| Cost Driver | Legacy Semantic Layers | Colrows Autonomous Compiler |
|---|---|---|
| Token Usage | Redundant / Unoptimized | Optimized / Deterministic |
| Logic Processing | High-token Guessing | Zero-token Metric Resolution |
| Governance Cost | High (Human-in-the-loop) | Zero (Compiler-driven) |
| Scaling Model | Unpredictable (Seat-based) | Predictable (Schema-tier) |
| Operational Impact | Profit margin erosion | Maximized AI ROI |
| Accuracy | 60-70% average | 98-100% on covered queries |
TL;DR
- Dumping raw database schemas into a frontier LLM on every query is an economic failure. Per-query input cost scales linearly with schema size. Frontier models solve fewer than 27% of enterprise text-to-SQL tasks on complex schemas. The only viable solution is an autonomous semantic layer that holds token costs flat and drives accuracy to near 100%.
- Enterprise GenAI bills are exploding into the tens of millions per month. Agentic AI consumes 5 to 30 times more tokens per task than a chatbot. A single healthcare enterprise hit $6 million in unexpected annual token cost over six months.
- Semantic-layer vendors price fundamentally differently from per-token APIs. dbt Cloud charges $100 per seat. AtScale starts at $2,500 per month. ThoughtSpot ranges $25 to $50 per user. Colrows compiles rather than retrieves. Token cost becomes predictable. Governance happens at compile time, not runtime.
The Hidden Tax: Why Your AI Budget Is Exploding
You signed up for frontier LLMs at $5 to $30 per million tokens. The unit economics looked good.
Then you put agents into production.
Now your bill is $2.4 million per year and climbing. You are not sure why.
The diagnosis: you are paying a hidden tax on every single query. The tax is schema. The tax is context. The tax is agentic loops. The way you have architected your data layer makes the tax non-negotiable.
This is the same pattern we documented in our analysis of the hidden cost of building your own data access layer. The cost shows up below the waterline. By the time finance sees it, the bill is already shaped.
The Math: Raw Schema Is Expensive
Why Raw Schema Blows Up Token Cost
An enterprise data warehouse has a real schema, not a textbook schema.
The academic benchmarks (Spider, BIRD) assume 5 to 7 tables per database. Real enterprise data warehouses average 450 tables, with some exceeding 12,700 tables. The median enterprise schema carries 435 columns per table.
A typical enterprise database schema serialized as DDL takes 50,000 tokens of metadata alone.
When you ask an agent a question, here is what happens with the raw schema approach:
- Agent receives the user question
- LLM loads the entire 50K token schema into context
- LLM generates SQL using inferred join paths
- Agent executes the SQL
- If the query fails or returns nonsense, the loop repeats (multiply tokens by 3 to 5)
Cost per query: 50,000 tokens input (the schema) plus query token cost plus output token cost.
That is $0.25 per query on GPT-5.5 just for schema tokens. Scale to 100,000 queries per month and you are at $25,000 per month in schema-input cost alone. Almost all of that cost is redundant. Each query touches only a handful of tables.
The agent receives the question. The LLM resolves user intent to a semantic definition. The semantic layer compiles that into dialect-perfect SQL. The agent executes. If the compile fails, the error is loud and catchable. No raw schema ever enters the LLM context.
The schema is compiled once, upfront. The LLM never sees it again. We covered the compiler pattern in detail in What Is a Semantic Compiler? Deterministic SQL for AI, and how this compile-time design differs from a traditional runtime semantic layer in semantic layer vs. semantic execution layer.
The Accuracy Problem: Why Raw RAG Fails on Enterprise Data
Token cost is not the only problem with raw-schema RAG. Accuracy is worse.
Academic benchmarks mislead. Spider 1.0 assumes small, well-designed schemas with clear naming. Real enterprises do not. The tables have cryptic names (T001, SRC_CUST_ACCT_BAL). Columns have inconsistent types. Joins are ambiguous.
