
Your vulnerability is only as strong as your weakest dependency.
- Use Safetensors instead of pickle (.pth/.pkl allow arbitrary code execution on load)
- Maintain an ML Bill of Materials (ML-BOM) for every model and MCP server you use
- Scan dependencies for known vulnerabilities
- Vet third-party MCP servers before deployment (Koi Security found 341 malicious ClawHub skills in February 2026)
- Pin and cryptographically sign all builds
Control 6: Multi-Tenant Isolation (If Applicable)
If you operate Colrows or similar layers as a multi-tenant platform:
- Enforce strict logical partitioning at every layer (semantic graph, vector store, cache, inference)
- Use per-tenant keys and encryption
- Apply per-user cache isolation or accept side-channel risk and compensate with monitoring
- Test isolation regularly with red-team exercises
Implementation Roadmap
Phase 1: Baseline and Inventory (0-30 days)
Build an AI inventory mapping every model, agent, and RAG system to the data it touches. Discover shadow AI via network monitoring, CASB analysis, and identity logs. Classify data feeding any AI system.
Threshold to advance: You can answer "which AI systems touch regulated data and who can access them?" with certainty.
Phase 2: Centralize Governance (30-90 days)
Route all analytics and agent queries through a governed semantic layer. Enforce RBAC + ABAC + RLS + CLS once at compilation, with user identity pass-through. Stand up an MCP zero-trust gateway issuing short-lived per-agent tokens. Deploy audit logging with full provenance. See our pattern in From Ambient Memory to Deterministic Autonomy.
Threshold to advance: Every agent query is attributable to a human user and policy-checked before execution.
Phase 3: Harden Against AI-Native Threats (60-120 days)
Add input/output filtering and prompt partitioning. Partition and encrypt vector stores. Implement KV-cache isolation for multi-tenant environments. Adopt Safetensors + ML-BOM + dependency scanning. Run red-team exercises testing for prompt injection, corpus poisoning, and scope violations.
Threshold to advance: You have evidence (not assumption) from adversarial tests that controls hold.
Phase 4: Certify and Prove (Ongoing)
Map controls to NIST AI RMF + GenAI Profile. Pursue ISO/IEC 42001 certification. Implement confidential computing / BYOK for sovereignty-sensitive workloads. Operationalize GDPR erasure at the data tier and RAG indexes.
Threshold: You can replay any AI decision and produce an audit-defensible trail on demand.
What Regulators and Auditors Actually Want
For ISO/IEC 42001: Evidence of AI risk assessment, documented controls, and regular testing. Colrows' compliance-grade audit logs satisfy this directly.
For SOX: Auditable, reproducible financial metrics with full lineage. Colrows logs every metric calculation with user context and policy state.
For GDPR: Proof that data subjects can exercise rights to access, rectification, and erasure. A governed semantic layer with data as the source of truth (not ML parameters) is the practical answer.
For HIPAA: Every PHI access tracked and justified. Compile-time enforcement means every query accessing PHI must pass policy checks; the logs prove it. We dig deeper into this in Conversational Analytics for Clinical Data: A HIPAA-Aware Playbook.
For the EU AI Act: High-risk AI systems require explainability and human oversight. A compile-time semantic layer provides lineage (explainability) and a natural checkpoint for human approval (oversight).
Red Flags: When Your Current Setup Is Not Secure
- You cannot answer "who accessed what data and why?" for a given AI query
- Your AI agents run as service accounts, not end-user identities
- Vector stores are not encrypted or partitioned by tenant
- You have no audit trail of agent decisions
- Governance rules live in code (not versioned, not testable, not declarative)
- You are indexing external documents without classification or poisoning detection
- Your RLS/ABAC rules are applied at presentation time, not query time
- You have no red-team testing for prompt injection or scope violations
- Your supply chain (models, MCP servers, dependencies) is not scanned for vulnerabilities
Any of these is a material compliance and breach risk. A governed semantic layer closes all of them.