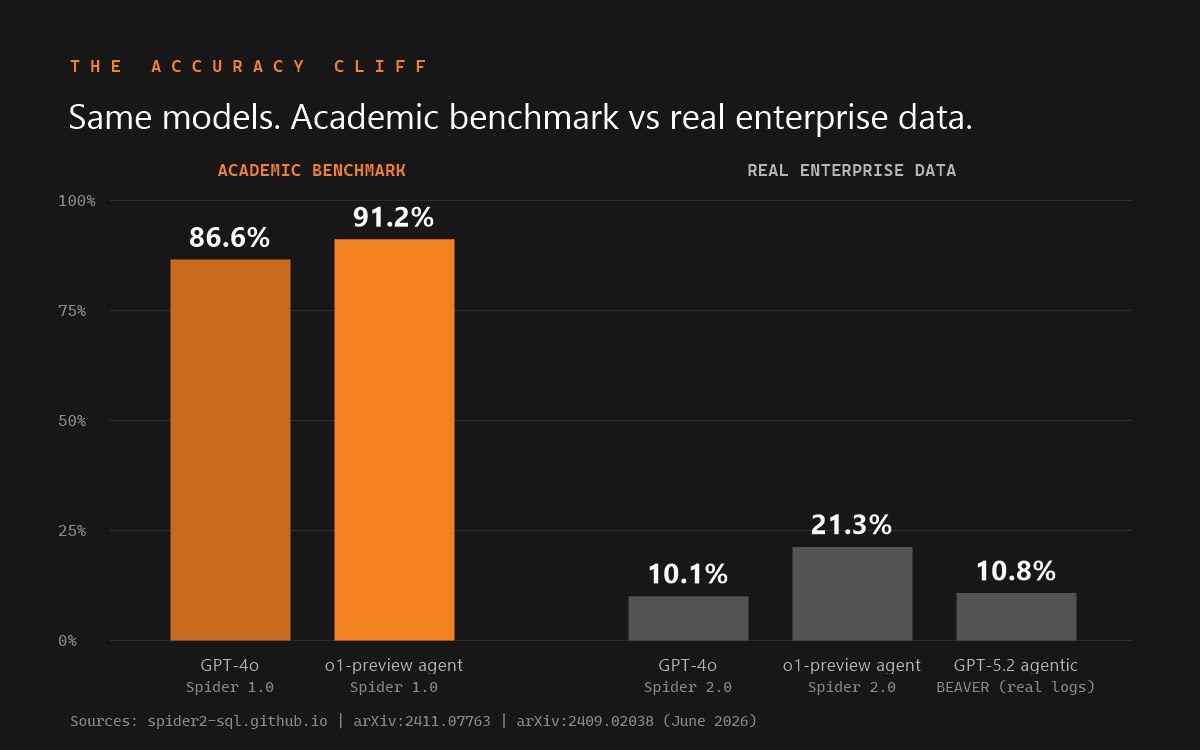
On Spider 1.0, GPT-4o hits 86.6% accuracy. On Spider 2.0 (enterprise-grade schemas), it drops to 10.1%. That is a 93% accuracy collapse on the same model. We broke this down further in The Text-to-SQL Accuracy Cliff: 91% on Benchmarks, 21% in Production.
Frontier models struggle not because they are dumb but because raw schema creates what researchers call "lost in the middle". When relevant information sits beyond the middle of the context window, accuracy falls 20 to 47%. A 32K token context can drop to 50% of its short-context performance.
Semantic layers eliminate this problem. The LLM does not see the raw schema. It sees a curated list of business metrics and dimensions. It cannot hallucinate a join path because there is no raw schema to hallucinate from. The structural fix is detailed in our guide on how to prevent AI hallucinations on enterprise data.
Real-world semantic layer benchmarks:
| Approach | Accuracy |
|---|---|
| Text-to-SQL (GPT-5.3-Codex) | 84.1% |
| Semantic Layer (GPT-5.3-Codex) | 100% |
| Text-to-SQL (Sonnet 4.6) | 90.0% |
| Semantic Layer (Sonnet 4.6) | 98.2% |
Source: dbt Labs 2026 benchmark (ACME Insurance, 11 questions, 20 runs each). The semantic layer also forces a hard contract: if a query falls outside governed definitions, the layer returns an error. Text-to-SQL returns a confident wrong answer. In BFSI and pharma, that confident wrong answer is the one that breaks compliance. See Auditable SQL: How Conversational Analytics Earns Its Place in BFSI for the regulatory implications.
LLM Pricing as of June 2026
Before you can calculate your hidden tax, you need to know what you are paying per token.
Frontier models have collapsed in price. But agentic workloads have exploded in token consumption, so total bills are climbing.
The Major Providers
OpenAI (GPT-5.x family):
- GPT-5.5 (flagship): $5.00 input / $30.00 output per 1M tokens
- GPT-5.4: $2.50 / $15.00
- GPT-5.4 Nano (budget): $0.20 / $1.25
- Batch API: 50% off; Prompt caching: 90% off cached input
- Context length surcharge: doubles price above 272K input tokens
Anthropic (Claude):
- Opus 4.8: $5.00 / $25.00 per 1M tokens (67% price drop from Opus 4.1)
- Sonnet 4.6: $3.00 / $15.00; Haiku 4.5: $1.00 / $5.00
- Output is 5x input across the line
- 1M token context: no surcharge; Prompt caching: 90% off
Google Gemini:
- Gemini 3.5 Flash: $1.50 / $9.00 per 1M tokens (cheapest fast model)
- Gemini 3.1 Pro: $2.00 / $12.00 (up to 200K context); doubles above 200K
- Gemini 2.5 Flash-Lite: $0.10 / $0.40 (ultra-budget)
- Context caching: up to 90% off repeated prompts
Key insight: List prices have fallen 10x per unit. But Jevons paradox: cheaper tokens = more queries = more agentic loops = total bill climbs. Gartner reports agentic workloads consume 5 to 30 times more tokens per task than a standard chatbot.
The Four-Layer Cost Model
Total cost of a natural-language-to-data query breaks into four layers. Raw-schema RAG is expensive in three of them.
Layer 1. Input Token Cost
Formula: (fixed prompt + metadata + retrieved context + question) x input rate. In raw-schema RAG, metadata dominates and scales linearly with schema size.
- 100-table, 870-column schema: 50K tokens of metadata
- Cost per query on GPT-5.5: $0.25 just for the schema
- 100,000 queries per month: $25,000 per month in redundant schema tokens
A semantic layer eliminates this. The compiled semantic definition is stable and cacheable. The LLM never loads the raw schema. Cost reduction: 70 to 95%.
Layer 2. Output Token Cost
Output is 4 to 8x more expensive than input. No caching scheme discounts output. You pay full price every time. Where to optimize: keep generated output short. Enforce structured output (JSON, not prose). Let the semantic layer handle SQL generation, not the LLM. Cost reduction: 20 to 40%.
Layer 3. Retry and Agentic Multiplier
A failed query fires again. A self-correcting agent loops. A multi-step workflow chains LLM calls. Agentic pipelines consume 5 to 30 times the tokens of a single question-answer pair.
One benchmark measured an agentic pipeline at 320.8K tokens and 251 seconds per query. A tool-integrated baseline consumed 2.83K tokens and 45 seconds. The agentic approach burned 113x more tokens to solve the same task.
Where raw RAG breaks: Silent failures trigger silent retries. A hallucinated metric causes an invalid SQL statement. The retry loops invisibly. You wake up with a $2.4M annual bill.
Where semantic layers win: Compile-time errors are loud. Invalid metrics are caught upfront. The agent never generates bad SQL. Cost reduction: 10 to 500x depending on failure rate.
Layer 4. Business Cost of Wrong Answers
This is not a token cost. It is worse. A raw-schema RAG system returns a confident wrong answer. The answer looks correct. The model is very sure. The number ends up in a board deck.
That is a metric hallucination. Your CFO and your AI agent just computed "revenue" two different ways. One number is wrong. Nobody catches it until an auditor or a regulator asks. We covered the organizational dynamics in Why BI Metrics Do Not Match Across Dashboards.
A semantic layer prevents this by making all metric definitions deterministic. The layer either knows how to compute a metric or it returns an error. Never a hallucination.
Do not pay for your AI model's hallucinations. Pay for deterministic, accurate, and optimized SQL generation. Fix the Context. Not the Model.
Real-World Enterprise Bills
The numbers are starting to scare executives.
Deloitte (Tech Trends 2026): "Some enterprises are starting to see monthly bills for AI use in the tens of millions of dollars. The biggest cost contributor is agentic AI, which involves continuous inference."
Gartner (March 2026): Agentic models require between 5 and 30 times more tokens per task than a standard GenAI chatbot. It is not just that the system is doing more queries. Every single query costs five to 30 times more tokens.
The Semantic Layer: What It Actually Does
A semantic layer is not a database. It is not a cache. It is not a traditional BI tool.