The Bottom Line
Ad-hoc RAG kills enterprises because it replaces governed data flows with invisible, ungoverned flows. An autonomous semantic layer restores visibility and control.
The security case is not abstract. IBM data shows $670,000 in additional breach cost per shadow-AI deployment. Regulatory frameworks (NIST, ISO, GDPR, HIPAA, SOX, EU AI Act) now mandate auditability and governance. Auditors will ask one question: Can you prove every AI query was authorized?
A governed semantic layer answers yes. Ad-hoc RAG answers no.
For deeper context, see The ROI of a Company Brain, From Ambient Memory to Deterministic Autonomy, and Governance as Code vs Governance as Semantics.
Next Steps
If your organization is running autonomous agents on production data without a unified governance layer, you are operating at material risk. Your CISO knows this. Your auditors will surface it.
Audit your agent surface area now. Test Colrows in a private VPC environment to enforce compile-time zero-trust governance. We specialize in mapping complex transactional schemas and wiring them to agents with full audit and compliance traceability.
Your first audit is free. Your first schema mapping takes one week. Your first compliant agent deployment takes 30 days.
Frequently asked questions
How much does shadow AI add to the cost of a data breach?
IBM's 2025 Cost of a Data Breach Report found that organizations with high levels of shadow AI faced an average breach cost of $5.11 million versus the global average of $4.44 million. The delta is $670,000 per breach. 97% of organizations suffering AI-related breaches lacked explicit AI access controls.
What is compile-time governance?
Compile-time governance evaluates authorization before SQL is generated. If an agent's intent falls outside the policy, compilation fails with an explicit error. The model never sees unauthorized data. This is structurally different from runtime filtering (traditional BI tools), where the agent receives the result and security is applied as a mask after the fact.
How do semantic layers reduce breach risk?
A semantic layer routes every agent interaction through a unified compiler where RBAC, ABAC, row-level security, and column-level masking are applied at compile time. This collapses fragmented governance across vector stores, agents, and BI tools into a single inspectable control channel. It also generates tamper-evident audit logs as a byproduct of execution.
What is embedding inversion and why does it matter?
Embedding inversion is a class of attack (demonstrated at ACL 2024) that recovers a meaningful share of original text from stored vector embeddings without querying the embedding model. A breached vector store is functionally equivalent to a plaintext document breach. CISOs should encrypt vector stores at rest with controlled keys and treat embeddings as plaintext for security purposes.
What is corpus poisoning?
Corpus poisoning is an attack where adversaries inject a small number of malicious documents into a RAG knowledge base to dominate retrieval. PoisonedRAG (USENIX Security 2025) showed that five malicious documents per target question yield a 90% attack success rate, even in knowledge bases of millions of documents. Attack vectors include email attachments, resumes, support tickets, and crafted SharePoint documents.
What is the EchoLeak vulnerability?
EchoLeak (CVE-2025-32711) is a CVSS 9.3 zero-click vulnerability in Microsoft 365 Copilot disclosed by Aim Labs in June 2025. A crafted email could trigger Copilot to exfiltrate data from OneDrive, SharePoint, Teams, and email without any user interaction. It bypassed four separate defenses. The class of attack (LLM scope violation) cannot be patched away; it requires architectural defense.
How does compile-time governance map to ISO 42001 compliance?
ISO/IEC 42001:2023 is the only auditable AI management system standard. A compile-time semantic layer satisfies multiple clauses directly: Clause 5.1 (Leadership commitment) via default-enforced policy, Clause 6.1 (Risk assessment) via complete query logging, Clause 7.5 (Governance) via policy travelling with metric definitions, and Clause 8.2 (Output governance) via explicit, auditable lineage.
What is the service-account identity trap?
Traditional integrations query the database as a single, over-privileged service account. Database logs show only that the service account accessed a table, not which human user requested it. Row-level security cannot be applied per-user, audit trails are useless, and compliance fails. Identity pass-through (carrying the end-user identity through to row-level filters) closes this gap.