A semantic layer is a compiler. It sits between agents and data warehouses. It intercepts intent and compiles it into deterministic SQL. The architectural pattern is detailed in The Semantic Control Plane for Data and AI.
How it works:
- Agent asks: "How many active customers do we have?"
- Semantic layer resolves: Active customer = someone with non-zero subscription balance as of query date (compile time, deterministic)
- Semantic layer compiles: Generates the exact SQL with full join paths and governance
- Warehouse executes: Returns the answer
- Agent gets: A number it can trust
Compare to raw RAG:
- Agent asks: "How many active customers do we have?"
- Raw RAG loads 50K token schema
- LLM guesses: Active customer = someone who logged in in the last 30 days (wrong join path, silent hallucination)
- Warehouse executes: Returns a different number
- Agent gets: A number that is confidently wrong
The semantic layer makes three guarantees: no silent hallucinations, predictable token cost, and governed access. We unpacked the agent-specific implications in Semantics for Enterprise AI Agents. For the full architecture details, see the Colrows semantic compiler architecture guide.
The Cost Calculation: Worked Examples
Scenario 1. Raw-Schema RAG (What Most Enterprises Do Today)
Setup: 100 tables, 870 columns, 50K token DDL, 100K queries/month on GPT-5.5 ($5 input / $30 output), 15% retry rate.
| Component | Tokens | Cost |
|---|---|---|
| Schema input (50K x 100K queries) | 5B | $25,000/mo |
| Question input (avg 200 tokens x 100K) | 20M | $100/mo |
| Output (avg 500 tokens x 100K) | 50M | $1,500/mo |
| Retries (15% x all above) | 777M | $23,310/mo |
| Total | 5.85B | $50,000/mo |
Annual cost: $600,000. A larger enterprise (500+ tables) pays $3M per year on raw schema tokens alone.
Scenario 2. Semantic Layer + Retrieval
Same enterprise, same volume, with semantic layer and prompt caching. Schema cached (90% off). Retrieval (only relevant tables, avg 5 tables, 5K tokens).
| Component | Tokens | Cost |
|---|---|---|
| Schema input cached (50K, paid once) | 50K | $0.25/mo |
| Question input (avg 200 tokens x 100K) | 20M | $100/mo |
| Retrieval input (5K tokens x 100K) | 500M | $2,500/mo |
| Output (avg 300 tokens x 100K) | 30M | $900/mo |
| Retries (2% failure rate) | 110M | $660/mo |
| Total | 561M | $4,160/mo |
Annual cost: $50,000. Savings: 92% of the raw-RAG bill.
Scenario 3. Compile-Time Semantic Layer (Colrows-style)
Same enterprise, same volume. Schema compiled, not sent to LLM. LLM resolves intent to metrics/dimensions only (avg 50 tokens). Semantic layer generates SQL deterministically.
| Component | Tokens | Cost |
|---|---|---|
| Intent resolution (50 tokens x 100K) | 5M | $25/mo |
| Output (metric result, avg 100 tokens) | 10M | $300/mo |
| Retries (0% - compile errors are loud) | 0 | $0/mo |
| Semantic layer platform fee | - | $5,000/mo |
| Total | 15M | $5,325/mo |
Annual cost: $64,000. The platform fee is fixed. Add 1M more queries, cost stays at $5,325/mo. At 1M queries per month, Scenario 1 costs $500,000/mo. Scenario 3 costs $5,325/mo. The semantic layer pays for itself after month one and saves $5.94M per year.
Semantic-Layer Vendor Landscape
There are two categories of semantic-layer vendors. Understand the difference before you buy. We covered this in depth in The Semantic Layer Buyer's Guide for 2026.
Presentation-Time (dbt, Looker, Cube)
Metrics are defined once, then cached. When a user runs a dashboard or a query, the system looks up the metric definition and generates SQL. dbt Cloud: $100 per seat per month, plus $0.01 per model build overage. Enterprise: $200 to $400 per seat per month. Median contract: $26,460 per year.
Pros: Open standard, BI-tool-portable, integrated with data workflows. Cons: Manual metric definition. Governance is stored in code. Agents cannot directly leverage the layer without custom integration. See LookML vs dbt Semantic Layer vs a Compiled Semantic Layer for the architectural comparison.
Compile-Time (Colrows, Palantir, Cortex/Genie)
When an agent asks a question, the semantic layer intercepts it, resolves the intent to a metric or dimension, compiles it into deterministic SQL, and returns the result. The schema is hidden from the LLM.
Pros: Governance is enforced by the system, not stored in code. Schema changes do not break agent queries. Token cost remains flat. Audit trails are automatic. Cons: Requires upfront data modeling.
The warehouse-native options (Snowflake Cortex Analyst, Databricks Genie) are bundled into platform consumption but scoped to that platform. We analyzed the limitation in Why Snowflake and Databricks Can't Be Your Enterprise Semantic Layer.
Recommendation: The Four-Stage Optimization Path
Do not attempt to move all your queries to a semantic layer overnight. Migrate in stages.
Stage 1. Instrument (Week 1 to 4)
Enable fine-grained token logging. Segment tokens by category: schema input, question input, output, retries. Calculate P95 hourly throughput. Measure accuracy on a labeled test set of 20 to 50 business questions. Estimate annual bill based on current trajectory.
If schema or metadata is more than 40% of input tokens, skip to Stage 2 immediately.
Stage 2. Kill Redundant Schema Tokens (Week 4 to 8)
Turn on prompt caching for stable schema prefixes (cuts input cost 90%). Add a retrieval or schema-linking step so each query loads only relevant tables. Aim for schema input less than 2K tokens per query.
Cost reduction: From $50,000/mo to $5,000/mo for a mid-size enterprise. This stage is pure engineering leverage. You do not buy any tools. You just cut waste.
Stage 3. Add a Semantic Layer for Critical Queries (Month 2 to 6)
Not all queries need a semantic layer. But board queries. Regulatory queries. KPI queries. Finance queries. These must be deterministic.
Decision rule: Use the semantic layer when a wrong answer has real cost. Fall back to retrieval text-to-SQL for ad hoc exploration. See Semantic Layer vs Text-to-SQL: When Each Wins for the full decision framework.
- dbt-native: dbt Semantic Layer (MetricFlow). $100/seat/mo plus overages.
- Looker/Power BI/OLAP shop: AtScale. Starts at $2,500/month.
- Cross-warehouse compile-time governance: Colrows or Palantir. Six figures.
- Single-warehouse (Snowflake or Databricks): Cortex Analyst or Genie. Bundled.
Expected outcome: 98 to 100% accuracy on governed queries. Zero silent hallucinations. Full audit trail. The governance pattern is detailed in How to Add Governance to AI Agents: A 7-Step Checklist.
Stage 4. Right-Size Cloud Commitments (Ongoing)
For Azure or OpenAI volume: move from pay-as-you-go to Provisioned Throughput Units. Breakeven approximately 150 to 200M tokens per month at 50%+ utilization. Savings 30 to 50% off list price. Reserved 1-year capacity: another 15 to 30% off.
Route by value. Cheapest capable model (Haiku/Flash-Lite/Nano) for classification, routing, simple extraction. Frontier models (Opus/GPT-5/Pro) only where answer quality moves revenue, retention, or compliance.
Use Batch API for non-interactive workloads. 50% discount. Negotiate volume discounts. Above $250K annual spend, you qualify for 15 to 30% off list prices.
The Colrows Approach: Deterministic Compilation at Scale
We built Colrows specifically to solve this problem for enterprises running autonomous AI.
The traditional approach (presentation-time): You define metrics in code. A BI tool stores them. When an agent queries, the BI tool looks up the definition and generates SQL. This works for dashboards with 10 queries per day. It breaks when an agent fires 100 queries per second.
The Colrows approach (compile-time): The agent asks a question. Colrows intercepts it and compiles the intent directly into SQL at query time. The schema is hidden from the agent. The LLM never sees raw database complexity. Governance is enforced by the semantic layer, not stored in code.
Why this matters:
- Token cost is predictable. The LLM never loads raw schema. Input tokens are proportional to the question, not the warehouse.
- Governance is instant. RBAC, ABAC, row-column masking, and audit trails are enforced at compile time.
- Schema drift is a non-event. Add 100 tables. Change 50 column definitions. The semantic layer adapts instantly via autonomous maintenance agents.
- Audit trails are automatic. Every query is compiled. Every compile is logged.
- Accuracy is 100% on covered queries. No hallucinations. No silent failures.
Colrows supports 16+ SQL dialects (Postgres, Snowflake, Databricks, BigQuery, Redshift), 8+ LLMs, and autonomous schema-drift detection. Pricing is custom. The math is simple: if you are spending $600,000 per year on raw-schema RAG tokens, a semantic layer pays for itself in month one.
The Bottom Line: Fix Your Data Foundation, Not Your Model
The current enterprise GenAI narrative is backward. Every startup and vendor is chasing better models, bigger context windows, cheaper tokens.
But the real problem is not the model. It is the data layer underneath.
A 100-table warehouse with 50K tokens of metadata is not a data foundation. It is a cost center. It is a hallucination factory. It is a compliance risk.
A semantic layer is not a feature. It is infrastructure. It is the foundation you should have built before you plugged in any AI.
If you are hitting accuracy walls with autonomous AI. If your token bills are climbing unexpectedly. If your metrics do not reconcile between agents and dashboards. The answer is not a better LLM. The answer is a semantic layer.
For deeper context, see The Semantic Layer Buyer's Guide for 2026, RAG vs Semantic Layer: Architecture, Cost, and When You Need Both, and The Build vs. Buy Decision for Enterprise Semantic Layers.
Stop the Token Bleed
Every wasted token is a tax on your profit margin. Every hallucination is a compliance risk. Every agentic loop is an exponential cost multiplier.
Book a technical architecture review with our team. We will audit your current data foundation, estimate your projected operational efficiency gains, and show you exactly where Colrows closes the token-cost gap.
No pressure. No fluff. Just the math that matters to your CFO.
Frequently asked questions
What is a semantic layer, and why does it save money?
A semantic layer is a compiler that intercepts agent intent and compiles it into deterministic SQL without sending the raw schema to the LLM. It saves money because input token cost stops scaling with schema size and accuracy hits 98-100%, eliminating retry loops that multiply token consumption by 5-30x.
How much does a raw-schema RAG query cost vs a semantic layer?
A 50K-token enterprise schema costs $0.25 per query on GPT-5.5 just for the schema input. At 100,000 queries per month, that is $25,000 in redundant schema tokens. A semantic layer collapses input to ~50 tokens per query, so the per-query token cost drops by 99% and total annual cost drops from ~$600K to ~$50K-$64K.
Why do enterprise GenAI bills explode with agentic AI?
Gartner reports that agentic models consume 5-30x more tokens per task than standard chatbots. Every retry, self-correction loop, and multi-step workflow multiplies the per-question cost. One healthcare enterprise hit $6M in unexpected annual token cost over six months due to silent agentic loops.
What is prompt caching, and how much does it save?
Prompt caching lets you cache a stable prompt prefix (like a schema) and pay only 10% of the input rate for cached reads. OpenAI, Anthropic, and Google all offer ~90% off cached input tokens. This is the cheapest retrofit for raw-schema RAG, but it only discounts input - output costs and retry costs are unchanged.
How accurate is text-to-SQL on enterprise databases?
On academic Spider 1.0, GPT-4o hits 86.6%. On Spider 2.0 (real enterprise schemas), it collapses to 10.1% - a 93% accuracy drop. Real-world text-to-SQL averages 60-70% accuracy. A semantic layer pushes accuracy to 98-100% on covered queries by eliminating hallucinated join paths and metric definitions.
At what query volume does a semantic layer pay for itself?
For a mid-size enterprise (100 tables, 100K queries/month), a compile-time semantic layer pays for itself in month 1 vs raw-schema RAG. At 1M queries/month, the semantic layer saves $5.94M per year because cost stays flat at ~$64K/year while raw RAG scales to $500K/month.
What is the difference between compile-time and presentation-time semantic layers?
Presentation-time layers (dbt, Looker, Cube) store metric definitions in code that a BI tool looks up at query time. They work for dashboards but break for agents firing hundreds of queries per second. Compile-time layers (Colrows, Palantir, warehouse-native Cortex/Genie) compile intent directly into SQL with the schema hidden from the LLM, making them the only viable architecture for autonomous AI.
How do I calculate my hidden token tax?
Multiply your schema token count (DDL serialized) by query volume by your input rate. Add output token cost. Multiply by your retry rate (typically 15-30% for raw RAG). A 50K-token schema at 100K queries/month on GPT-5.5 with 15% retries is approximately $50K/month or $600K/year before output costs.